sqlserver 中为什么要有更新锁:
http://www.cnblogs.com/woodytu/p/4678787.html
https://www.sqlpassion.at/archive/2014/07/28/why-do-we-need-update-locks-in-sql-server/
还有我们各种更新锁的使用:http://blog.csdn.net/u010523770/article/details/53208817
关于锁的各种描述:
一个更新锁只与一个共享锁兼容,但不与另一个更新或排它锁兼容。因此死锁情形可以被避免,应为2个更新查询计划不可能同时并发运行。在查询的第1阶段,第2个查询会一直等到获得更新锁。
连个update 不能同时进行;
独占锁、共享锁、更新锁,乐观锁、悲观锁
(1)从数据库系统的角度来看,锁分为以下三种类型:
- 独占锁(Exclusive Lock)
独占锁锁定的资源只允许进行锁定操作的程序使用,其它任何对它的操作均不会被接受。执行数据更新命令,即INSERT、 UPDATE 或DELETE 命令时,SQL Server 会自动使用独占锁。但当对象上有其它锁存在时,无法对其加独占锁。独占锁一直到事务结束才能被释放。
- 共享锁(Shared Lock)
共享锁锁定的资源可以被其它用户读取,但其它用户不能修改它。在SELECT 命令执行时,SQL Server 通常会对对象进行共享锁锁定。通常加共享锁的数据页被读取完毕后,共享锁就会立即被释放。
- 更新锁(Update Lock)
更新锁是为了防止死锁而设立的。当SQL Server 准备更新数据时,它首先对数据对象作更新锁锁定,这样数据将不能被修改,但可以读取。等到SQL Server 确定要进行更新数据操作时,它会自动将更新锁换为独占锁。但当对象上有其它锁存在时,无法对其作更新锁锁定。
(2)从程序员的角度看,锁分为以下两种类型:
- 悲观锁(Pessimistic Lock)
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
- 乐观锁(Optimistic Lock)
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。
而乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
文字来源:
http://blog.csdn.net/jujulia_318/article/details/27340779
更新丢失的描述:
http://blog.csdn.net/z69183787/article/details/52213670
悲观锁和乐观锁的解决方案:
https://wenku.baidu.com/view/52d0c2bdc77da26925c5b01f.html
这里同样有一个示例图:
http://www.cnblogs.com/shanshanlaichi/p/6556767.html
关于锁粒度的一种说法:
http://www.cnblogs.com/freeton/articles/3819934.html
悲观锁和乐观锁
