2、CodeBuffer
CodeBuffer类似于IO里面的BufferedReader等用来临时缓存生成的汇编代码,CodeBuffer用来缓存汇编代码的内存通常是BufferBlob中content部分的内存,也可以是其他的已分配的一片内存,可参考CodeBuffer的构造函数。
CodeCache就是用于缓存不同类型的生成的汇编代码,如热点方法编译后的代码,各种运行时的调用入口Stub等,所有的汇编代码在CodeCache中都是以CodeBlob及其子类的形式存在的。
通常CodeBlob会对应一个CodeBuffer,负责生成汇编代码的生成器会通过CodeBuffer将汇编代码写入到CodeBlob中。
A CodeBuffer describes a memory space into which assembly code is generated. This memory space usually occupies the
interior(内部; 里面) of a single BufferBlob, but in some cases it may be an arbitrary span of memory, even outside the code cache.
A code buffer comes in two variants:
(1) A CodeBuffer referring to an already allocated piece of memory:
This is used to direct 'static' code generation (e.g. for interpreter or stubroutine generation, etc.). This code comes with NO relocation information.
(2) A CodeBuffer referring to a piece of memory allocated when the CodeBuffer is allocated. This is used for nmethod generation.
The memory can be divided up into several parts called sections.
Each section independently accumulates code (or data) an relocations.
Sections can grow (at the expense of 以...为代价 a reallocation of the BufferBlob and recopying of all active sections).
When the buffered code is finally written to an nmethod (or other CodeBlob),
the contents (code, data,and relocations) of the sections are padded to an alignment and concatenated.连接
Instructions and data in one section can contain relocatable references to addresses in a sibling section.
The structure of the CodeBuffer while code is being accumulated:
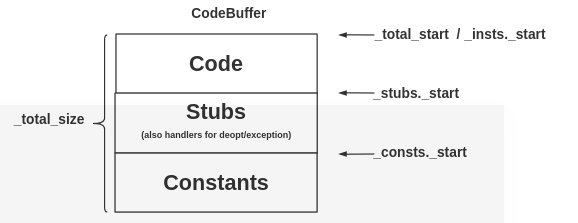
When the code and relocations are copied to the code cache,the empty parts of each section are removed, and everything is copied into contiguous locations.
CodeSection类的定义如下:
源代码位置:share/vm/asm/codeBuffer.hpp
// This class represents a stream of code and associated relocations.
// There are a few in each CodeBuffer.
// They are filled concurrently, and concatenated 使连接(连续,衔接)起来;连锁;串级; at the end.
class CodeSection VALUE_OBJ_CLASS_SPEC {
// ...
}
CodeSection的结构如下:
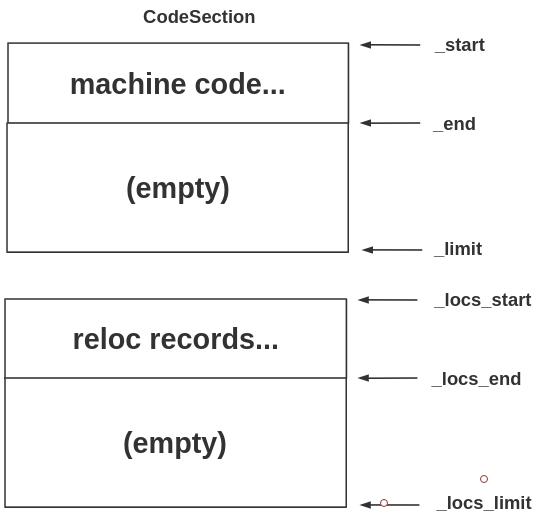
The _end (resp. _limit) pointer refers to the first unused (resp. unallocated) byte.
3、CodeCache::initialize()
在CodeCache::initialize()方法中调用的icache_init()方法的实现如下:
// For init.cpp
void icache_init() {
ICache::initialize();
}
ICache::initialize()方法会调用AbstractICache类中的初始化方法,因为ICache类继承了AbstractICache类,如下:
void AbstractICache::initialize() {
// Making this stub must be FIRST use of assembler
ResourceMark rm;
BufferBlob* b = BufferBlob::create("flush_icache_stub", ICache::stub_size);
CodeBuffer c(b); // CodeBuffer中有BufferBlob的引用
ICacheStubGenerator g(&c);
g.generate_icache_flush(&_flush_icache_stub);
// The first use of flush_icache_stub must apply it to itself.
// The StubCodeMark destructor in generate_icache_flush will
// call Assembler::flush, which in turn will call invalidate_range,
// which will in turn call the flush stub. Thus we don't need an
// explicit call to invalidate_range here. This assumption is
// checked in invalidate_range.
