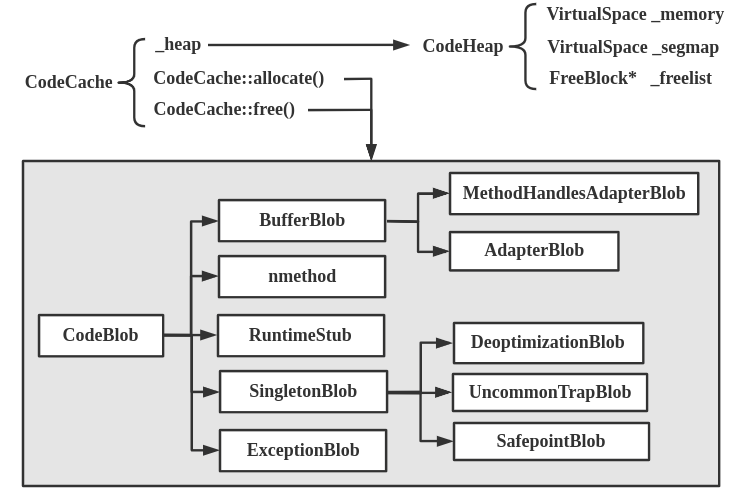
Java代码在执行时一旦被编译器编译为机器码,下一次执行的时候就会直接执行编译后的代码,也就是说,编译后的代码被缓存了起来。缓存编译后的机器码的内存区域就是CodeCache。
这是一块独立于java堆之外的内存区域。除了JIT编译的代码之外,java所使用的本地方法代码(JNI)也会存在CodeCache中。不同版本的HotSpot、不同的启动方式CodeCache的默认大小也不同。
CodeCache类的定义如下:
源代码位置:code/codeCache.hpp
// The CodeCache implements the code cache for various pieces of generated
// code, e.g., compiled java methods, runtime stubs, transition frames, etc.
// The entries in the CodeCache are all CodeBlob's.
// Implementation:
// - Each CodeBlob occupies one chunk of memory.
// - Like the offset table in oldspace the zone has at table for
// locating a method given a addess of an instruction.
class CodeCache : AllStatic {
friend class VMStructs;
private:
// CodeHeap is malloc()'ed at startup and never deleted during shutdown,
// so that the generated assembly code is always there when it's needed.
// This may cause memory leak, but is necessary, for now. See 4423824,
// 4422213 or 4436291 for details.
static CodeHeap * _heap;
static int _number_of_blobs;
static int _number_of_adapters;
static int _number_of_nmethods;
static int _number_of_nmethods_with_dependencies;
static bool _needs_cache_clean;
static nmethod* _scavenge_root_nmethods; // linked via nm->scavenge_root_link()
...
}
CodeCache里面含有极多的静态方法,用于管理代码缓存。最主要的方法有:
static CodeBlob* allocate(int size, bool is_critical = false); // allocates a new CodeBlob static void free(CodeBlob* cb); // frees a CodeBlob
两个方法的实现如下:
CodeBlob* CodeCache::allocate(int size, bool is_critical) {
// Do not seize(控制、俘获) the CodeCache lock here--if the caller has not
// already done so, we are going to lose bigtime, since the code
// cache will contain a garbage CodeBlob until the caller can
// run the constructor for the CodeBlob subclass he is busy
// instantiating.
