对于Java中的native方法来说,实际上调用的是C/C++实现的本地函数,由于可能会在Java解释执行过程中调用native方法,或在本地函数的实现过程中调用Java方法,所以当两者相互调用时,必须要遵守调用约定,同时要保证在被调用方法执行完成后,调用者的方法能继续向下执行。
在HotSpot VM中,Java方法调用native方法会有2个入口例程,一个为解释执行的入口例程,一个为“编译”执行的入口例程。所谓“编译”执行其实是如果一个native方法在解释模式被调用到了CompileThreshold次数之后,HotSpot VM会为该方法专门生成一个Native wrapper,将其方法属性、参数迁移之类的信息都固化进去,相比解释执行开销会小一些。Native wrapper生成好之后会保存到方法的Method::_from_compiled_entry属性中。
这一篇我们先介绍为解释执行生成的例程。
1、InterpreterGenerator::generate_native_entry()函数生成解释执行的入口例程
之前介绍过调用InterpreterGenerator::generate_normal_entry()函数生成Java方法解释执行的入口,而调用InterpreterGenerator::generate_native_entry()函数会生成native方法的入口,最终会将生成的例程入口保存到Interpreter::_entry_table一维数组中,通过MethodKind来从一维数组中获取对应方法类型的例程。
InterpreterGenerator::generate_native_entry()函数生成的例程的逻辑比较多,我们分几部分来解读。
(1)生成native方法的栈帧
下面详细介绍生成native方法栈帧的生成过程。
// 在调用此例程时,各个寄存器中的值如下: // rbx: Method* // r13: sender sp 0x00007fffe1014c00: mov 0x10(%rbx),%rcx // 将ConstMethod*存储到%rcx中 0x00007fffe1014c04: movzwl 0x2a(%rcx),%ecx // 将参数的大小存储到%ecx中 0x00007fffe1014c08: pop %rax // 将返回地址弹出到%rax中 // rbx: Method* // rcx: size of parameters 通过上面的操作,将参数的大小存储到rcx寄存器中,如果是int、byte等为1个slot,而long和double为2个slot,所以这里指的是需要slot的大小 // r13: sender sp // for natives the size of locals is zero // compute beginning of parameters (r14) // 根据%rsp和参数大小计算参数的地址 // %r14指向栈顶第一个参数的位置 0x00007fffe1014c09: lea -0x8(%rsp,%rcx,8),%r14 // 为本地调用初始化两个8字节的数据,其中一个保存result_handler,一个保存oop temp 0x00007fffe1014c0e: pushq $0x0 // oop temp对于静态的native方法来说,保存的可能是mirror, // 或者native方法调用结果为对象时,保存这个对象 0x00007fffe1014c13: pushq $0x0
需要注意,在InterpreterGenerator::generate_native_entry()中调用generate_fixed_frame()方法之前,会开辟2个8字节的空间,分别用来存放result_handler和oop temp,而在 InterpreterGenerator::generate_normal_entry()函数中调用时不会开辟这2个8字节的空间。
如上汇编执行完成后的栈图如下所示。

调用generate_fixed_frame()函数生成的汇编如下:
0x00007fffe1014c18: push %rax 0x00007fffe1014c19: push %rbp 0x00007fffe1014c1a: mov %rsp,%rbp 0x00007fffe1014c1d: push %r13 0x00007fffe1014c1f: pushq $0x0 0x00007fffe1014c24: mov 0x10(%rbx),%r13 0x00007fffe1014c28: lea 0x30(%r13),%r13 0x00007fffe1014c2c: push %rbx 0x00007fffe1014c2d: mov 0x18(%rbx),%rdx 0x00007fffe1014c31: test %rdx,%rdx 0x00007fffe1014c34: je 0x00007fffe1014c41 0x00007fffe1014c3a: add $0x90,%rdx 0x00007fffe1014c41: push %rdx 0x00007fffe1014c42: mov 0x10(%rbx),%rdx 0x00007fffe1014c46: mov 0x8(%rdx),%rdx 0x00007fffe1014c4a: mov 0x18(%rdx),%rdx 0x00007fffe1014c4e: push %rdx 0x00007fffe1014c4f: push %r14 0x00007fffe1014c51: pushq $0x0 0x00007fffe1014c56: pushq $0x0 0x00007fffe1014c5b: mov %rsp,(%rsp)
如上汇编代码在之前介绍“为Java方法创建新栈帧”时详细介绍过,逻辑基本类似,这里不再过多介绍。
执行完如上汇编后的栈帧状态如下:
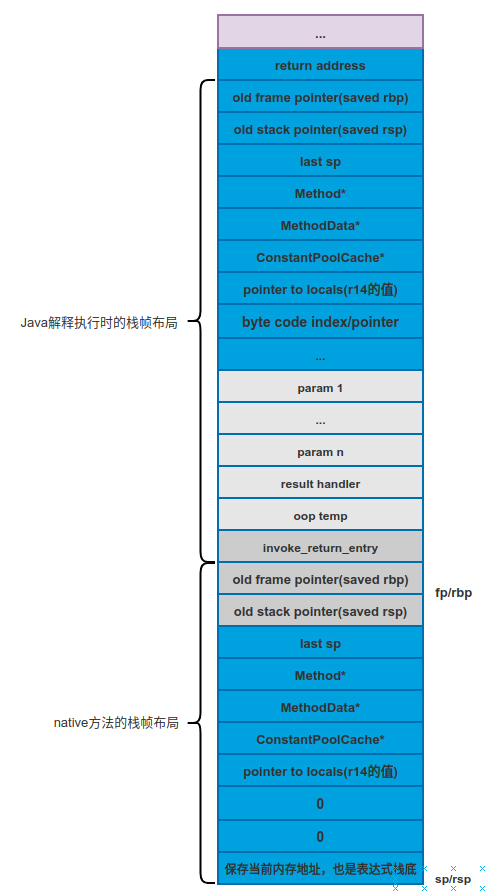
接下来生成的汇编片段如下(可以添加虚拟机参数-XX:-UseStackBanging和-XX:-ProfileInterpreter,这样暂时不生成栈检查和统计相关的汇编代码,我们只关注最主要的逻辑):
// 将JavaThread::do_unlock_if_synchronized变量设置为true 0x00007fffe1014c5f: movb $0x1,0x2ad(%r15) // ... 计数等操作 // 将JavaThread::do_unlock_if_synchronized变量设置为false 0x00007fffe1014d48: movb $0x0,0x2ad(%r15) // 省略调用lock_method()函数生成的汇编代码,如果是同步方法, // 则还会调用lock_method()函数生成相关的汇编代码 // 省略调用__ notify_method_entry()函数生成的汇编代码, // 不会对当前栈帧的布局产生任何影响 // 从栈帧中取出Method*存储到%rbx中 0x00007fffe1014d87: mov -0x18(%rbp),%rbx // 获取ConstMethod*存储到%r11中 0x00007fffe1014d8b: mov 0x10(%rbx),%r11 // 将方法参数的大小放到%r11d中 0x00007fffe1014d8f: movzwl 0x2a(%r11),%r11d // 将%r11d中的内容左移3位,也就是算出方法参数需要占用的字节数 0x00007fffe1014d94: shl $0x3,%r11d // 更新%rsp的值,为方法参数开辟存储参数的空间 0x00007fffe1014d98: sub %r11,%rsp // 对linux系统来说不起作用 0x00007fffe1014d9b: sub $0x0,%rsp // 必须是16字节边界(see amd64 ABI) 0x00007fffe1014d9f: and $0xfffffffffffffff0,%rsp
System V / AMD64 ABI要求16字节堆栈对齐。详细信息可以参考其它文章。
(2)连接Method::signature_handler并调用
下面继续看汇编的逻辑:
// 将Method::signature_handler存储到%r11中 0x00007fffe1014da3: mov 0x68(%rbx),%r11 // 如果Method::signature_handler非空,则跳转到L1 0x00007fffe1014da7: test %r11,%r11 0x00007fffe1014daa: jne 0x00007fffe1014e40 // 执行到这里,说明Method::signature_handler属性的值为空, // 需要调用InterpreterRuntime::prepare_native_call()函数 // 确保native方法已经绑定且安装了方法签名解析代码 // 调用__ call_VM()函数生成如下例程 0x00007fffe1014db0: callq 0x00007fffe1014dba 0x00007fffe1014db5: jmpq 0x00007fffe1014e38 0x00007fffe1014dba: mov %rbx,%rsi 0x00007fffe1014dbd: lea 0x8(%rsp),%rax 0x00007fffe1014dc2: mov %r13,-0x38(%rbp) 0x00007fffe1014dc6: mov %r15,%rdi 0x00007fffe1014dc9: mov %rbp,0x200(%r15) 0x00007fffe1014dd0: mov %rax,0x1f0(%r15) 0x00007fffe1014dd7: test $0xf,%esp 0x00007fffe1014ddd: je 0x00007fffe1014df5 0x00007fffe1014de3: sub $0x8,%rsp 0x00007fffe1014de7: callq 0x00007ffff66af6aa 0x00007fffe1014dec: add $0x8,%rsp 0x00007fffe1014df0: jmpq 0x00007fffe1014dfa 0x00007fffe1014df5: callq 0x00007ffff66af6aa 0x00007fffe1014dfa: movabs $0x0,%r10 0x00007fffe1014e04: mov %r10,0x1f0(%r15) 0x00007fffe1014e0b: movabs $0x0,%r10 0x00007fffe1014e15: mov %r10,0x200(%r15) 0x00007fffe1014e1c: cmpq $0x0,0x8(%r15) 0x00007fffe1014e24: je 0x00007fffe1014e2f 0x00007fffe1014e2a: jmpq 0x00007fffe1000420 0x00007fffe1014e2f: mov -0x38(%rbp),%r13 0x00007fffe1014e33: mov -0x30(%rbp),%r14 0x00007fffe1014e37: retq // 结束__ call_VM()函数的调用 // 将Method*存储到%rbx中 0x00007fffe1014e38: mov -0x18(%rbp),%rbx // 将Method::signature_handler放到%11中 0x00007fffe1014e3c: mov 0x68(%rbx),%r11 // **** L1 **** // 从这里开始执行如下的代码逻辑时,Method::signature_handler已经放到了%r11中 // 调用Method::signature_handler函数 0x00007fffe1014e40: callq *%r11 // 调用signature_handler,解析方法参数,整个 // 过程一般不会改变rbx,但是慢速处理时可能导致GC, // 所以调用完成后最好重新获取Method 0x00007fffe1014e43: mov -0x18(%rbp),%rbx // 将%rax中的result_handler存储到方法栈帧中,result_handler // 是执行signature_handler例程后的返回值,根据方法签名的返回类型获取的 0x00007fffe1014e47: mov %rax,0x18(%rbp)
