声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢!
1 现有的排序模型
排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要可以分为以下两类:相关度排序模型和重要性排序模型。
1.1 相关度排序模型(Relevance Ranking Model)
相关度排序模型根据查询和文档之间的相似度来对文档进行排序。常用的模型包括:布尔模型(Boolean Model),向量空间模型(Vector Space Model),隐语义分析(Latent Semantic Analysis),BM25,LMIR模型等等。
1.2 重要性排序模型(Importance Ranking Model)
重要性排序模型不考虑查询,而仅仅根据网页(亦即文档)之间的图结构来判断文档的权威程度,典型的权威网站包括Google,Yahoo!等。常用的模型包括PageRank,HITS,HillTop,TrustRank等等。
2 前言
在传统搜索引擎的ranking策略中,一般会包含若干子策略,子策略通过若干种方式组合成更大的策略一起发挥作用。策略的组合方式以及参数一般采取人工或者半人工的方式确定。随着策略的逐步细化,传统的方式变得越来越困难。于是Learning to Rank(LTR)就被引入了进来。LTR的核心是想是用机器学习来解决排序的问题。目前被广泛运用在 信息检索(IR) 、 自然语言处理(NLP) 和 数据挖掘(DM) 中。 LTR是监督的学习。建好模型之后,需要用训练数据集的人工标注结果来训练。
3 LTR流程

4 训练数据的获取
有2种获取训练数据的来源:1)人工标注;2)搜索日志。
4.1 人工标注
从搜索日志中随机选取一部分Query,让受过专业训练的数据评估员对"Query-Url对"给出相关性判断。常见的是5档的评分:差、一般、好、优秀、完美。以此作为训练数据。 人工标注是标注者的主观判断,会受标注者背景知识等因素的影响。
4.2 搜索日志
使用点击日志的偏多。比如,结果ABC分别位于123位,B比A位置低,但却得到了更多的点击,那么B的相关性可能好于A。点击数据隐式反映了同Query下搜索结果之间相关性的相对好坏。在搜索结果中,高位置的结果被点击的概率会大于低位置的结果,这叫做"点击偏见"(Click Bias)。但采取以上的方式,就绕过了这个问题。因为我们只记录发生了"点击倒置"的高低位结果,使用这样的"偏好对"作为训练数据。关于点击数据的使用,后续再单独开帖记录,这里不展开。 在实际应用中,除了点击数据,往往还会使用更多的数据。比如通过session日志,挖掘诸如页面停留时间等维度。 在实际场景中,搜索日志往往含有很多噪音。且只有Top Query(被搜索次数较多的Query)才能产生足够数量能说明问题的搜索日志。
4.3 公共数据集
现存一批公开的数据集可以使用
- LETOR, http://research.microsoft.com/en-us/um/beijing/projects/letor/
- Microsoft Learning to Rank Dataset, http://research.microsoft.com/en-us/projects/mslr/
- Yahoo Learning to Rank Challenge, http://webscope.sandbox.yahoo.com/
5 特征抽取
搜索引擎会使用一系列特征来决定结果的排序。一个特征称之为一个“feature”。按照我的理解,feature可以分为3大类:
- Doc本身的特征:Pagerank、内容丰富度、是否是spam等
- Query-Doc的特征:文本相关性、Query term在文档中出现的次数等
此阶段就是要抽取出所有的特征,供后续训练使用。
6 模型训练
6.1 训练方法
LTR的学习方法分为Pointwise、Pairwise和Listwise三类。
Pointwise和Pairwise把排序问题转换成 回归 、 分类 或 有序分类 问题。Lisewise把Query下整个搜索结果作为一个训练的实例。3种方法的区别主要体现在损失函数(Loss Function)上。
6.1.1 Pointwise
排序问题被转化成单结果的 回归 、 分类 或 有序分类 的问题。
PointWise方法只考虑给定查询下,单个文档的绝对相关度,而不考虑其他文档和给定查询的相关度。亦即给定查询q的一个真实文档序列,我们只需要考虑单个文档di和该查询的相关程度ci,亦即输入数据应该是如下的形式:

- 函数框架
L(F(x),y)=∑i=1nl(f(xi)−yi)
- 小结

-
Pointwise方法主要包括以下算法:Pranking (NIPS 2002), OAP-BPM (EMCL 2003), Ranking with Large Margin Principles (NIPS 2002), Constraint Ordinal Regression (ICML 2005)。
Pointwise方法仅仅使用传统的分类,回归或者Ordinal Regression方法来对给定查询下单个文档的相关度进行建模。这种方法没有考虑到排序的一些特征,比如文档之间的排序结果针对的是给定查询下的文档集合,而Pointwise方法仅仅考虑单个文档的绝对相关度;另外,在排序中,排在最前的几个文档对排序效果的影响非常重要,Pointwise没有考虑这方面的影响。
6.1.2 Pairwise
排序问题被转化成结果对的 回归 、 分类 或 有序分类 的问题。
Pairwise方法考虑给定查询下,两个文档之间的相对相关度。亦即给定查询q的一个真实文档序列,我们只需要考虑任意两个相关度不同的文档之间的相对相关度:di>dj,或者di<dj。