guarantee(size >= 0, "allocation request must be reasonable");
assert_locked_or_safepoint(CodeCache_lock);
CodeBlob* cb = NULL;
_number_of_blobs++;
while (true) {
cb = (CodeBlob*)_heap->allocate(size, is_critical); // 在堆上分配一个CodeBlob的存储空间
if (cb != NULL) break;
if (!_heap->expand_by(CodeCacheExpansionSize)) {
// Expansion failed
return NULL;
}
}
maxCodeCacheUsed = MAX2(maxCodeCacheUsed,
((address)_heap->high_boundary() - (address)_heap->low_boundary()) - unallocated_capacity());
return cb;
}
void CodeCache::free(CodeBlob* cb) {
if (cb->is_nmethod()) {
_number_of_nmethods--;
if ( ((nmethod *)cb)->has_dependencies() ) {
_number_of_nmethods_with_dependencies--;
}
}
if (cb->is_adapter_blob()) {
_number_of_adapters--;
}
_number_of_blobs--;
_heap->deallocate(cb); //在堆上释放CodeBlob所占用的空间
}
一个用于分配缓存空间,一个用于释放缓存空间。它们都是在一个堆上执行操作的。这个堆就是CodeCache里面的静态变量_heap所指向的:
// CodeHeap is malloc()'ed at startup and never deleted during shutdown, // so that the generated assembly code is always there when it's needed. // This may cause memory leak, but is necessary, for now. See 4423824, // 4422213 or 4436291 for details. static CodeHeap * _heap;
在CodeHeap中分配内存。CodeHeap就是实际管理汇编代码内存分配的实现。CodeCache只是CodeHeap的一层包装而已,核心实现都在位于hotspot/src/share/vm/memory/heap.hpp文件的CodeHeap中。如下图所示。
CodeCache的初始化调用链如下:
codeCache_init() codeCache.cpp init_globals() init.cpp Threads::create_vm() thread.cpp JNI_CreateJavaVM() jni.cpp InitializeJVM() java.c JavaMain() java.c
codeCache_init()方法的实现如下:
void codeCache_init() {
CodeCache::initialize();
}
调用的CodeCache::initialize()方法的实现如下:
void CodeCache::initialize() {
// This was originally just a check of the alignment, causing failure, instead, round
// the code cache to the page size. In particular, Solaris is moving to a larger
// default page size.
// 按照系统的内存页大小对CodeCache的参数取整
// CodeCacheExpansionSize表示CodeCache扩展一次内存空间对应的内存大小,在client编译器模式下是32*K,在server编译器模式下是64*K
CodeCacheExpansionSize = round_to(CodeCacheExpansionSize, os::vm_page_size());
// InitialCodeCacheSize表示CodeCache的初始大小,在client编译器模式下是160*K,在server编译器模式下是2496*K (2496=64*39)
InitialCodeCacheSize = round_to(InitialCodeCacheSize, os::vm_page_size());
// ReservedCodeCacheSize表示CodeCache的最大内存大小,在client编译器模式下是32*M,在server编译器模式下是48*M,M为K*K
ReservedCodeCacheSize = round_to(ReservedCodeCacheSize, os::vm_page_size());
// 完成heap属性的初始化,CodeCacheSegmentSize是内存分配的最小单元
if (!_heap->reserve(ReservedCodeCacheSize, InitialCodeCacheSize, CodeCacheSegmentSize)) {
vm_exit_during_initialization("Could not reserve enough space for code cache");
}
// 将CodeHeap放入一个MemoryPool中管理起来
MemoryService::add_code_heap_memory_pool(_heap);
// Initialize ICache flush mechanism
// This service is needed for os::register_code_area
// 初始化用于刷新CPU指令缓存的Icache,即生成一段用于刷新指令缓存的汇编代码,
// 此时因为heap属性已初始化完成,所以可以从CodeCache中分配Blob了
icache_init();
}
调用的_heap->reserve()方法的实现如下:
// 方法主要是对codeHeap中定义的_memory与_segmap属性进行初始化
bool CodeHeap::reserve(
// -XX:ReservedCodeCacheSize:设置代码缓存的大小
size_t reserved_size,
// -XX:InitialCodeCacheSize:设置代码缓存的初始大小,
// 在client编译器模式下是160*K,而在server编译器模式下是2496*K;
size_t committed_size,
// -XX:CodeCacheSegmentSize:每次存储请求都会分配一定大小的空间,这个值由这个命令指定
size_t segment_size
){
_segment_size = segment_size;
// 如segment_size为64,那么_log2_segment_size为6
_log2_segment_size = exact_log2(segment_size);
// Reserve(预订) and initialize space for _memory.