调用的InterpreterRuntime::prepare_native_call()函数会查找native方法对应的本地函数实现并存储到Method的native_function中,同时还会创建signature_handler并存储到Method实例中。我们在《深入剖析Java虚拟机:源码剖析与实例详解(基础卷)》中介绍过Method类,如果是表示native方法的Method实例,那么在为Method实例分配内存时会多分配2个指针大小的空间,如下图所示。

关于native function和signature handler我们后面介绍。
(3)为静态的native方法准备mirror参数
回到InterpreterGenerator::generate_native_entry()函数,继续查看生成的汇编代码,如下:
// 将Method::access_flags存储到%r11d中 0x00007fffe1014e4b: mov 0x28(%rbx),%r11d // 判断是否为static本地方法,其中$0x8表示JVM_ACC_STATIC 0x00007fffe1014e4f: test $0x8,%r11d // 如果为0,表示是非static方法,要跳转到-- L2 -- 0x00007fffe1014e56: je 0x00007fffe1014e74 // 执行这里代码时,说明方法是static方法 // 如下4个mov指令将通过Method->ConstMehod->ConstantPool->mirror // 获取到java.lang.Class的oop 0x00007fffe1014e5c: mov 0x10(%rbx),%r11 0x00007fffe1014e60: mov 0x8(%r11),%r11 0x00007fffe1014e64: mov 0x20(%r11),%r11 0x00007fffe1014e68: mov 0x70(%r11),%r11 // 将mirror存储到栈帧中,也就是oop temp这个slot位置 0x00007fffe1014e6c: mov %r11,0x10(%rbp) // 将mirror拷到%rsi中作为静态方法调用的第2个参数 0x00007fffe1014e70: lea 0x10(%rbp),%rsi // **** L2 **** // 不管是静态还是非静态方法,都会执行如下的汇编片段
对于非静态方法,如上汇编不会产生任何作用,对于静态方法来说,会将静态方法所在类对应的java.lang.Class对象存储到0x10(%rbp)的位置,也就是栈帧中oop temp的位置。
(4)连接Method::native_function并调用
// 获取Method::native_function的地址并存储到%rax中 0x00007fffe1014e74: mov 0x60(%rbx),%rax // %r11中存储的是SharedRuntime::native_method_throw_unsatisfied_link_error_entry() 0x00007fffe1014e78: movabs $0x7ffff6a08f14,%r11 // 判断rax中的地址是否是native_method_throw_unsatisfied_link_error_entry的 // 地址,如果是说明本地方法未绑定 0x00007fffe1014e82: cmp %r11,%rax // 如果不等于,即native方法已经绑定,跳转到----L3---- 0x00007fffe1014e85: jne 0x00007fffe1014f1b // 执行这里的代码,说明native方法没有绑定, // 调用InterpreterRuntime::prepare_native_call()函数重试,完成native方法绑定 0x00007fffe1014e8b: callq 0x00007fffe1014e95 0x00007fffe1014e90: jmpq 0x00007fffe1014f13 0x00007fffe1014e95: mov %rbx,%rsi 0x00007fffe1014e98: lea 0x8(%rsp),%rax 0x00007fffe1014e9d: mov %r13,-0x38(%rbp) 0x00007fffe1014ea1: mov %r15,%rdi 0x00007fffe1014ea4: mov %rbp,0x200(%r15) 0x00007fffe1014eab: mov %rax,0x1f0(%r15) 0x00007fffe1014eb2: test $0xf,%esp 0x00007fffe1014eb8: je 0x00007fffe1014ed0 0x00007fffe1014ebe: sub $0x8,%rsp 0x00007fffe1014ec2: callq 0x00007ffff66af6aa 0x00007fffe1014ec7: add $0x8,%rsp 0x00007fffe1014ecb: jmpq 0x00007fffe1014ed5 0x00007fffe1014ed0: callq 