在执行OSR或方法编译时,调用AdvancedThresholdPolicy::common()函数决定编译策略,这样才能在SimpleThresholdPolicy::submit_compile()函数提交编译任务。common()函数的实现如下:
CompLevel AdvancedThresholdPolicy::common(
Predicate p,
Method* method,
CompLevel cur_level,
// 当为OSR编译时,如下参数为true,方法编译时,为false
bool disable_feedback
) {
CompLevel next_level = cur_level;
int i = method->invocation_count();
int b = method->backedge_count();
// 当一个方法足够简单时,使用C1编译器就能达到C2的效果
if (is_trivial(method)) {
next_level = CompLevel_simple;
} else {
switch(cur_level) {
case CompLevel_none:
// 当前的编译级次为ComLevel_none,可能会直接到CompLevel_full_optimization级别,如果Metod::_method_data
// 不为NULL并且已经采集了足够信息的话
if (common(p, method, CompLevel_full_profile, disable_feedback) == CompLevel_full_optimization) {
next_level = CompLevel_full_optimization;
}
// 调用AdvancedThresholdPolicy::call_predicate()或AdvancedThresholdPolicy::loop_predicate()函数,
// 函数如果返回true,表示已经充分收集了profile信息,可直接采用第3层的CompLevel_full_profile编译
else if ((this->*p)(i, b, cur_level)) {
// 在 C2 忙碌的情况下,方法会被CompLevel_limited_profile的C1编译,然后再被
// CompLevel_full_profile的C1编译,目的是减少方法在CompLevel_full_profile的执行时间
// Tier3DelayOn的英文解释为:If C2 queue size grows over this amount per compiler thread
// stop compiling at tier 3 and start compiling at tier 2
if (!disable_feedback && CompileBroker::queue_size(CompLevel_full_optimization) >
Tier3DelayOn * compiler_count(CompLevel_full_optimization)) {
next_level = CompLevel_limited_profile;
} else { // C2如果不忙碌,直接使用CompLevel_full_profile的C1编译即可
next_level = CompLevel_full_profile;
}
}
break;
case CompLevel_limited_profile:
if (is_method_profiled(method)) {
// 特殊情况下,可能解释执行过程中已经采集了足够的运行时信息,直接采用CompLevel_full_optimization的C2编译
next_level = CompLevel_full_optimization;
} else {
MethodData* mdo = method->method_data();
if (mdo != NULL) {
if (mdo->would_profile()) {
// 如果C2的负载不高时,采用CompLevel_full_profile进行信息的采集
// Tier3DelayOff的英文解释为:If C2 queue size is less than this amount per compiler thread
// allow methods compiled at tier 2 transition to tier 3
if (disable_feedback || (CompileBroker::queue_size(CompLevel_full_optimization) <=
Tier3DelayOff * compiler_count(CompLevel_full_optimization) &&
(this->*p)(i, b, cur_level))) {
next_level = CompLevel_full_profile;
}
} else {
next_level = CompLevel_full_optimization;
}
}
}
break;
case CompLevel_full_profile:
{
MethodData* mdo = method->method_data();
if (mdo != NULL) {
if (mdo->would_profile()) {
int mdo_i = mdo->invocation_count_delta();
int mdo_b = mdo->backedge_count_delta();
if ((this->*p)(mdo_i, mdo_b, cur_level)) {
next_level = CompLevel_full_optimization;
}
} else {
next_level = CompLevel_full_optimization;
}
}
}
break;
}
}
return MIN2(next_level, (CompLevel)TieredStopAtLevel);
}
通过如上函数,我们能够看到HotSpot VM对OSR和方法的编译策略,编译层级从一个层级转换到另外一个层级参考的主要指标有:方法统计的运行时信息和编译器线程的负载情况。下面我们详细介绍一下编译策略,首先介绍一下编译层级。AdvancedThresholdPolicy支持5个级别的编译,这5个级别通过CompLevel枚举类定义,如下:
