学习链接:https://www.bilibili.com/video/BV1cr4y1671t?p=1&vd_source=510ec700814c4e5dc4c4fda8f06c10e8
狂神笔记:https://www.cnblogs.com/meditation5201314/p/14882992.html#redis五种基本数据类型
代码地址:https://gitee.com/empirefree/SpringBoot-summarize
可能是因为老师根据项目代码讲得,播放量才这么低,其实老师讲得很好的,完全可以不根据项目,自己建个小项目就单纯使用基本redis就行。在高级篇的时候搭建集群、canal这些都跳过了,先熟悉记录下,以后用到了再说
1. 基础篇
1.1 前言
狂神说--Redis学习笔记:https://www.cnblogs.com/meditation5201314/p/14882992.html
之前学完狂神讲的Redis,就自我感觉Redis学懂了,看到了尚硅谷发的Redis篇章,才发现自己只不过才学了点基础皮毛,实际高级内容、实战演练、原理都没有了解,果然还得是谦逊前进呀。
1.2 基本类型
1.2.1 String
setnx mykey 111
1.2.2 List
先进去的后出来,可看成栈,也可以做队列
1.2.3 set
值不可重复
1.2.4 Hash
key map
1.2.5 Zset
zset key score value
-- z1集合添加元素m2,分数为2
zadd z1 2 m2
--逆序从索引1开始输出2个元素
zrevrange z1 1 2 withscores
-- 查询z1中最大1000分最小0分,0:偏移量小于等于1000的3个元素
zrevrangeByScore z1 1000 0 withscores limit 0 3
-- 1:代表小于上次返回最大分数的3个元素(分数相同会存在重复返回)
zrevrangeByScore z1 上次返回最大分数 0 withscores limit 1 3
1.3 连接池
1.3.1 连接池类型
1.jedis
2.SpringDataRedis:提供了redisTemplate
1.3.2 RedisTempalte
1.3.2.1 基本概念
1.内部实现了jdk序列化
2.关于乱码:由于SpringMVC内置了jackson-Binder之类的序列化
2. 实战篇
2.1. 短信登录(略)
之前做过很多了,个人简单看了写原理就跳过了
2.2. 数据缓存
2.2.1 基本概念
2.2.1.1 缓存更新策略
- 采用删除缓存
- 如何保证缓存和数据库数据一致性
- 单体项目:缓存和数据库放到同一个事务中
- 分布式事务:TCC事务方案
- 先操作数据库or先删除缓存(这里一般指的是用户请求,商家后台更新数据的情况,当然,整个操作用事务或者分布式锁实现也行)
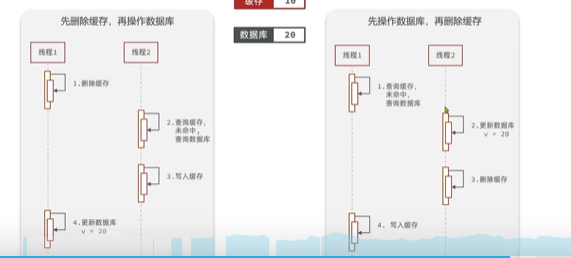
- 先删缓存,再操作数据库:A先删了,B在A未更新前读取写入缓存就会写入错误数据
- 先操作数据库,再操作缓存:A先操作数据库,B在A操作前读取数据库写入缓存也会读取到错误数据
- 延时双删(请求前删除,更新库后延时3~5秒,然后再删):之所以延时就是为了保证A删缓存操作数据库后未执行完,B一来又读取错误数据,然后发生脏读,就是为了保证B执行完,不过俺觉得意义不大,并发情况下还是得用事务或者分布式锁。简单了解下吧。