0x00007ffff66af6aa 0x00007fffe1014ed5: movabs $0x0,%r10 0x00007fffe1014edf: mov %r10,0x1f0(%r15) 0x00007fffe1014ee6: movabs $0x0,%r10 0x00007fffe1014ef0: mov %r10,0x200(%r15) 0x00007fffe1014ef7: cmpq $0x0,0x8(%r15) 0x00007fffe1014eff: je 0x00007fffe1014f0a 0x00007fffe1014f05: jmpq 0x00007fffe1000420 0x00007fffe1014f0a: mov -0x38(%rbp),%r13 0x00007fffe1014f0e: mov -0x30(%rbp),%r14 0x00007fffe1014f12: retq // 结束__ call_VM()函数的调用 // 重新获取Method*到%rbx中 0x00007fffe1014f13: mov -0x18(%rbp),%rbx // 获取native_function的地址拷到%rax中 0x00007fffe1014f17: mov 0x60(%rbx),%rax // **** L3 ****
如上汇编为调用native_function本地函数准备了参数。此时的寄存器状态如下:
%rbx:Method* // 表示native方法的Method实例 %rax:native_function // 本地函数的指针 %rsi:mirro // 是静态方法调用时的第2个参数 %rdi:JavaThread::jni_environment // 是为本地方法准备的第1个参数
继续看如下汇编:
// 将当前线程的JavaThread::jni_environment放入c_rarg0,也就是%rdi中 0x00007fffe1014f1b: lea 0x210(%r15),%rdi // 将last_java_fp存储到JavaThread::JavaFrameAnchor::last_java_fp 0x00007fffe1014f22: mov %rbp,0x200(%r15) // 将last_java_pc存储到JavaThead::JavaFrameAnchor::last_java_pc 0x00007fffe1014f29: movabs $0x7fffe1014f22,%r10 0x00007fffe1014f33: mov %r10,0x1f8(%r15) // 将last_java_sp保存到JavaThead.JavaFrameAnchor.last_java_pc中 0x00007fffe1014f3a: mov %rsp,0x1f0(%r15) // 将线程的状态改成_thread_in_native 0x00007fffe1014f41: movl $0x4,0x288(%r15) // 调用native_function本地函数 0x00007fffe1014f4c: callq *%rax // 方法调用结束校验或者恢复CPU控制状态 0x00007fffe1014f4e: vzeroupper // 如下4行代码是为了保存调用native_function函数后得到的结果,将 // 结果存储到栈顶 0x00007fffe1014f51: sub $0x10,%rsp 0x00007fffe1014f55: vmovsd %xmm0,(%rsp) 0x00007fffe1014f5a: sub $0x10,%rsp 0x00007fffe1014f5e: mov %rax,(%rsp)
在调用完本地函数后会执行如下汇编:
// 改变线程的状态为_thread_in_native_trans 0x00007fffe1014f62: movl $0x5,0x288(%r15) // 调用MacroAssembler::serialize_memory()函数 0x00007fffe1014f6d: mov %r15d,%r11d 0x00007fffe1014f70: shr $0x4,%r11d 0x00007fffe1014f74: and $0xffc,%r11d 0x00007fffe1014f7b: movabs $0x7ffff7ff5000,%r10 // 结束MacroAssembler::serialize_memory()函数
在执行完如上的汇编代码后,我们已经执行完了native_function指向的本地函数,同时将本地函数的返回结果也存储到了栈顶。
(5)对执行完native_function的安全点和异常的处理
继续执行如下汇编:
// check for safepoint operation in progress and/or pending suspend requests // 判断安全点的状态是否为_not_synchronized 0x00007fffe1014f85: mov %r11d,(%r10,%r11,1) 0x00007fffe1014f89: cmpl $0x0,0x1639454d(%rip) # 0x00007ffff73a94e0 // 如果不相等,则处于安全点,跳转到---- L ---- 0x00007fffe1014f93: jne 0x00007fffe1014fa7 // 判断当前线程的suspend_flags是否为0,如果 // 是0则跳转到---- Continue ----,表示没有未处理的异常 0x00007fffe1014f99: cmpl $0x0,0x30(%r15) 0x00007fffe1014fa1: je 0x00007fffe1014fbd // **** L **** // 执行这里汇编时,说明处于安全点并且有未处理的异常 // 将JavaThread存储到c_rarg0中 0x00007fffe1014fa7: mov %r15,%rdi // 临时将%rsp存储到%r12中 0x00007fffe1014faa: mov %rsp,%r12 // linux下不起作用 0x00007fffe1014fad: sub $0x0,%rsp // 栈按16字节对齐 0x00007fffe1014fb1: and $0xfffffffffffffff0,%rsp // 调用JavaThread::check_special_condition_for_native_trans()函数 0x00007fffe1014fb5: callq 0x00007ffff6aaf360 // 恢复%rsp 0x00007fffe1014fba: mov %r12,%rsp // **** Continue ****