size_t page_size; // 删除了const
if(os::can_execute_large_page_memory()){
page_size = os::page_size_for_region(committed_size, reserved_size, 8);
}else{
page_size = os::vm_page_size(); // page_size是4096
}
const size_t granularity = os::vm_allocation_granularity(); // granularity(粒度;粒性)
const size_t r_align = MAX2(page_size, granularity);
const size_t r_size = align_size_up(reserved_size, r_align);
const size_t c_size = align_size_up(committed_size, page_size);
const size_t rs_align = page_size == (size_t) os::vm_page_size() ? 0 : MAX2(page_size, granularity);
ReservedCodeSpace rs(r_size, rs_align, rs_align > 0);
if (!_memory.initialize(rs, c_size)) {
return false;
}
_number_of_committed_segments = size_to_segments(_memory.committed_size());
_number_of_reserved_segments = size_to_segments(_memory.reserved_size());
const size_t reserved_segments_alignment = MAX2((size_t)os::vm_page_size(), granularity);
const size_t reserved_segments_size = align_size_up(_number_of_reserved_segments, reserved_segments_alignment);
const size_t committed_segments_size = align_to_page_size(_number_of_committed_segments);
// reserve space for _segmap
if (!_segmap.initialize(reserved_segments_size, committed_segments_size)) {
return false;
}
// initialize remaining instance variables
clear();
return true;
}
这个方法主要对CodeHeap类中一些变量的初始化,同时也初始化了CodeHeap类中声明了2个变量_memory与_segmap。这2个变量的类型为VirtualSpace。调用initialize()函数来初始化VitualSpace对象相关的属性。
1、CodeHeap
CodeHeap是一个堆结构,其关键性质是其内维护了一个空闲块的链表。 CodeHeap定义如下:
源代码位置:hotspot/src/share/vm/memory/heap.hpp
class CodeHeap : public CHeapObj<mtCode> {
private:
VirtualSpace _memory; // the memory holding the blocks
VirtualSpace _segmap; // the memory holding the segment map
size_t _number_of_committed_segments;
size_t _number_of_reserved_segments;
size_t _segment_size;
int _log2_segment_size;
size_t _next_segment;
FreeBlock* _freelist;
size_t _freelist_segments; // No. of segments in freelist
...
}
这个堆的管理方式就如同一般的空闲链表支撑的堆的管理方式。查找空闲块的时候,它采用的最佳适应,这意味着每次都需要整个空闲链表来查找;
在释放空间的时候,还会执行空闲块的合并,所以说,2个空闲块如果挨着,那么就会合并成一个更大的空间块。
调用size_to_segments()函数的实现如下:
size_t size_to_segments(size_t size) const {
return (size + _segment_size - 1) >> _log2_segment_size;
}
_segment_size默认值为64,_log2_segment_size值为6。
2、VirtualSpace类
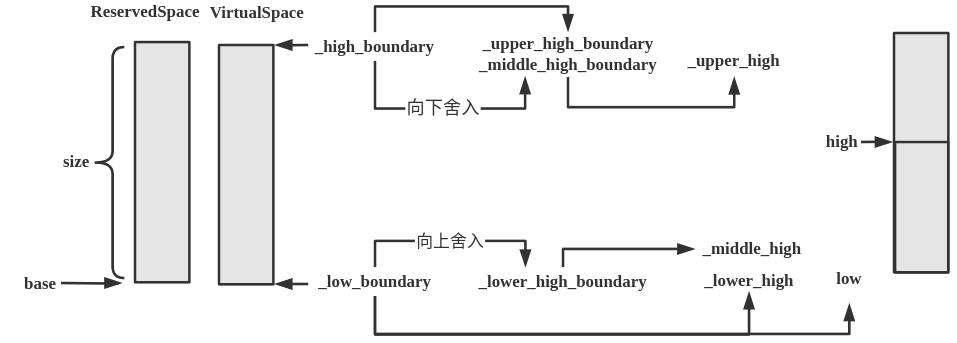
CodeHeap类中声明了2个变量_memory与_segmap。这2个变量的类型为VirtualSpace。调用initialize()函数来初始化VitualSpace对象相关的属性。VirtualSpace类的initialize()函数的实现如下:
bool VirtualSpace::initialize(ReservedSpace rs, size_t committed_size) {
const size_t max_commit_granularity = os::page_size_for_region(rs.size(), rs.size(), 1); // 默认为4096
return initialize_with_granularity(rs, committed_size, max_commit_granularity);
}
bool VirtualSpace::initialize_with_granularity(ReservedSpace rs, size_t committed_size, size_t max_commit_granularity) {
if(!rs.is_reserved())
return false; // allocation failed.
assert(_low_boundary == NULL, "VirtualSpace already initialized");
assert(max_commit_granularity > 0, "Granularity must be non-zero.");
_low_boundary = rs.base();
_high_boundary = low_boundary() + rs.size();
_low = low_boundary();
_high = low();
_special = rs.special();
_executable = rs.executable();
// When a VirtualSpace begins life at a large size, make all future expansion
// and shrinking occur aligned to a granularity of large pages. This avoids
// fragmentation of physical addresses that inhibits the use of large pages
// by the OS virtual memory system. Empirically, we see that with a 4MB
// page size, the only spaces that get handled this way are codecache and
// the heap itself, both of which provide a substantial performance
// boost in many benchmarks when covered by large pages.
//
// No attempt is made to force large page alignment at the very top and
// bottom of the space if they are not aligned so already.