2.2.1.2 乐观锁/悲观锁
乐观锁 + 事务:能实现数据一致性,适合并发竞争小的情况(因为避免了数据频繁更新,采用的是CAS capare and swap自旋或版本号机制2种方式)
悲观锁 + 事务:每次读取前加锁
2.3 分布式锁
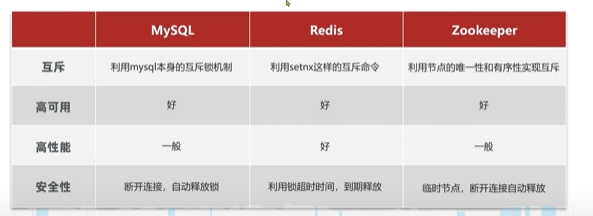
2.3.1 基本概念
分布式锁:分布式系统或集群模式下多线程之间互相可见并且互斥的锁
2.3.2 Redisson原理
2.3.2.0 分布式锁问题
基于setnx导致的分布式锁存在4个问题,而Redisson可以解决:
1. 不可重入:setx线程同一个线程可以重复获取同一把锁
1. 不可重试:setnt获取锁只尝试一次没有重试
1. 超时释放:setnx业务执行过长就会自动被删除了锁。(但是如果你不设置超时时间服务重启了的话那后续key值一直存在)
1. 主从一致性:setnx中,主设置了锁,宕机后从库变成主库,然后外部依然能获取锁
2. Redisson可重入锁
获取锁:
// 判断是否存在,能获取则获取
if (redis.call('exists', KEYS[1]) == 0)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
//根据threadid判断锁是不是自己的,获取锁次数加一,然后重置有效期
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
//否则返回锁获取失败
return redis.call('pttl', KEYS[1]);
释放锁:
//如果锁次数=0,则直接释放
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then return nil;
end;
//如果锁次数大于0,重置有效期,数减一然后返回。否则说明锁==0,可以直接删除发布订阅
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0)
then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]); //删除锁有订阅,供后续获取锁失败重试机制的线程使用
return 1;
end;
return nil;
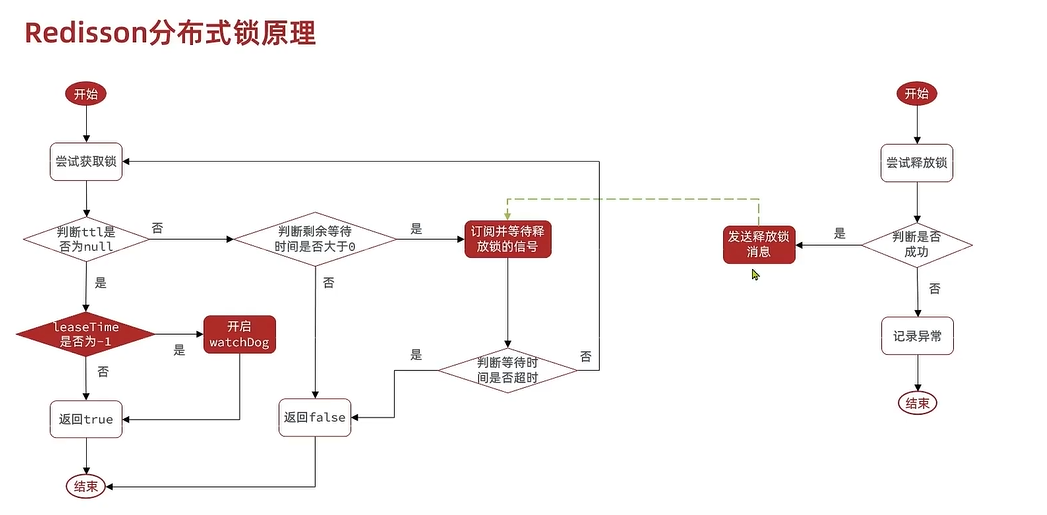
2.3.2.2 基本流程
//获取锁和释放锁的源码在这2个函数内容
// tryLock的3个参数: 获取锁等待时间(默认不等待) 释放锁时间, 时间单位
boolean isLock = rLock.tryLock(1, 10, TimeUnit.SECONDS);
rLock.unlock();
1. 加锁
1. 线程a先执行Lua脚本获取锁,获取成功(默认释放锁时间30秒)LUA脚本保证了同样线程id获取锁**可重入**
1. 若设置了锁释放时间,则不执行看门狗的锁刷新机制
2. 若没设置,则默认使用看门口锁释放时间30秒,执行看门狗刷新机制。
1. 递归每看门口时间 / 3 = 10秒刷新该线程id的有效期,保证了不会**超时就删锁**(因为默认30秒比10秒多)