继续执行如下汇编:
// 线程状态调整为_thread_in_Java,表示running in Java or in stub code 0x00007fffe1014fbd: movl $0x8,0x288(%r15) // 如下汇编清空JavaThead::JavaFrameAnchor::last_java_fp、last_java_sp与last_java_pc 0x00007fffe1014fc8: movabs $0x0,%r10 0x00007fffe1014fd2: mov %r10,0x1f0(%r15) 0x00007fffe1014fd9: movabs $0x0,%r10 0x00007fffe1014fe3: mov %r10,0x200(%r15) 0x00007fffe1014fea: movabs $0x0,%r10 0x00007fffe1014ff4: mov %r10,0x1f8(%r15) // 将JavaThread::active_handles(类型为JNIHandleBlock)存储到%r11中 0x00007fffe1014ffb: mov 0x38(%r15),%r11 // 将JavaThread::active_handles::_top属性置为NULL 0x00007fffe1014fff: movq $0x0,0x108(%r11)
线程状态在执行本地函数时的状态为_thread_in_native,执行完成后更新为_thread_in_native_trans,最后更新为_thread_in_Java,也就表示回到了调用者Java方法,所以要清空本地函数使用的句柄,这样其实就表示已经释放掉了整个JavaThread::active_handles保存的单链接JNIHandleBlock中的所有句柄了,因为第1个JNIHandleBlock的_top属性已经为0。这样的操作会让本地函数的局部对象引用全部变为无效状态。
(6)对native_function执行的结果进行处理
继续执行如下汇编代码:
// If result is an oop unbox and store it in frame where gc will see it // and result handler will pick it up // 从AbstractInterpreter::_native_abi_to_tosca数组中获取对应返回类型的result_handler 0x00007fffe101500a: movabs $0x7fffe100ecdb,%r11 // 比较方法的结果处理程序result_handler是否是T_OBJECT类型的 0x00007fffe1015014: cmp 0x18(%rbp),%r11 // 如果不是则跳转到----no_oop---- 0x00007fffe1015018: jne 0x00007fffe101503e // 如果是,先把栈顶的long类型的数据,即oop地址pop出来放到rax中 0x00007fffe101501e: mov (%rsp),%rax 0x00007fffe1015022: add $0x10,%rsp 0x00007fffe1015026: test %rax,%rax // 如果为0,跳转到----store_result---- 0x00007fffe1015029: je 0x00007fffe1015032 // 如果不为0,那么就表示有返回的oop,注意这里的操作,因为本地函数返回的 // 是句柄,所以要从句柄中获取到真正的oop地址 0x00007fffe101502f: mov (%rax),%rax // **** store_result **** // 将%rax中的值存储到栈的oop tmp中 0x00007fffe1015032: mov %rax,0x10(%rbp) 0x00007fffe1015036: sub $0x10,%rsp // 重新将%rax中的oop放到栈顶 0x00007fffe101503a: mov %rax,(%rsp) // **** no_oop ****
如上汇编代码对本地函数返回的结果进行了处理,尤其是当返回oop时,需要存储到栈帧中开辟的oop temp这个slot中。
(7)判断是否发生了栈溢出
继续执行如下的汇编:
// 判断当前线程的_stack_guard_state属性是否是stack_guard_yellow_disabled,即是否发生了stack overflow 0x00007fffe101503e: cmpl $0x1,0x2b4(%r15) // 如果不等于,即没有发生stack overflow,则跳转到-- no_reguard -- 0x00007fffe1015049: jne 0x00007fffe1015109 // 如果等,即发生stack overflow,则调用reguard_yellow_pages做必要的处理 0x00007fffe101504f: mov %rsp,-0x28(%rsp) 0x00007fffe1015054: sub $0x80,%rsp 0x00007fffe101505b: mov %rax,0x78(%rsp) 0x00007fffe1015060: mov %rcx,0x70(%rsp) 0x00007fffe1015065: mov %rdx,0x68(%rsp) 0x00007fffe101506a: mov %rbx,0x60(%rsp) 0x00007fffe101506f: mov %rbp,0x50(%rsp) 0x00007fffe1015074: mov %rsi,0x48(%rsp) 0x00007fffe1015079: mov %rdi,0x40(%rsp) 0x00007fffe101507e: mov %r8,0x38(%rsp) 0x00007fffe1015083: mov %r9,0x30(%rsp) 0x00007fffe1015088: mov %r10,0x28(%rsp) 0x00007fffe101508d: mov %r11,0x20(%rsp) 0x00007fffe1015092: mov %r12,0x18(%rsp) 0x00007fffe1015097: mov %r13,0x10(%rsp) 0x00007fffe101509c: mov %r14,0x8(%rsp) 0x00007fffe10150a1: mov %r15,(%rsp) 0x00007fffe10150a5: mov %rsp,%r12 0x00007fffe10150a8: sub $0x0,%rsp 0x00007fffe10150ac: and $0xfffffffffffffff0,%rsp 0x00007fffe10150b0: callq 0x00007ffff6a0e098 0x00007fffe10150b5: mov %r12,%rsp 0x00007fffe10150b8: mov (%rsp),%r15 0x00007fffe10150bc: mov 0x8(%rsp),%r14 0x00007fffe10150c1: mov 0x10(%rsp),%r13 0x00007fffe10150c6: mov 0x18(%rsp),%r12 0x00007fffe10150cb: mov 0x20(%rsp),%r11 0x00007fffe10150d0: mov 0x28(%rsp),%r10 0x00007fffe10150d5: mov 0x30(%rsp),%r9 0x00007fffe10150da: mov 0x38(%rsp),%r8 0x00007fffe10150df: mov 0x40(%rsp),%rdi 0x00007fffe10150e4: mov 0x48(%rsp),%rsi 0x00007fffe10150e9: mov 0x50(%rsp),%rbp 0x00007fffe10150ee: mov 0x60(%rsp),%rbx 0x00007fffe10150f3: mov 0x68(%rsp),%rdx 0x00007fffe10150f8: mov 0x70(%rsp),%rcx 0x00007fffe10150fd: mov 0x78(%rsp),%rax 0x00007fffe1015102: add $0x80,%rsp // **** no_guard ****
然后继续执行如下代码:
// 重新加载Method 0x00007fffe1015109: mov -0x18(%rbp),%rbx 0x00007fffe101510d: mov 0x10(%rbx),%r13 // 获取ConstMethod::code的地址存储到%r13中 0x00007fffe1015111: lea 0x30(%r13),%r13
(8)处理异常
汇编代码如下:
// 判断当前线程的_pending_exception属性是否为空,即是否发生了异常 0x00007fffe1015115: cmpq $0x0,0x8(%r15) // 如果不为空,即没有异常,跳转到-- L -- 0x00007fffe101511d: je 0x00007fffe101521f // 当前线程的_pending_exception属性不为空,表示发生了异常 // 省略调用__ MacroAssembler::call_VM()函数生成例程来调用InterpreterRuntime::throw_pending_exception()函数 // 省略调用__ should_not_reach_here()生成的汇编 // **** L ****
(9)释放锁
汇编代码如下:
// 判断目标方法是否是SYNCHRONIZED方法,如果是则需要解锁,如果不是则跳转到----L---- 0x00007fffe101521f: mov 0x28(%rbx),%r11d 0x00007fffe1015223: test $0x20,%r11d // 不需要解锁时直接跳转即可 0x00007fffe101522a: je 0x00007fffe1015405 // 获取偏向锁BasicObjectLock的地址,存储到c_rarg1中 0x00007fffe1015230: lea -0x50(%rbp),%rsi // 获取偏向锁的_obj属性的地址 0x00007fffe1015234: mov 0x8(%rsi),%r11 0x00007fffe1015238: test %r11,%r11 // 判断_obj属性是否为空,如果不为空即未解锁,跳转到unlock完成解锁 0x00007fffe101523b: jne 0x00007fffe101533d // 如果已解锁,说明锁的状态有问题,抛出异常 // 省略调用__ MacroAssembler::call_VM()函数生成的例程,这个例程用来调用InterpreterRuntime::throw_illegal_monitor_state_exception()函数 // 省略调用__ should_not_reach_here()生成的汇编 // 调用InterpreterMacroAssembler::unlock_object()函数 // 将bcp保存到栈帧中 0x00007fffe101533d: mov %r13,-0x38(%rbp) // %rsi中存储的是BasicObjectLock,将BasicLock存储到%rax 0x00007fffe1015341: lea (%rsi),%rax 0x00007fffe1015344: mov 0x8(%rsi),%rcx // 将_obj存储到%rcx中 0x00007fffe1015348: movq $0x0,0x8(%rsi) // 释放_obj属性 // 将_obj的markOop存储到%rdx中 0x00007fffe1015350: mov (%rcx),%rdx 0x00007fffe1015353: and $0x7,%rdx 0x00007fffe1015357: cmp $0x5,%rdx // 如果已经是偏向状态,则跳转 0x00007fffe101535b: je 0x00007fffe1015401 // 不为偏向状态 // 将BasicLock中的markOop存储到%rdx中 0x00007fffe1015361: mov (%rax),%rdx 0x00007fffe1015364: test %rdx,%rdx // 如果为0,说明是锁的重入,跳转 0x00007fffe1015367: je 0x00007fffe1015401 // 原子交换回原markOop,其中的%rdx中存储的就是old markOop,而%rcx中存储的是_obj 0x00007fffe101536d: lock cmpxchg %rdx,(%rcx) // 如果为0,说明是锁的重入,跳转 0x00007fffe1015372: je 0x00007fffe1015401 // 执行这个汇编,说明为非锁重入 0x00007fffe1015378: mov %rcx,0x8(%rsi) // restore obj // 调用call_VM()函数来调用InterpreterRuntime::monitorexit()函数 0x00007fffe101537c: callq 0x00007fffe1015386 0x00007fffe1015381: jmpq 0x00007fffe1015401 0x00007fffe1015386: lea 0x8(%rsp),%rax 0x00007fffe101538b: mov %r13,-0x38(%rbp) 0x00007fffe101538f: mov %r15,%rdi 0x00007fffe1015392: mov %rbp,0x200(%r15) 0x00007fffe1015399: mov %rax,0x1f0(%r15) 0x00007fffe10153a0: test $0xf,%esp 0x00007fffe10153a6: je 0x00007fffe10153be 0x00007fffe10153ac: sub $0x8,%rsp 0x00007fffe10153b0: callq 0x00007ffff66aaab2 0x00007fffe10153b5: add $0x8,%rsp 0x00007fffe10153b9: jmpq 0x00007fffe10153c3 0x00007fffe10153be: callq 0x00007ffff66aaab2 0x00007fffe10153c3: movabs $0x0,%r10 0x00007fffe10153cd: mov %r10,0x1f0(%r15) 0x00007fffe10153d4: movabs $0x0,%r10 0x00007fffe10153de: mov %r10,0x200(%r15) 0x00007fffe10153e5: cmpq $0x0,0x8(%r15) 0x00007fffe10153ed: je 0x00007fffe10153f8 0x00007fffe10153f3: jmpq 0x00007fffe1000420 0x00007fffe10153f8: mov -0x38(%rbp),%r13 0x00007fffe10153fc: mov -0x30(%rbp),%r14 0x00007fffe1015400: retq // 结束call_VM()调用 // 恢复bcp 0x00007fffe1015401: mov -0x38(%rbp),%r13 // 结束unlock_object()函数 // 省略调用notify_method_exit()生成的汇编
由于锁的部分我们到目前为止还没有介绍,所以这一块我们暂时不详细介绍,后面在介绍到锁相关内容时,还会介绍这里的内容。
(10)收尾
汇编代码如下:
// restore potential result in edx:eax(表示64位数), call result handler to // restore potential result in ST0 & handle result // 将栈顶的代表方法调用结果的数据pop到%rax中 0x00007fffe101543c: mov (%rsp),%rax 0x00007fffe1015440: add $0x10,%rsp 0x00007fffe1015444: vmovsd (%rsp),%xmm0 0x00007fffe1015449: add $0x10,%rsp // 获取result_handler存储到%r11中 0x00007fffe101544d: mov 0x18(%rbp),%r11 // 调用result_handler处理方法调用结果 0x00007fffe1015451: callq *%r11 // 获取sender sp,开始恢复上一个Java栈帧 0x00007fffe1015454: mov -0x8(%rbp),%r11 // 相当于指令mov %ebp,%esp和pop %ebp 0x00007fffe1015458: leaveq // 获取return address 0x00007fffe1015459: pop %rdi // 设置sender sp 0x00007fffe101545a: mov %r11,%rsp // 跳转到返回地址处继续执行 0x00007fffe101545d: jmpq *%rdi