_lower_alignment = os::vm_page_size();
_middle_alignment = max_commit_granularity;
_upper_alignment = os::vm_page_size();
// End of each region
_lower_high_boundary = (char*) round_to( (intptr_t) low_boundary(), middle_alignment() );
_middle_high_boundary = (char*) round_down( (intptr_t) high_boundary(), middle_alignment() );
_upper_high_boundary = high_boundary();
// High address of each region
_lower_high = low_boundary();
_middle_high = lower_high_boundary();
_upper_high = middle_high_boundary();
// commit to initial size
if (committed_size > 0) {
if (!expand_by(committed_size)) {
return false;
}
}
return true;
}
方法执行完成后,各个变量的值如下图所示。
调用的expand_by()函数的实现如下:
/*
First we need to determine if a particular virtual space is using large
pages. This is done at the initialize function and only virtual spaces
that are larger than LargePageSizeInBytes use large pages. Once we
have determined this, all expand_by and shrink_by calls must grow and
shrink by large page size chunks. If a particular request
is within the current large page, the call to commit and uncommit memory
can be ignored. In the case that the low and high boundaries of this
space is not large page aligned, the pages leading to the first large
page address and the pages after the last large page address must be
allocated with default pages.
*/
bool VirtualSpace::expand_by(size_t bytes, bool pre_touch) { // bytes表示初始化内存的大小
if (uncommitted_size() < bytes) return false;
if (special()) {
// don't commit memory if the entire space is pinned in memory
_high += bytes;
return true;
}
char* previous_high = high();
char* unaligned_new_high = high() + bytes;
assert(unaligned_new_high <= high_boundary(),"cannot expand by more than upper boundary");
// Calculate where the new high for each of the regions should be. If
// the low_boundary() and high_boundary() are LargePageSizeInBytes aligned
// then the unaligned lower and upper new highs would be the
// lower_high() and upper_high() respectively.
char* unaligned_lower_new_high = MIN2(unaligned_new_high, lower_high_boundary());
char* unaligned_middle_new_high = MIN2(unaligned_new_high, middle_high_boundary());
char* unaligned_upper_new_high = MIN2(unaligned_new_high, upper_high_boundary());
// Align the new highs based on the regions alignment. lower and upper
// alignment will always be default page size. middle alignment will be
// LargePageSizeInBytes if the actual size of the virtual space is in
// fact larger than LargePageSizeInBytes.
char* aligned_lower_new_high = (char*) round_to((intptr_t) unaligned_lower_new_high, lower_alignment());
char* aligned_middle_new_high = (char*) round_to((intptr_t) unaligned_middle_new_high, middle_alignment());
char* aligned_upper_new_high = (char*) round_to((intptr_t) unaligned_upper_new_high, upper_alignment());
// Determine which regions need to grow in this expand_by call.
// If you are growing in the lower region, high() must be in that
// region so calcuate the size based on high(). For the middle and
// upper regions, determine the starting point of growth based on the
// location of high(). By getting the MAX of the region's low address
// (or the prevoius region's high address) and high(), we can tell if it
// is an intra or inter region growth.
size_t lower_needs = 0;
if (aligned_lower_new_high > lower_high()) {
lower_needs = pointer_delta(aligned_lower_new_high, lower_high(), sizeof(char));
}
size_t middle_needs = 0;
if (aligned_middle_new_high > middle_high()) {
middle_needs = pointer_delta(aligned_middle_new_high, middle_high(), sizeof(char));
}
size_t upper_needs = 0;
if (aligned_upper_new_high > upper_high()) {
upper_needs = pointer_delta(aligned_upper_new_high, upper_high(), sizeof(char));
}
// Check contiguity.