- 函数框架
L(F(x),y)=∑i=1n−1∑j=i+1nl(sign(yi−yj),f(xi)−f(xj))
- 小结

Pairwise方法主要包括以下几种算法:Learning to Retrieve Information (SCC 1995), Learning to Order Things (NIPS 1998), Ranking SVM (ICANN 1999), RankBoost (JMLR 2003), LDM (SIGIR 2005), RankNet (ICML 2005), Frank (SIGIR 2007), MHR(SIGIR 2007), Round Robin Ranking (ECML 2003), GBRank (SIGIR 2007), QBRank (NIPS 2007), MPRank (ICML 2007), IRSVM (SIGIR 2006) 。
相比于Pointwise方法,Pairwise方法通过考虑两两文档之间的相对相关度来进行排序,有一定的进步。但是,Pairwise使用的这种基于两两文档之间相对相关度的损失函数,和真正衡量排序效果的一些指标之间,可能存在很大的不同,有时甚至是负相关,如下图所示(pairwise的损失函数和NDCG之呈现出负相关性):
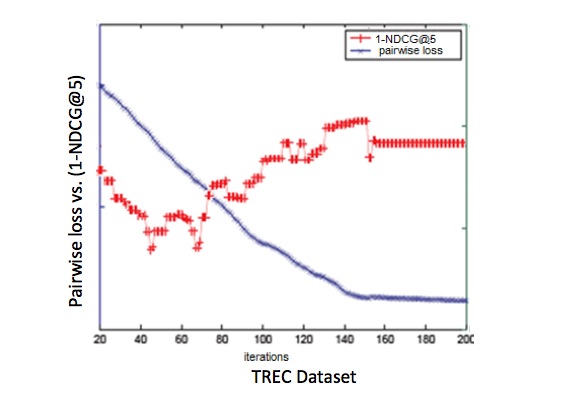
另外,有的Pairwise方法没有考虑到排序结果前几名对整个排序的重要性,也没有考虑不同查询对应的文档集合的大小对查询结果的影响(但是有的Pairwise方法对这些进行了改进,比如IR SVM就是对Ranking SVM针对以上缺点进行改进得到的算法)。
6.1.3 Listwise
与Pointwise和Pairwise方法不同,Listwise方法直接考虑给定查询下的文档集合的整体序列,直接优化模型输出的文档序列,使得其尽可能接近真实文档序列。
- 函数框架
L(F(x),y)=exp(−NDCG)
- 小结

-
Listwise算法主要包括以下几种算法:LambdaRank (NIPS 2006), AdaRank (SIGIR 2007), SVM-MAP (SIGIR 2007), SoftRank (LR4IR 2007), GPRank (LR4IR 2007), CCA (SIGIR 2007), RankCosine (IP&M 2007), ListNet (ICML 2007), ListMLE (ICML 2008) 。
相比于Pointwise和Pairwise方法,Listwise方法直接优化给定查询下,整个文档集合的序列,所以比较好的解决了克服了以上算法的缺陷。Listwise方法中的LambdaMART(是对RankNet和LambdaRank的改进)在Yahoo Learning to Rank Challenge表现出最好的性能。
7 效果评估
对于搜索结果,有多种量化搜索得分的计算方法,这里介绍NDCG和MAP。
7.1 NDCG(Normalized Discounted Cumulative Gain)
7.1.1 定义
- 计算前k条结果的相关性得分
- i:第i次搜索
- j:第j条结果
- yi,j:第j条结果的相关性标注得分,5档制
- πi(j):这条结果在排序中的位置
7.1.2 描述
- 顾名思义,NDCG的公式由 N、D、C、G 4部分组成。将公式改写成
- 先看G部分。G是增益函数(Gain),表示第j条结果在被给予评分yi,j之后所贡献的分值增益。定义如下
- 再看D部分。D是位置折算函数(Discounted)。因为不同位置的增益应该是不同的,D函数给结果按照位置赋予一个权重。定于如下
- C部分就是累加(Cumulative),将k条结果的得分加在一起。
- N是归一化因子(Normalized),取值是该位置上G函数理论上取得的最大值的倒数。目的是缩放不同位置上的得分到统一区间。
7.2 MAP(Mean Average Precision)
7.2.1 定义
- MAP中,相关性评分yi,j只有2档:0和1
7.2.2 描述
- P表示结果j的权重,从位置j开始,相关(标记为1)的结果所在的比例
- AP表示单query下,相关的结果的平均的加权得分
- AP中,只有标记为相关的结果才会参与加权的累加
- AP是单query下的得分,多query的平均AP,就成了MAP
7.3 L2R评价指标汇总
1) WTA(Winners take all) 对于给定的查询q,如果模型返回的结果列表中,第一个文档是相关的,则WTA(q)=1,否则为0.
2) MRR(Mean Reciprocal Rank) 对于给定查询q,如果第一个相关的文档的位置是R(q),则MRR(q)=1/R(q)。
3) MAP(Mean Average Precision) 对于每个真实相关的文档d,考虑其在模型排序结果中的位置P(d),统计该位置之前的文档集合的分类准确率,取所有这些准确率的平均值。
4) NDCG(Normalized Discounted Cumulative Gain) 是一种综合考虑模型排序结果和真实序列之间的关系的一种指标,也是最常用的衡量排序结果的指标,详见Wikipedia。
5) RC(Rank Correlation) 使用相关度来衡量排序结果和真实序列之间的相似度,常用的指标是Kendall's Tau。
8 参考内容
- Hang Li. Learning to Rank for Information Retrieval and Natural Language Processing
- Hang Li. A Short Introduction to Learning to Ran
- Learning to Rank 简介(潘的博客)
- Learning to Rank 小结(crackcell's dustbin)