本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
2:结构
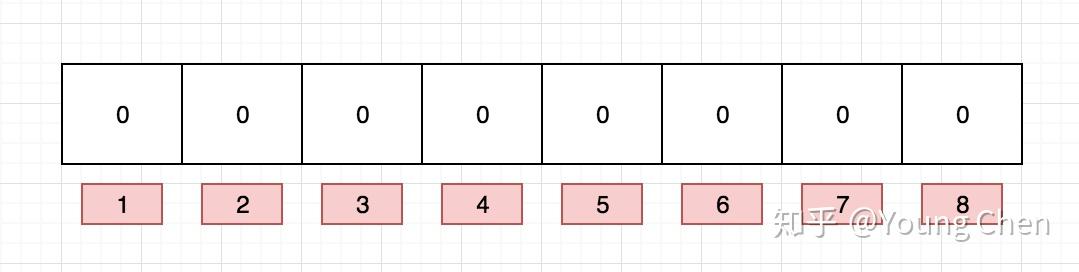
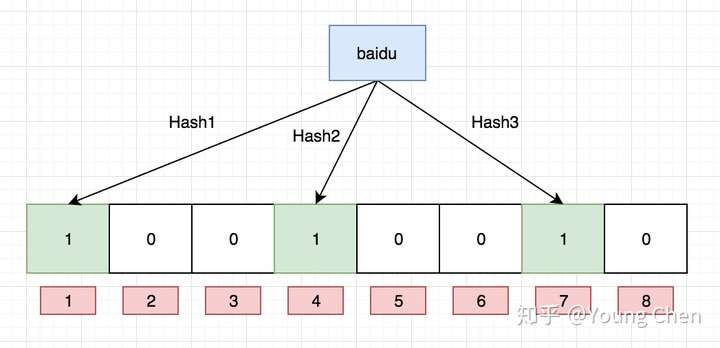
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
3:删除
传统的布隆过滤器并不支持删除操作。但是名为 Counting Bloom filter 的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。
如果希望支持进行删除操作,可以使用Counting Bloom filter,该类型的过滤器存在占用更多资源的问题。它将标准 Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的 k (k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。
4: 优点
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
5:缺点
(1):Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个key的哈希值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。但是这种方式也只能减少漏判的概率,但是不能绝对的消除。
(2):Bloom Filter无法从Bloom Filter集合中删除一个元素。因为该元素对应的位会牵动到其他的元素。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。 此外,Bloom Filter的hash函数选择会影响算法的效果。
6: 面向大Value
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。
例如根据key的hash值对bitmap求余的方式进行使用。
(1):拆分后,同一个key的哈希函数落在不同的bitMap上,这种方式同一个key在不同的节点上,会降低查询的效率。
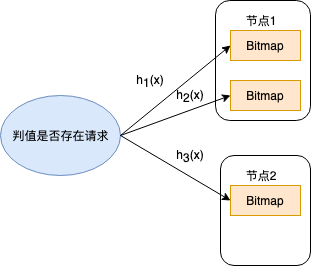
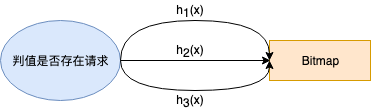
(2):拆分后,落在一个bitMap上
7:redis使用布隆过滤器可存放空间
结合Redis的BitMap能够解决,唯一需要注意的是Redis的BitMap只支持2^32大小,对应到内存也就是512MB,数组的下标最大只能是2^32-1。
不过这个限制可以通过构建多个Redis的Bitmap通过hash取模的方式分散一下即可。万分之一的误判率,512MB可以放下2亿条数据。
8:总结
(1):布隆过滤器可以应对去重的场景;