assert(low_boundary() <= lower_high() &&
lower_high() <= lower_high_boundary(),
"high address must be contained within the region");
assert(lower_high_boundary() <= middle_high() &&
middle_high() <= middle_high_boundary(),
"high address must be contained within the region");
assert(middle_high_boundary() <= upper_high() &&
upper_high() <= upper_high_boundary(),
"high address must be contained within the region");
// Commit regions
if (lower_needs > 0) {
assert(low_boundary() <= lower_high() &&
lower_high() + lower_needs <= lower_high_boundary(),
"must not expand beyond region");
if (!os::commit_memory(lower_high(), lower_needs, _executable)) {
debug_only(warning("INFO: os::commit_memory(" PTR_FORMAT
", lower_needs=" SIZE_FORMAT ", %d) failed",
lower_high(), lower_needs, _executable);)
return false;
} else {
_lower_high += lower_needs;
}
}
if (middle_needs > 0) {
assert(lower_high_boundary() <= middle_high() &&
middle_high() + middle_needs <= middle_high_boundary(),
"must not expand beyond region");
if (!os::commit_memory(middle_high(), middle_needs, middle_alignment(),
_executable)) {
debug_only(warning("INFO: os::commit_memory(" PTR_FORMAT
", middle_needs=" SIZE_FORMAT ", " SIZE_FORMAT
", %d) failed", middle_high(), middle_needs,
middle_alignment(), _executable);)
return false;
}
_middle_high += middle_needs;
}
if (upper_needs > 0) {
assert(middle_high_boundary() <= upper_high() &&
upper_high() + upper_needs <= upper_high_boundary(),
"must not expand beyond region");
if (!os::commit_memory(upper_high(), upper_needs, _executable)) {
debug_only(warning("INFO: os::commit_memory(" PTR_FORMAT
", upper_needs=" SIZE_FORMAT ", %d) failed",
upper_high(), upper_needs, _executable);)
return false;
} else {
_upper_high += upper_needs;
}
}
if (pre_touch || AlwaysPreTouch) {
int vm_ps = os::vm_page_size();
for (char* curr = previous_high; curr < unaligned_new_high; curr += vm_ps) {
// Note the use of a write here; originally we tried just a read, but
// since the value read was unused, the optimizer removed the read.
// If we ever have a concurrent touchahead thread, we'll want to use
// a read, to avoid the potential of overwriting data (if a mutator
// thread beats the touchahead thread to a page). There are various
// ways of making sure this read is not optimized away: for example,
// generating the code for a read procedure at runtime.
*curr = 0;
}
}
_high += bytes;
return true;
}
主要还是更新_high变量的值。
3、ReservedSpace
在CodeHeap::reserve()函数中有如下调用:
const size_t granularity = os::vm_allocation_granularity(); // granularity(粒度;粒性) const size_t r_align = MAX2(page_size, granularity); const size_t r_size = align_size_up(reserved_size, r_align); // reserved_size表示代码缓存的大小 const size_t c_size = align_size_up(committed_size, page_size); // committed_size表示代码初始化大小 const size_t rs_align = page_size == (size_t) os::vm_page_size() ? 0 : MAX2(page_size, granularity); ReservedCodeSpace rs(r_size, rs_align, rs_align > 0);
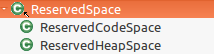
ReservedCodeSpace继承自ReservedSpace,ReservedSpace的继承体系如下:
ReservedSpace类及重要变量的定义如下:
// ReservedSpace is a data structure for reserving a contiguous address range.
class ReservedSpace VALUE_OBJ_CLASS_SPEC {
private:
char* _base;
size_t _size;
size_t _noaccess_prefix; // 禁止访问的前缀
size_t _alignment;
bool _special;
bool _executable;
// ...
}
重要函数的实现如下:
ReservedSpace ReservedSpace::first_part(size_t partition_size, bool split, bool realloc){
size_t x = alignment();
return first_part(partition_size,x , split, realloc);
}
ReservedSpace ReservedSpace::last_part(size_t partition_size){
size_t x = alignment();
return last_part(partition_size, x);
}
ReservedSpace ReservedSpace::first_part(
size_t partition_size,
size_t alignment,
bool split,
bool realloc
) {
assert(partition_size <= size(), "partition failed");
if (split) {
os::split_reserved_memory(base(), size(), partition_size, realloc);
}
ReservedSpace result( base(),
partition_size,
alignment,
special(),
executable());
return result;
}
ReservedSpace ReservedSpace::last_part(
size_t partition_size,
size_t alignment
) {
assert(partition_size <= size(), "partition failed");
ReservedSpace result( base() + partition_size,
size() - partition_size,
alignment,
special(),
executable());
return result;
}
另外2个类的定义如下:
// Class encapsulating behavior specific of memory space reserved for Java heap
// (此类的行为针对的是为Java堆保存的内存空间)
class ReservedHeapSpace : public ReservedSpace {
public:
// Constructor
ReservedHeapSpace(size_t size, size_t forced_base_alignment,bool large, char* requested_address);
};
// Class encapsulating behavior specific memory space for Code
// 提供针对Code的内存空间的操作
class ReservedCodeSpace : public ReservedSpace {
public:
// Constructor
ReservedCodeSpace(size_t r_size, size_t rs_align, bool large);
};
ReservedCodeSpace的构造函数如下:
// Reserve space for code segment. Same as Java heap only we mark this as executable.