2. 线程b执行Lua脚本失败,进行等待时间的订阅,然后重新获取锁,收到了订阅就按照等待时间是否剩余进行重试,没收到订阅时间到了就退出----保证了等待时间优先级最高,实现了**可重试**
2. 解锁
1. 释放订阅消息
2. 取消看门狗
Redisson分布式锁
1.可重入:利用hash 存储线程id与重入次数
2.可重试:利用发布订阅和循环等待实现锁重试(保证在等待时间内)
3.超时续约:利用watchDog,每隔一段时间(releaseTime / 3)重置
4.主从一致性:利用multiLock获取全部主节点锁才能成功(安置了多个主节点)
2.4 商品秒杀
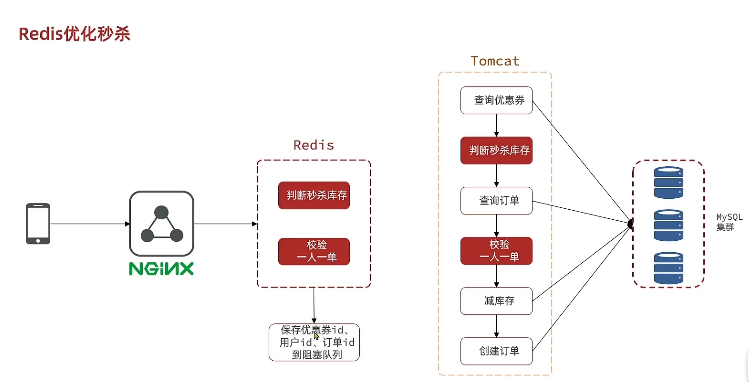
2.4.1 基本概念
1、Redis秒杀资格判断(Lua脚本保证原子性)。保存相关信息到阻塞队列
2、异步处理订单,扣减库存
2.4.2 秒杀资格--Lua脚本
-- 判断库存、判断用户是否下单,扣减库存
-- 获取参数的券id、用户id
local voucherId = ARGV[1]
local userId = ARGV[2]
local stockKey = 'seckill:stock:' .. voucherId
local orderKey = 'seckill:order:' .. voucherId
--
if(tonumber(redis.call('get', stockKey)) <= 0) then
return 1
end
if(redis.call("sismember", orderKey, userId) == 1) then
return 2
end
redis.call('incrby', stockKey, -1)
redis.call("sadd", orderKey, userId)
return 0
2.4.3 秒杀下单--阻塞队列异步实现
0、提前加载阻塞队列读取
1、Redis进行资格判断,将有资格的放入队列
2、线程池异步读取队列数据
(问题:阻塞队列是基于jvm内存来存储数据,服务宕机,高并发都会导致数据有问题)
2.4.4 Redis-消息队列
2.4.4.1 基本概念
存放消息的队列,双向链表,采用[LPush, BRPOP],或[Rpush, BLPOP]这些实现阻塞队列。
2.4.4.2 List消息队列
优点:
1. 基于Redis存储,不受限与JVM内存
2. 基于Redis数据持久化
缺点:
1. 无法避免消息丢失
2. 只能支持单消费者,无法让多个消费者使用
2.4.4.3 PubSub消息队列
-- 发布
publish order.q1.hello
--订阅
subscribe order.q1
--订阅: 支持通配符 *0个或多个 ?一个或多个 []满足内部条件
PSUBSCRIBE order.*
支持多生产,多消费
不支持数据持久化,无法避免消息丢失,消息易堆积
2.4.4.4 Stream消息队列
--添加stream队列,*表示由redis生成消息id
-- 队列一:类似于队列中存所有,但是阻塞读取却读取最新的,会存在覆盖
xadd s1 * k1 v1
--队列长度
xlen s1
--读取一条队列消息,从0开始读取
xread count 1 streams s1 0
--读取一条消息,从最新开始读取,永久等待
xread count 1 block 0 streams s1 $
