1. HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
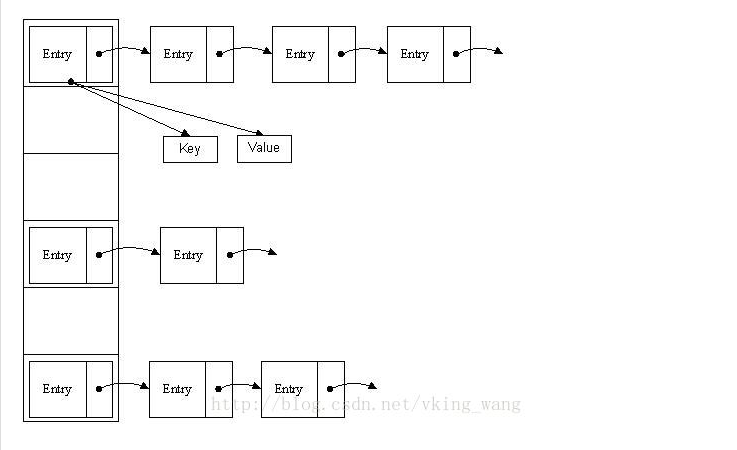
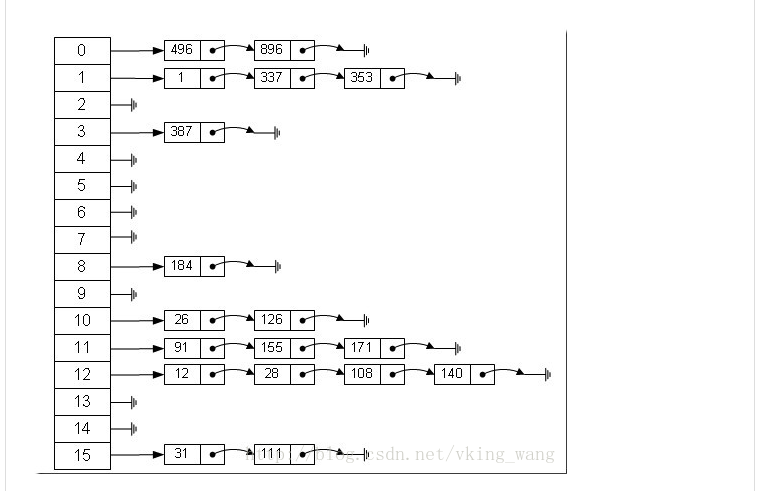
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
2. HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:

1)put
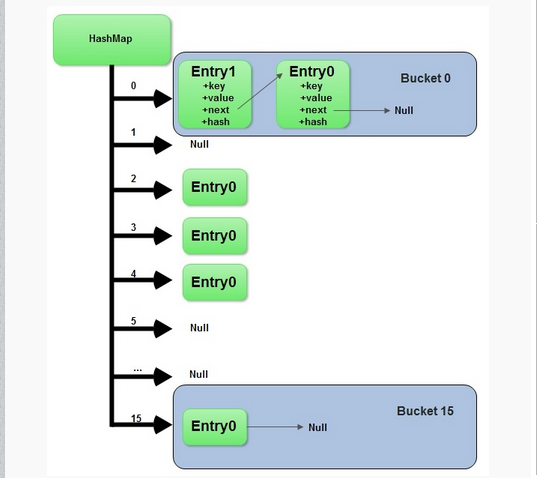
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
}
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度。
2)get
面试官常问问题及回答:
“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”
HashMap可以接受null键值和值,而HashTable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对等等。
“你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?”
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。
关于HashMap中的碰撞探测(collision detection)以及碰撞的解决方法:
“当两个对象的hashcode相同会发生什么?”
有equals()和hashCode()两个方法,两个对象就算hashcode相同,但是它们可能并不相等。因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用LinkedList存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在LinkedList中。
“如果两个键的hashcode相同,你如何获取值对象?”
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,如果有两个值对象储存在同一个bucket,找到bucket位置之后,会调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象。指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
“你了解重新调整HashMap大小存在什么问题吗?