悲观锁一定成功,但在并发量特别大的时候会造成很长堵塞甚至超时,仅适合小并发的情况。
乐观锁不一定每次都修改成功,但能充分利用系统的并发处理机制,在大并发量的时候效率要高很多
关于锁粒度的一关系示意图:
锁的粒度
锁是加在数据库对象上的。而数据库对象是有粒度的,比如同样是1这个单位,1行,1页,1个B树,1张表所含的数据完全不是一个粒度的。因此,所谓锁的粒度,是锁所在资源的粒度。所在资源的信息也就是前面图3中以Resource开头的信息。
对于查询本身来说,并不关心锁的问题。就像你开车并不关心哪个路口该有红绿灯一样。锁的粒度和锁的类型都是由SQL Server进行控制的(当然你也可以使用锁提示,但不推荐)。锁会给数据库带来阻塞,因此越大粒度的锁造成更多的阻塞,
但由于大粒度的锁需要更少的锁,因此会提升性能。
而小粒度的锁由于锁定更少资源,会减少阻塞,
因此提高了并发,
但同时大量的锁也会造成性能的下降
这里测试一种悲观锁的解决方式;
前提:
开两个窗口(session)
同时执行;
两边都必须加上更新锁,如果一边没有加上,将导致票count更新有误
USE [luck] GO /****** Object: Table [dbo].[tb1] Script Date: 2017/8/16 9:58:19 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[tb1]( [id] [int] NOT NULL, [a] [int] NULL, [Count] [int] NULL, CONSTRAINT [PK_tb1] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
两边窗口同时执行
begin tran declare @count int select @count=[Count] from tb1 with(updlock) where id=1 waitfor delay '000:00:20' update tb1 set [Count]= @count-1 commit
SQL Server 事务锁定和行版本控制指南
https://technet.microsoft.com/library/jj856598.aspx
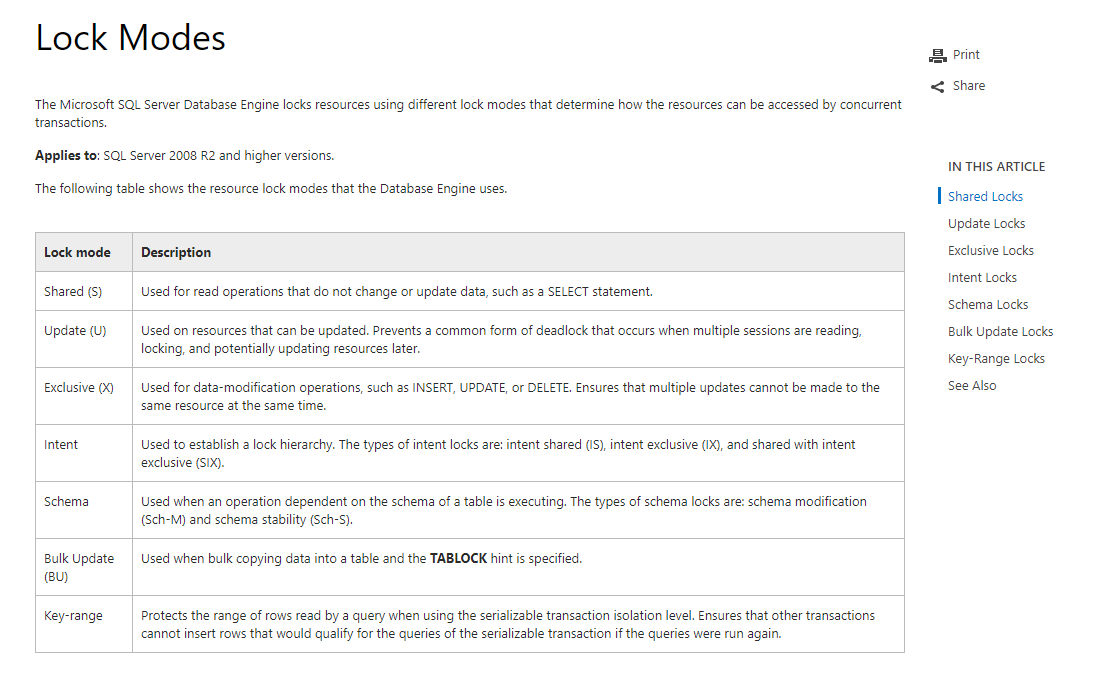
sqlserver 锁模式:https://technet.microsoft.com/en-us/library/ms175519(v=sql.105).aspx
http://www.sqlteam.com/article/introduction-to-locking-in-sql-server
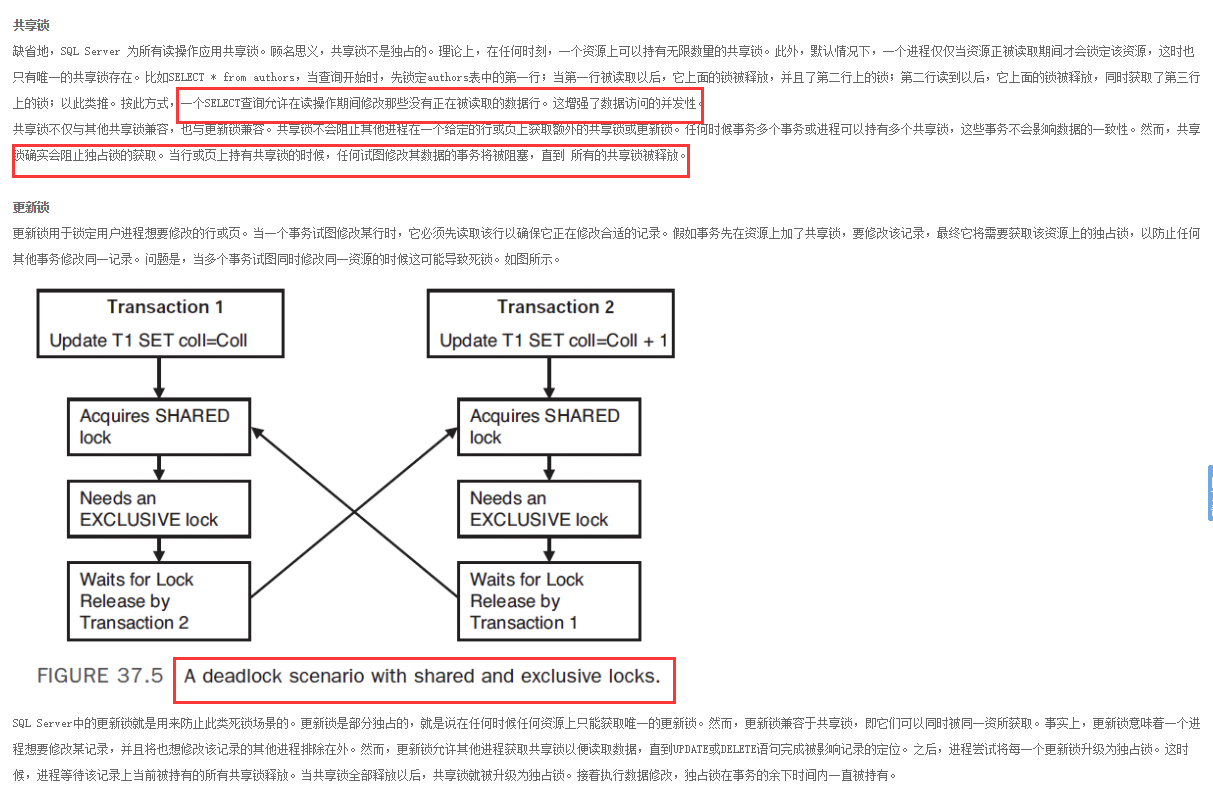
更新锁是如何解决死锁的;(来源:http://blog.itpub.net/13651903/viewspace-1091664/)
sqlserver 避免死锁:
https://msdn.microsoft.com/en-us/library/aa260979(v=vs.60).aspx
这里有两种常见的跟新丢失;