源代码位置:openjdk/hotspot/src/share/vm/utilites/globalDefinitions.hpp
enum CompLevel {
CompLevel_any = -1,
CompLevel_all = -1,
// level 0:解释执行
CompLevel_none = 0,
// level 1:执行不带profiling的C1代码
CompLevel_simple = 1,
// level 2:执行仅带方法调用次数以及循环回边执行次数profiling的C1代码
CompLevel_limited_profile = 2,
// level 3:执行带所有profiling的C1代码
CompLevel_full_profile = 3,
// level 4:执行C2代码
CompLevel_full_optimization = 4,
// 在分层编译的情况下仅使用C2进行编译,值为4,也就是level 4
CompLevel_highest_tier = CompLevel_full_optimization,
CompLevel_initial_compile = CompLevel_full_profile
};
方法和OSR执行的编译策略路径如下图所示。
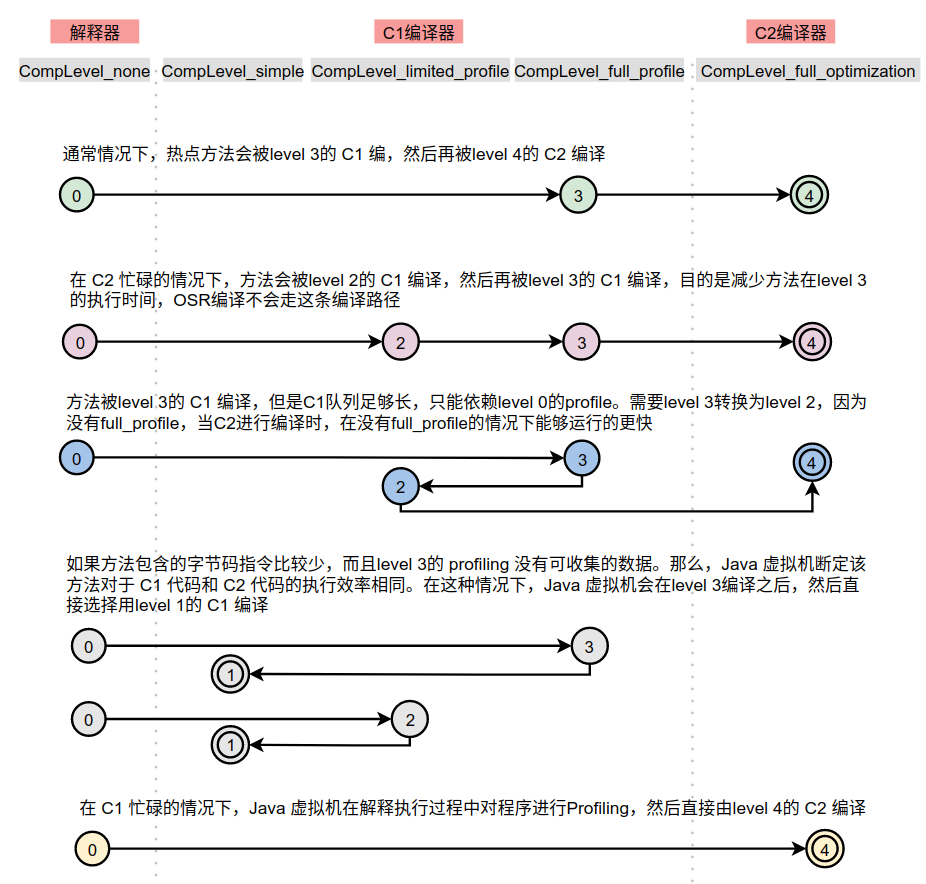
其中0、2、3这三个层级下都会周期性的通知AdvancedThresholdPolicy某个函数的方法调用计数(invocation counters)和循环调用计数(backedge counters),不同级别下通知的频率不同。这些通知用来决定如何调整编译层级,所以最终会形成不同的编译路径。
在 5 个层次的执行状态中,CompLevel_simple和CompLevel_full_optimization为终止状态。当一个方法被终止状态编译后,如果编译后的代码没有失效,那么Java虚拟机是不会再次发出对该方法的编译请求的。
下面我们从另外一个角度解读上图中的编译路径。
1、在CompLevel_none下不执行任何编译,仍然是解释执行
当某个方法刚开始执行时,通常会解释执行。
当C1和C2的编译任务队列的长度足够短,也可在CompLevel_none下开启profile信息收集。编译队列通过优先级队列实现,每个添加到编译任务队列的方法都会周期的计算其在单位时间内增加的调用次数,每次从编译队列中获取任务时,都选择单位时间内调用次数最大的一个。基于此,我们也可以将那些编译完成后不再使用,调用次数不再增加的方法从编译任务队列中移除。
如果当前的编译层级为CompLevel_none,可能会变为CompLevel_limited_profile、CompLevel_full_profile、CompLevel_full_optimization编译层级。
2、CompLevel_none调整为CompLevel_limited_profile或CompLevel_full_profile
AdvancedThresholdPolicy会综合如下两个因素和调用计数将编译级别调整为CompLevel_limited_profile或CompLevel_full_profile:
- C2编译任务队列的长度决定了下一个编译级别。据观察,CompLevel_limited_profile级别下的编译比CompLevel_full_profile级别下的编译快30%,因此我们应该在只有已经收集了充分的profile信息后才采用CompLevel_full_profile编译,从而尽可能缩短CompLevel_full_profile级别下编译的耗时。当C2的编译任务队列太长的时候,如果选择CompLevel_full_profile则编译会被卡住直到C2将之前的编译任务处理完成,这时如果选择CompLevel_limited_profile编译则很快完成编译。当C2的编译压力逐步减小,就可以重新在CompLevel_full_profile下编译并且开始收集profile信息;
- 根据C1编译任务队列的长度动态的调整阈值,在编译器过载时,将打算编译但是不再被调用的方法从编译队列中移除。
3、CompLevel_full_profile调整为CompLevel_limited_profile、CompLevel_simple、CompLevel_full_optimization
当CompLevel_full_profile下profile信息收集完成后就会转换成CompLevel_full_optimization了,可以根据C2编译任务队列的长度来动态调整转换的阈值。当经过C1编译完成后,基于方法的代码块的数量,循环的数量等信息可以判断一个方法是否是琐碎(trivial)的,这类方法在C2编译下会产生和C1编译一样的代码,因此这时会用CompLevel_simple的编译代替CompLevel_full_optimization的编译。
4、CompLevel_full_profile调整为CompLevel_full_optimization
注意CompLevel_full_profile并不是终态,一般到了这个层次的编译任务最终都需要C2编译器承担CompLevel_full_optimization层级的编译任务,所以我们才会看到,当编译层级由其它的调整为CompLevel_full_profile时,通常会判断C2的负载能力。
前面介绍过, 编译层级从一个层级转换到另外一个层级参考的主要指标还需要参考运行时收集的信息,OSR编译主要是调用AdvancedThresholdPolicy::loop_predicate()函数,如下:
bool AdvancedThresholdPolicy::loop_predicate(int i, int b, CompLevel cur_level) {
switch(cur_level) {
case CompLevel_none:
case CompLevel_limited_profile: {
// Tier3LoadFeedback的值默认为5,Tier 3 thresholds will increase twofold
// when C1 queue size reaches this amount per compiler thread