}
CodeBuffer的对象c根据BufferBlob的属性进行初始化。调用BufferBlob::create()方法创建一个BufferBlob对象。方法的实现如下:
BufferBlob* BufferBlob::create(const char* name, int buffer_size) {
BufferBlob* blob = NULL;
unsigned int size = sizeof(BufferBlob);
// align the size to CodeEntryAlignment
size = align_code_offset(size);
size += round_to(buffer_size, oopSize); // oopSize对于是一个指针的宽度,在64位上就是8
assert(name != NULL, "must provide a name");
{
MutexLockerEx mu(CodeCache_lock, Mutex::_no_safepoint_check_flag);
blob = new (size) BufferBlob(name, size);
}
// Track memory usage statistic after releasing CodeCache_lock
MemoryService::track_code_cache_memory_usage();
return blob;
}
调用的align_code_offset()方法的实现如下:
unsigned int align_code_offset(int offset) {
// align the size to CodeEntryAlignment
return
(
(
offset + (int)CodeHeap::header_size() + (CodeEntryAlignment-1)
)
&
~(CodeEntryAlignment-1)
)
- (int)CodeHeap::header_size();
}
在BufferBlob::create()方法中创建BuferBlob对象时,调用new重载运算符和构造函数,如下:
void* BufferBlob::operator new(size_t s, unsigned size, bool is_critical) throw() {
void* p = CodeCache::allocate(size, is_critical);
return p;
}
BufferBlob::BufferBlob(const char* name, int size)
: CodeBlob(
name,
sizeof(BufferBlob),
size,
CodeOffsets::frame_never_safe, /*locs_size:*/
0
)
{}
可以看到,会调用CodeCache::allocate()方法,这个方法在之前已经介绍过,这里不再介绍。
ICacheStubGenerator对象g在初始化时会初始化MacroAssembler,里面有_code_section属性,调用CodeBuffer的insts()方法获取CodeSection对象进行初始化。
class ICacheStubGenerator : public StubCodeGenerator {
public:
ICacheStubGenerator(CodeBuffer *c) : StubCodeGenerator(c) {} // 调用StubCodeGenerator类的构造函数
// ...
}
class StubCodeGenerator: public StackObj {
protected:
MacroAssembler* _masm; // 用来生成汇编代码
StubCodeDesc* _first_stub;
StubCodeDesc* _last_stub;
// ...
}
StubCodeGenerator::StubCodeGenerator(CodeBuffer* code, bool print_code) {
// 构造一个新的MacroAssembler实例
_masm = new MacroAssembler(code);
_first_stub = _last_stub = NULL;
_print_code = print_code;
}
会创建MacroAssembler对象,如下:
MacroAssembler(CodeBuffer* code) : Assembler(code) {} // 调用另外的构造函数进行初始化
Assembler(CodeBuffer* code) : AbstractAssembler(code) {}
// The AbstractAssembler is generating code into a CodeBuffer. To make code generation faster,
// the assembler keeps a copy of the code buffers boundaries & modifies them when
// emitting bytes rather than using the code buffers accessor functions all the time.
// The code buffer is updated via set_code_end(...) after emitting a whole instruction.
AbstractAssembler::AbstractAssembler(CodeBuffer* code) {
if (code == NULL)
return;
CodeSection* cs = code->insts(); // 获取CodeBuffer中的指令部分insts
cs->clear_mark(); // new assembler kills old mark
_code_section = cs;
_oop_recorder= code->oop_recorder();
}
ICache类的定义如下:
// Interface for updating the instruction cache. Whenever the VM modifies
// code, part of the processor instruction cache potentially has to be flushed.
// On the x86, this is a no-op -- the I-cache is guaranteed to be consistent
// after the next jump, and the VM never modifies instructions directly ahead
// of the instruction fetch path.
// [phh] It's not clear that the above comment is correct, because on an MP
// system where the dcaches are not snooped, only the thread doing the invalidate
// will see the update. Even in the snooped case, a memory fence would be
// necessary if stores weren't ordered. Fortunately, they are on all known
// x86 implementations.
class ICache : public AbstractICache {
// ...
}
AbstractICache类的说明如下:
// Interface for updating the instruction cache. Whenever the VM modifies
// code, part of the processor instruction cache potentially has to be flushed.
// Default implementation is in icache.cpp, and can be hidden per-platform.
// Most platforms must provide only ICacheStubGenerator::generate_icache_flush().
// Platforms that don't require icache flushing can just nullify the public
// members of AbstractICache in their ICache class. AbstractICache should never
// be referenced other than by deriving the ICache class from it.
//
// The code for the ICache class and for generate_icache_flush() must be in
// architecture-specific files, i.e., icache_<arch>.hpp/.cpp
class AbstractICache : AllStatic {
...
}
CodeBuffer类的构造函数如下:
// External buffer, in a predefined CodeBlob.
// Important: The code_start must be taken exactly, and not realigned.
CodeBuffer::CodeBuffer(CodeBlob* blob) {
initialize_misc("static buffer");
initialize(blob->content_begin(), blob->content_size());
verify_section_allocation();
}
4、JVM选项
这里列出一些和代码缓存相关的JVM选项。我想读了这篇文章前面的内容,应该很容易理解这些JVM选项的意义。
- -XX:InitialCodeCacheSize:设置代码缓存的初始大小,这个参数在intel处理器下,在client编译器模式下是160KB,而在server编译器模式下是2496KB;
- -XX:ReservedCodeCacheSize:设置代码缓存的大小;
- -XX:+UseCodeCacheFlushing:当代码缓存满了的时候,让JVM换出一部分缓存以容纳新编译的代码。在默认情况下,这个选项是关闭的。这意味着,在代码缓存满了的时候,JVM会切换到纯解释器模式,这对于性能来说,可以说是毁灭性的影响;
- -XX:NmethodSweepCheckInterval:设置清理缓存的时间间隔;
- -XX:+DontCompileHugeMethods:默认不对大方法进行JIT编译;
- -XX:HugeMethodLimit: 默认值是8000,遗憾的是,在产品环境下,该值不允许被修改;