如果调用本地函数返回oop,则存储到栈帧中的oop temp处,如果返回的是其它类型,如是浮点数存储在%xmm0,整数等存储在%rax中,这也是本地函数调用约定规定的,之前已经将%xmm0和%rax压入了栈顶,现在恢复到相应的寄存器中,这样就可以调用结果处理例程result_handler进行结果的处理了,处理完成后退栈,然后跳转到返回地址处继续执行即可。
基主要的执行流程如下图所示。
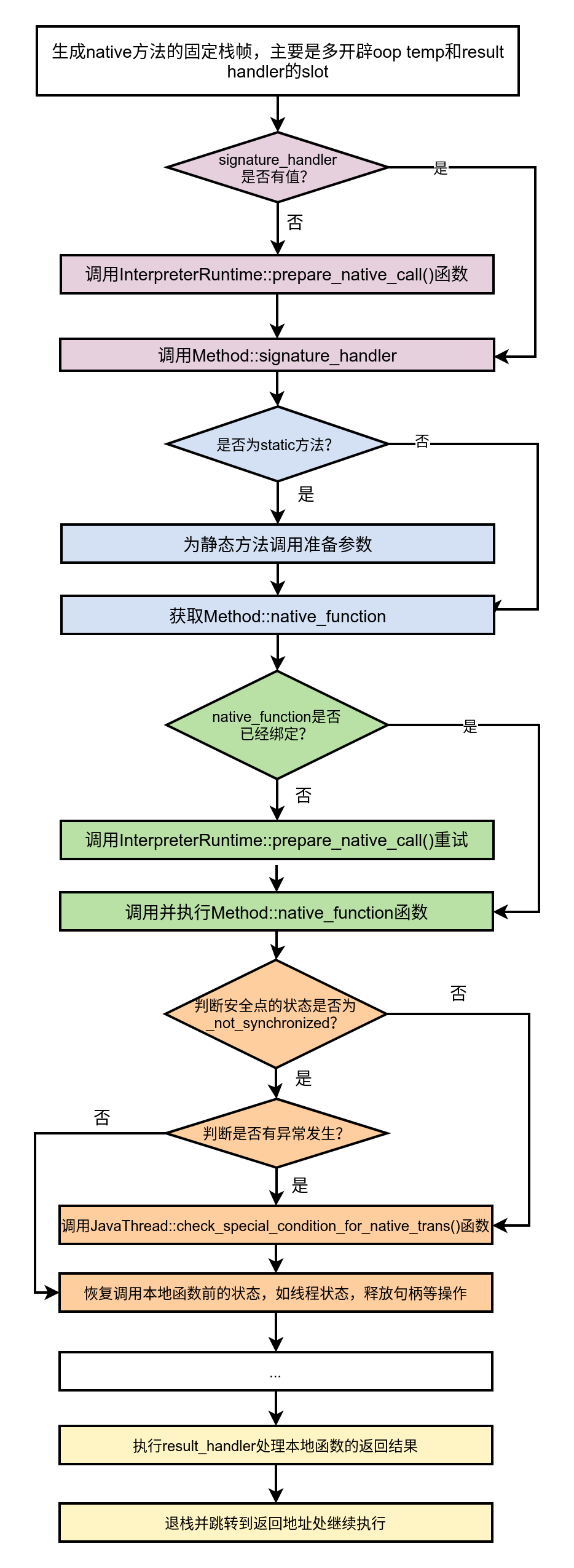
2、设置解释执行的入口
在Method::link_method()函数中为方法设置对应的入口entry,对于本地方法设置native入口,对于本地同步方法设置native_synchronized入口。函数的调用栈如下:
InstanceKlass::initialize_impl() instanceKlass.cpp InstanceKlass::link_class() instanceKlass.cpp InstanceKlass::link_class_impl() instanceKlass.cpp InstanceKlass::link_class_impl() instanceKlass.cpp InstanceKlass::link_methods() instanceKlass.cpp Method::link_method() method.cpp
InstanceKlass::initialize_impl()函数在Java方法连接时会调用,这在《深入剖析Java虚拟机:源码剖析与实例详解(基础卷)》中详细介绍过。HotSpot VM对类进行连接时会调用Method::link_method()函数为Java方法设置执行入口。Method::link_method()函数的实现如下:
// 当方法所属类连接时会调用如下函数,设置Java方法的执行入口,这样Java方法就可以
// 解释执行、编译执行和动态分派了
void Method::link_method(methodHandle h_method, TRAPS) {
// 方法入口已经设置完成,不需要重复设置
if (_i2i_entry != NULL){
return;
}
// 设置解释执行的入口
address entry = Interpreter::entry_for_method(h_method);
// 将解释执行的入口保存到_i2i_entry和_from_interpreted_entry
set_interpreter_entry(entry);
...
// 设置编译执行的入口
(void) make_adapters(h_method, CHECK);
}
我们暂时不介绍编译执行的入口,只看解释执行相关内容。
方法连接主要就是做的事就是设置Method::_from_interpreted_entry属性。连接过程主要是根据方法类型,获取并保存方法对应的入口例程的地址到_i2i_entry和_from_interpreted_entry属性中。
调用的Interpreter::entry_for_method()函数的实现如下:
static address entry_for_method(methodHandle m) {
AbstractInterpreter::MethodKind mk = method_kind(m);
return entry_for_kind(mk);
}
如上函数调用的method_kind()函数的实现中,与本地方法相关的逻辑如下:
// 方法中有native关键字的就是native方法
if (m->is_native()) {
assert(!m->is_method_handle_intrinsic(), "overlapping bits here, watch out");
return m->is_synchronized() ? native_synchronized : native;
}
在entry_for_method()函数中获取MethodKind后调用entry_for_kind()函数,实现如下:
static address entry_for_kind(MethodKind k) {
assert(0 <= k && k < number_of_method_entries, "illegal kind");
return _entry_table[k];
}
在函数TemplateInterpreterGenerator::generate_all()中会初始化_entry_table数组,TemplateInterpreterGenerator::generate_all()函数在HotSpot VM启动时就会调用,所以_entry_table中保存的内容会在HotSpot VM启动时就会设置。
在Method::link_method()函数中调用的set_interpreter_entry()函数的实现如下:
void set_interpreter_entry(address entry){
_i2i_entry = entry;
_from_interpreted_entry = entry;
}
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流