double k = threshold_scale(CompLevel_full_profile, Tier3LoadFeedback);
return loop_predicate_helper<CompLevel_none>(i, b, k);
}
case CompLevel_full_profile: {
// Tier4LoadFeedback的值默认为3,
double k = threshold_scale(CompLevel_full_optimization, Tier4LoadFeedback);
return loop_predicate_helper<CompLevel_full_profile>(i, b, k);
}
default:
return true;
}
}
调用的threshold_scale()函数的实现如下:
double AdvancedThresholdPolicy::threshold_scale(CompLevel level, int feedback_k) {
double queue_size = CompileBroker::queue_size(level); // 编译队列中编译任务的数量
int comp_count = compiler_count(level); // 编译器线程数量
double k = queue_size / (feedback_k * comp_count) + 1;
// 获取CodeCache的剩余可用空间,如果不足,则增加C1编译的阈值,从而为C2编译保留足够的空间
if ((TieredStopAtLevel == CompLevel_full_optimization) && (level != CompLevel_full_optimization)) {
double current_reverse_free_ratio = CodeCache::reverse_free_ratio();
if (current_reverse_free_ratio > _increase_threshold_at_ratio) {
k *= exp(current_reverse_free_ratio - _increase_threshold_at_ratio);
}
}
return k;
}
当队列的任务越多时,scale的值越大;当编译的线程数量越多时,值越小。
调用的loop_predicate_helper()函数的实现如下:
template<CompLevel level>
bool SimpleThresholdPolicy::loop_predicate_helper(int i, int b, double scale) {
switch(level) {
case CompLevel_none:
case CompLevel_limited_profile:
// 回边计数>60000*2
return b > Tier3BackEdgeThreshold * scale;
case CompLevel_full_profile:
// 回边计数>40000*2
return b > Tier4BackEdgeThreshold * scale;
}
return true;
}
scale越小时,满足如上函数的判断条件需要的回边计数值就越小,如上函数在返回true后,通常在编译策略中会将编译层次调整为更高的级别。scale的值是通过调用threshold_scale()函数决定的,也就是队列中任务越多时,如上函数返回false的机率越大,编译线程数量越多时,如上函数返回true的机率越大。这样就能很好的控制编译任务的数量。
编译方法时,调用的是call_predicate()函数,此函数的实现如下:
bool AdvancedThresholdPolicy::call_predicate(int i, int b, CompLevel cur_level) {
switch(cur_level) {
case CompLevel_none:
case CompLevel_limited_profile: {
double k = threshold_scale(CompLevel_full_profile, Tier3LoadFeedback);
return call_predicate_helper<CompLevel_none>(i, b, k);
}
case CompLevel_full_profile: {
double k = threshold_scale(CompLevel_full_optimization, Tier4LoadFeedback);
return call_predicate_helper<CompLevel_full_profile>(i, b, k);
}
default:
return true;
}
}
template<CompLevel level>
bool SimpleThresholdPolicy::call_predicate_helper(int i, int b, double scale) {
switch(level) {
case CompLevel_none:
case CompLevel_limited_profile:
return
// 方法调用>200 * 2
(i > Tier3InvocationThreshold * scale) ||
// ( 方法调用>100*2 && (方法调用+回边计数)>2000*2 )
(i > Tier3MinInvocationThreshold * scale && i + b > Tier3CompileThreshold * scale);
case CompLevel_full_profile:
return
// 方法调用>5000*2
(i > Tier4InvocationThreshold * scale) ||
// ( 方法调用>600*2 && (方法调用+回边计数)>15000*2 )
(i > Tier4MinInvocationThreshold * scale && i + b > Tier4CompileThreshold * scale);
}
return true;
}
实现的逻辑与回边的判断差不多,只不过方法编译时,还会考虑到回边计数。
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流