- 消息永久存在,可回溯,可阻塞读取,可被多个消费者读取
- 由于每次读取最新的,会存在读取前消息漏读被覆盖的风险,和pubsub类型
消息分流:消息分给不同的组里面去
消息标识:类似于书签,标记读到了哪个消息,服务宕机重启后继续从标识读取(这样就避免了消息漏读情况)
消息确认:消息发送后会处于pending,发送完成后发送XACK确认,然后队列移除该消息
消息组模式
1、多个消费者争抢读取消息
2、可以阻塞读取,消息可回溯
3、没有消息漏读风险,消息可回溯
-- 0代表第一个消息,$代表最后一个消息
-- >表示下一个未消费的消息,"其他"表示已消费但未确认的消息. c1表示消费者名。
-- 队列二:发送失败没有被确认的消息进入pengding-list,类似于一个指针标记第一个位置,另一个指针不断往后走
--把stream流s1放入到g1中,从第一个开始
xgroup create s1 g1 0
xreadgroup group g1 c1 count 1 block 2000 streams s1 >
-- 根据消息id确认消息
xack s1 g1 1655878247936-0
--查看pending-list中所有时间段内的10条消息
xpending s1 g1 - + 10
--读取pending-list中未被确认的第一条消息
xreadgroup group g1 c1 count 1 block 2000 streams s1 0

实战
--MKSTREAM: 流不存在则自动创建
xgroup create stream.orders g1 0 MKSTREAM
--Lua脚本往队列丢数据。另起一个线程循环读取队列数据,并做ack确认
2.5 业务汇总
2.5.1 点赞功能
Redis根据文章id—key值增减,然后同步到库表中
2.5.2 关注功能
在每次关注用户后,利用follows-id作为key,采用set修改redis中关注情况,然后同步到库表中
2.5.3 Feed流
2.5.3.1 基本概念
Feed流:主动给用户推送用户感兴趣的东西
1.TimeLine:简单内容列表筛选
2.智能排序:智能算法过滤
2.5.3.2 实现方案
拉模式:用户拉取自己关注人信息,但是关注太多容易耗内存
推模式:博主每次发布都推送给自己关注的人,自己粉丝太多也不现实
推拉模式:人分成大V和普通人,粉丝分成活跃粉丝和僵尸粉,普通人就拉自己关注人的信息,普通人就推送自己信息给粉丝
2.5.3.3 滚动分页
由于传统id排序逆序时会导致数据不断刷新,所有原始limit offset不可取,采用redis中sortset,利用一个定点score来保证读取固定。redis中就采用时间来作为scoer
2.5.3.4 店铺距离
采用Geo举例导入计算
2.5.3.5 用户签到
由于在库表中存每个用户每日签到数据量太大,所以可以采用bit位来存储,只要把时间作为key值,也极大方便后续查询统计日期
2.5.3.6 PV/UV
统计PV,UV这些可以使用hyperloglog允许些许误差。
3.高级篇
3.1. 分布式缓存
3.1.1 RDB
RDB:默认save是主进程保存,bgsave是fork一个子进程进行保存
3.1.2 AOF
AOF: 记录指令,然后替换上个aof文件
3.1.3 进程缓存
分布式缓存:访问缓存有网络开销,集群可以共享,缓存数据量大
