1.1 MySql优化
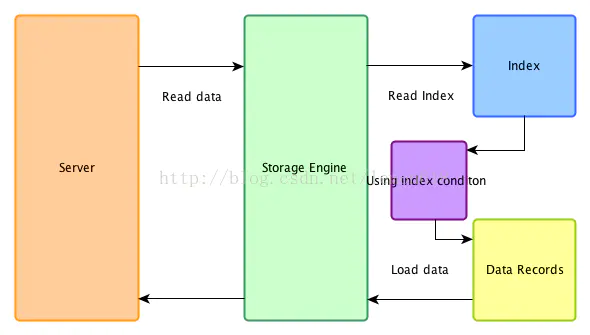
1.1.2 ICP(index condition pushdown)
自MySQL5.6引入的优化方式,只能用于二级索引(secondary index)。
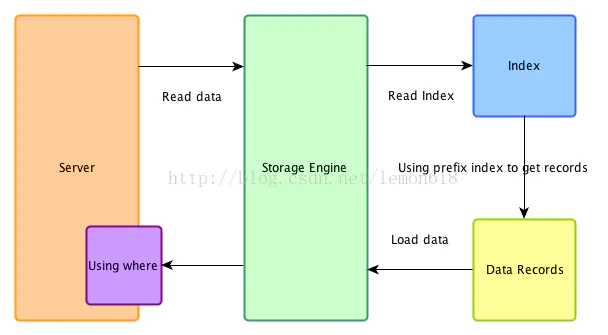
优化后:Mysql数据在取出索引同时,判断是否可以进行WHERE条件的过滤,即将过滤放置于Storage Engine进行。
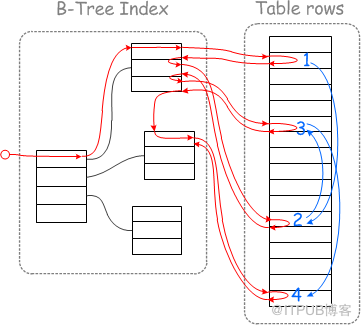
1.1.2:MRR(Multi-Range Read)
MySQL 5.6版本提供了很多性能优化的特性,其中之一就是 Multi-Range Read 多范围读(MRR) , 它的作用针对基于辅助/第二索引的查询,减少随机IO,并且将随机IO转化为顺序IO,提高查询效率。
开启之前:
开启之后:
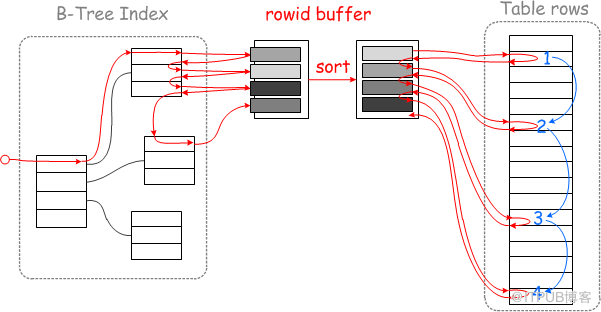
MySQL 将根据辅助索引获取的结果集根据主键进行排序,将乱序化为有序,可以用主键顺序访问基表,将随机读转化为顺序读,多页数据记录可一次性读入或根据此次的主键范围分次读入,以减少IO操作,提高查询效率。
主键顺序读取,减少缓冲池中页被替换的次数,批量处理对键值对的查询操作。
1.2 SQL优化
-
1、通过慢查日志等定位那些执行效率较低的SQL语句
-
2、explain 分析SQL的执行计划
1.2.1 使用覆盖索引
当sql语句的所求查询字段(select列)和查询条件字段(where子句)全都包含在一个索引中(联合索引),可以直接使用索引查询而不需要回表。这就是覆盖索引,
例如:10W条数据,我要从其中查出100条不连续的数据,给你id,来查name和password进行展示,如何才能高性能的去使用?
可以建立id、name、password的联合索引,直接根据索引可以查询出数据,可以减少树的搜索次数,不再需要回表查整行记录,显著提升查询性能。
1.2.2 最左匹配原则
最左前缀匹配原则:mysql会从左向右进行匹配。
例如我们定义了(name,password)两个联合索引字段,我们 使用 where name = '张三' and password = '2'索引可以生效的,当我们是颠倒了他们的顺序 使用where password = '1' and name = '王五',索引同样也是可以生效的,在mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划,我们能尽量的利用到索引时的查询顺序效率最高。
1.2.3 避免放弃使用索引而进行全表扫描
-
1:应尽量避免在 where 子句中对字段进行 null 值判断;
-
2:应尽量避免在 where 子句中使用 != 或 <> 操作符;
-
3:尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描;
-
4:in 和 not in 也要慎用,否则会导致全表扫描;
-
5:避免在 where 子句中对字段进行表达式操作或者函数操作;
表达式操作:
select id from t where num/2 = 100函数式操作:
select id from t where substring(name,1,3) = ’abc’ -–name以abc开头的id
select id from t where datediff(day,createdate,’2005-11-30′) = 0 -–‘2005-11-30’ --生成的id