当多线程的情况下,可能产生条件竞争(race condition)。
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在LinkedList中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
我个人很喜欢这个问题,因为这个问题的深度和广度,也不直接的涉及到不同的概念。让我们再来看看这些问题设计哪些知识点:
- hashing的概念
- HashMap中解决碰撞的方法
- equals()和hashCode()的应用,以及它们在HashMap中的重要性
- 不可变对象的好处
- HashMap多线程的条件竞争
- 重新调整HashMap的大小
总结
HashMap的工作原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用LinkedList来解决碰撞问题,当发生碰撞了,对象将会储存在LinkedList的下一个节点中。 HashMap在每个LinkedList节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的LinkedList中。键对象的equals()方法用来找到键值对。
因为HashMap的好处非常多,我曾经在电子商务的应用中使用HashMap作为缓存。因为金融领域非常多的运用Java,也出于性能的考虑,我们会经常用到HashMap和ConcurrentHashMap。你可以查看更多的关于HashMap和HashTable的文章。
/**
* 获取所有指标分值等信息(myy优化代码)
* 26274 myy
* @param comid
* @return
*/
public SimpleList getAllBusiness(int comid, String BusinessResource,int Rankid) {
SimpleList lts=new SimpleList();
HashMap<String,String>map=new HashMap<String,String>();
HashMap<String,HashMap<String,String>> lt=null;
String Busines="";
if(comid==7){
Busines = ResourceUtil.getValue("order_7", BusinessResource);
}else{
Busines = ResourceUtil.getValue("order", BusinessResource);
}
String[] Business = Busines.split(",");
lt = dao.getAllBusinessByComid(comid,Rankid);//查询相应公司中用户中职级等相关信息
for (int i = 0; i < Business.length; i++) {
SimpleHash map1=new SimpleHash();
String string = Business[i];
map=lt.get(string);//通过配置文件中的序列值获得一个HashMap,然后取其中的值并put到SimpleHash中方便页面获取,通过配置文件中的序列值获得相应的用户职级信息
if(map!=null){
map1.put("pid",map.get("pid"));
map1.put("companyid",map.get("companyid"));
map1.put("qxid",map.get("qxid"));
map1.put("score",map.get("score"));
map1.put("ywid",map.get("ywid"));
map1.put("falg",map.get("falg"));
String value = ResourceUtil.getValue(string, BusinessResource);//根据string获取配置文件中业务名称
map1.put("YWName",value);
lts.add(map1);
}
}
return lts;
}
/**
* 获取所有指标分值
* @param 26274 myy comid
* @return
*/
public HashMap<String,HashMap<String,String>> getAllBusinessByComid(int comid,int Rankid) {
HashMap<String,HashMap<String,String>> s = null;
Connection con = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
con = this.source.getConnection();
String sql = "select p.pid,p.companyid,p.qxid,p.score,p.ywid,p.falg from pffz p where p.qxid="+Rankid+" and p.companyid="
+ comid;
stmt = con.prepareStatement(sql);
rs = stmt.executeQuery();
while (rs.next()) {
if (s == null) {
s = new HashMap<String,HashMap<String,String>>();
}
HashMap<String,String> sh = new HashMap<String,String>();
sh.put("pid", rs.getInt("pid") + "");
sh.put("companyid", rs.getInt("companyid") + "");
sh.put("qxid", rs.getInt("qxid") + "");
if (rs.getDouble("score")==0) {
sh.put("score", "");
}else{
sh.put("score",rs.getDouble("score")+"");
}
sh.put("ywid", rs.getInt("ywid")+"");
sh.put("falg", rs.getInt("falg")+"");
s.put(rs.getInt("ywid")+"",sh);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (rs != null) {
rs.close();
}
} catch (Exception e) {
e.printStackTrace();
}
try {
if (stmt != null) {
stmt.close();
}
} catch (Exception e) {
e.printStackTrace();
}
try {
if (con != null) {
con.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
return s;
}