进程缓存:访问本地内存速度更快,但容量有限
3.1.4 Canal
canal就是模拟salve把Redis-master的binlog读取到slave运行。
每当数据库数据修改,canal就监听然后修改数据到数据库中
3.2. 实践设计
3.2.1 基本设计
1.key 的设计 [业务名称]:[数据名]:[id]
2. 删除bigkey:另起一个线程异步删除值
2. **建议使用hash存储**,key可以使用数据量 %100这种,field使用key,value(内存占用非常少,因为使用zipList,默认不要超过key值500)
2. 批处理入库数据:sadd,mset入库快
2. Redis主从能达到上w级别的QPS,尽量不要搭建集群。
3.2.2 服务器优化
1.尽量不要开启持久化功能
2.建议开启AOF持久化
4.原理篇
4.1 数据结构
4.1.1 基本概念
Redis:底层是C写的
4.1.2 动态字符串SDS
Redis中key, value都是采用单个或多个字符串SDS来存储,SDS本质是个结构体,分成字符串头(记录字符串长度)、体(存储真实数据)
4.1.3 IntSet
int的set:整数唯一数组,内部采用二分查询查询
4.1.4 Dict
由3部分组成:dictHashTable哈希表,dictEntry哈希结点,dict字典
哈希表构成就是dicEntry这种key, value值
Dict字典包含2个哈希表,用于扩容和收缩,底层就是数组+链表来解决hash冲突
(总结dict底层就是hash表,是有数组和单向链表来实现,其中保存的就是key, value的Entry键值对,用指针这种来SDS对象)
4.1.5 ZipList
压缩列表是由连续内存空间的列表,没有使用指针链接,而是记录了上个节点寻址。因为如果采用dict这种指针选择,内存碎片太多,指针字节占用太多。
4.1.6 QuickList
节点为zipList的双向链表,兼容了zipList申请连续过多的内存空间,与链表指针消耗过多内存空间的优点。
4.1.7 SkipList跳表 *
跳表是链表,元素按升序排序,然后不断在元素之间往上建立指针,和MySQL索引建立类似,方便后续查找,CURD效率与红黑树一样log(n)
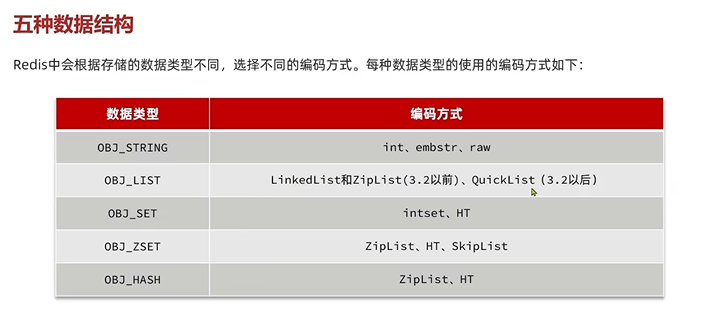
4.1.8 RedisObject
RedisObject包含了5中数据类型,然后5中下面编码方式就是上面跳表,zipList,quickList这些。(typerloglog,bitmap,bitmap底层也就是string,zset)
4.2 网络模型
4.2.1 IO多路复用
利用单线程同时监听多个服务。分为select,poll, epoll。
select每次都要拷贝监听服务的FD从用户到内核耗时
epoll就把就绪的监听服务FD保存下来,然后每次就不用遍历所有FD
4.2.2 模型比较
目前还是IO多路复用用的比较多

4.2.3 Redis网络模型
Redis6.0之后引入了多线程,之前都是单线程
4.2.4 Redis策略
Redis中采用dict记录了key的TTL时间
4.2.4.1 过期-删除策略
1. 惰性清理:每次查找key,过期就删除
1. 定期清理:定期抽取key,过期就删除
4.2.4.2 淘汰策略
8种策略:默认不淘汰任何key,内存满了不允许写入行数据