ReservedCodeSpace::ReservedCodeSpace(
size_t r_size,
size_t rs_align,
bool large
)
: ReservedSpace(r_size, rs_align, large, /*executable*/ true) {
}
ReservedSpace::ReservedSpace(
size_t size,
size_t alignment,
bool large,
bool executable
){
initialize(size, alignment, large, NULL, 0, executable);
}
void ReservedSpace::initialize(
size_t size,
size_t alignment,
bool large,
char* requested_address,
const size_t noaccess_prefix,
bool executable
){
const size_t granularity = os::vm_allocation_granularity(); // granularity 粒度;(颗,成)粒性;
alignment = MAX2(alignment, (size_t)os::vm_page_size());
_base = NULL;
_size = 0;
_special = false;
_executable = executable; // ReservedCodeSpace对象的值为true
_alignment = 0;
_noaccess_prefix = 0;
if (size == 0) {
return;
}
char* base = NULL;
if (requested_address != 0) {
requested_address -= noaccess_prefix; // adjust requested address
assert(requested_address != NULL, "huge noaccess prefix?");
}
if (base == NULL) {
// Optimistically assume that the OSes returns an aligned base pointer.
// When reserving a large address range, most OSes seem to align to at least 64K.
// If the memory was requested at a particular address, use
// os::attempt_reserve_memory_at() to avoid over mapping something
// important. If available space is not detected, return NULL.
if (requested_address != 0) {
base = os::attempt_reserve_memory_at(size, requested_address);
if (failed_to_reserve_as_requested(base, requested_address, size, false)) {
// OS ignored requested address. Try different address.
base = NULL;
}
} else {
base = os::reserve_memory(size, NULL, alignment);
}
if (base == NULL){
return;
}
}// end base == NULL
// Done
_base = base;
_size = size;
_alignment = alignment;
_noaccess_prefix = noaccess_prefix;
assert(markOopDesc::encode_pointer_as_mark(_base)->decode_pointer() == _base,"area must be distinguisable from marks for mark-sweep");
assert(markOopDesc::encode_pointer_as_mark(&_base[size])->decode_pointer() == &_base[size],"area must be distinguisable from marks for mark-sweep");
}
调用的os::reserve_momory()函数的实现如下:
char* os::reserve_memory(size_t bytes, char* addr, size_t alignment_hint) {
char* result = pd_reserve_memory(bytes, addr, alignment_hint);
return result;
}
char* os::pd_reserve_memory(size_t bytes, char* requested_addr,size_t alignment_hint) {
return anon_mmap(requested_addr, bytes, (requested_addr != NULL));
}
// If 'fixed' is true, anon_mmap() will attempt to reserve anonymous memory
// at 'requested_addr'. If there are existing memory mappings at the same
// location, however, they will be overwritten. If 'fixed' is false,
// 'requested_addr' is only treated as a hint, the return value may or
// may not start from the requested address. Unlike Linux mmap(), this
// function returns NULL to indicate failure.
static char* anon_mmap(char* requested_addr, size_t bytes, bool fixed) {
char * addr;
int flags;
// MAP_ANONYMOUS:建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享。
// MAP_NORESERVE :不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,
// 同时内存不足,对映射区的修改会引起段违例信号。
// MAP_PRIVATE :建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。
flags = MAP_PRIVATE | MAP_NORESERVE | MAP_ANONYMOUS;
if (fixed) {
assert((uintptr_t)requested_addr % os::Linux::page_size() == 0, "unaligned address");
flags |= MAP_FIXED;
}
// Map reserved/uncommitted pages PROT_NONE so we fail early if we
// touch an uncommitted page. Otherwise, the read/write might
// succeed if we have enough swap space to back the physical page.
addr = (char*)::mmap(requested_addr, bytes, PROT_NONE,flags, -1, 0); // PROT_NONE表示无法访问映射区域的页,申请虚拟内存区域
if (addr != MAP_FAILED) {
// anon_mmap() should only get called during VM initialization,
// don't need lock (actually we can skip locking even it can be called
// from multiple threads, because _highest_vm_reserved_address is just a
// hint about the upper limit of non-stack memory regions.)
if ((address)addr + bytes > _highest_vm_reserved_address) {
_highest_vm_reserved_address = (address)addr + bytes;
}
}
return addr == MAP_FAILED ? NULL : addr;
}
方法向操作系统申请了内存空间。