一、Map集合框架
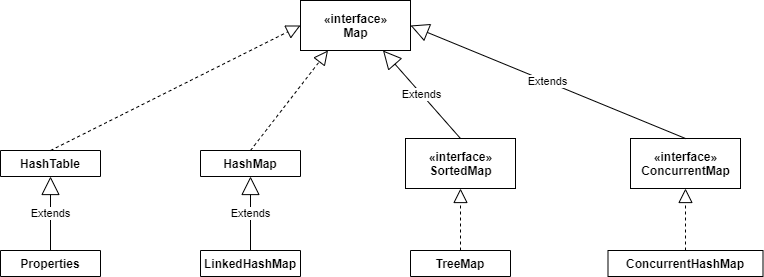
一、HashMap
JDK1.7和JDK1.8,区别还是蛮大的。
JDK1.8使用的是数组+链表+红黑树
比如:
Map<String,Object> map = new HashMap<String,Object>();
然后我们put进去一个值。
map.put("name","caesar");
然后它是怎末操作的呢。
首先说,如果不指定数组的大小,默认数组大小的长度是16位。
然后算出name的hashCode,通过HashCode计算出,该数据因该位于数组中的位置。

先进行异或操作,使hashCode更加的随机。
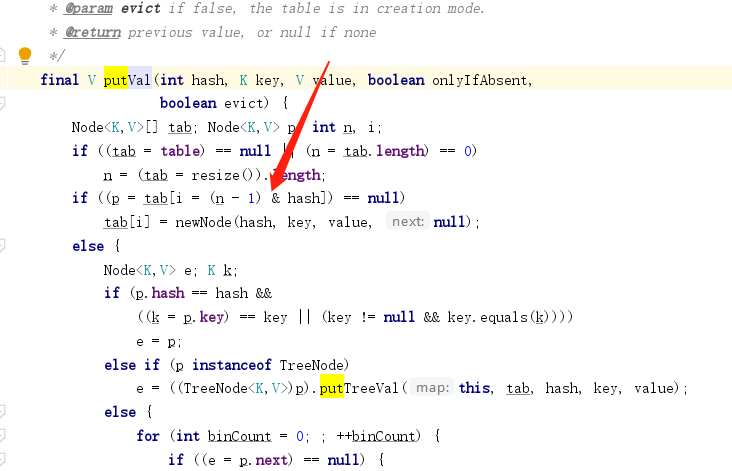
然后使用与操作,来获取数组的位置,然后判断是否重复,不重复直接添加,重复就判断是链表还是红黑树,然后使用不同的方式来进行添加操作。
有如下几个疑问:
1、为什么要使用与运算来计算数组的位置,为什么不适用模运算呢?
很显然,与运算快呀,模运算要进行三步操作:除法,乘法,减法
2、为什么数组的长度最好为2的倍数如果不是2的倍数,要改为距离最近的2的倍数,算法如下:

假如说数组长度为16,那么与的树为15,也就是1111,这时候是没有空间浪费的而,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
3、如果hashCode不同,就不存在hash碰撞吗?
当然不是啦,碰撞是因为,hashCode和length-1与完的值,是有可能形相同的。
4、hashmap的resize怎样改善效率
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
5、为什么不一开始就使用红黑树,要等长度到了8才使用?
- HashMap 解决 hash 冲突的时候,先用链表,再转红黑树,是为了时间和空间的平衡。
- TreeNodes 占用的空间大小大约是普通 Nodes 的两倍,只有在容器中包含足够的节点保证使用才用它,在节点数比较小的时候,对于红黑树来说,内存上的劣势会超过查找等操作的优势,使用链表更加好。
- 节点数比较多的时候,综合考虑时间和空间,红黑树比链表要好
JDK1.7的数据结构是数组+链表。不多说。
其实红黑树在数组量小的时候是不会用到了,据统计使用到红黑树的概率是千万分之一。
二、LinkedHashMap

实际和HashMap类似,就是多了两个指针而已,可以维护插入顺序,但是插入时较慢。
三、TreeMap
TreeMap使用的数据结构是红黑树,能到的查询效率为logn,主要是可以根据自定义的排序方法进行排序,主要还是排序时使用。
四、HashTable
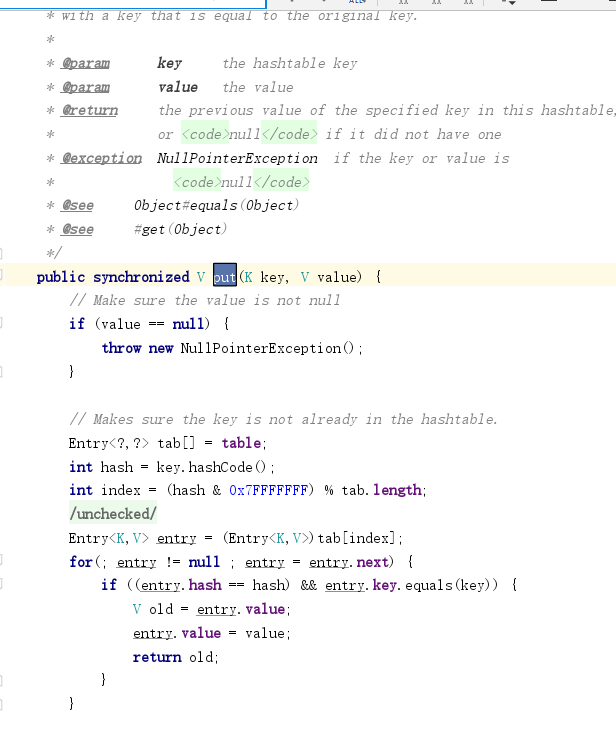
synchronized来实现锁,实现线程安全,效率低。
五、ConcurrentHashMap
这个线程安全的Map,对性能进行了优化。
JDK1.7和1.8也是有较大的区别。
先说1.7吧
1.7抛弃了全synchronized,效率太低,使用分段锁(实际结构为:数组+数组+链表)
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
主要结构:
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
Segment 继承于 ReentrantLock,调用,Lock()+UnLock()的方法,来进行加锁,解锁,
1、我认为最妙的在于,它这个Segment通过HashCode来进行的数组定位。
hash >>> segmentShift) & segmentMask
segmentShift和segmentMask。这两个全局变量在定位segment时的哈希算法里需要使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与hash运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的,后面的测试中我们可以看到这点。segmentMask是哈希运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1。因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1。
segmentMask实际就是length-1,不多说
无符号右移,是前面的各项全部为0,比如segment数组有16位,2的四次方,那么hashCode32位,右移动(32-4),也就是28位,之后,就剩下了4位,正好和segmentMask取与,高位运算,实际上直接与也可以,但是出现hash冲突的概率加大。
2、还有就是get不加锁:
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空的才会加锁重读,我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get方法里将要使用的共享变量都定义成volatile,如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的值,是根据java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatile替换锁的经典应用场景。
然后聊聊JDK1.8的升级版本
结构还是数组+链表+红黑树
1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。因为synchronized实际是有锁升级过程的,可以看我的另一篇博客。
https://www.cnblogs.com/mcjhcnblogs/p/14226505.html
其中一些不太懂得部分,也参考了其他大牛的博客,讲的比较清楚
参考博客:
HashMap中相关问题的博客:
ConcurrentHashMap的参考博客: