元素定位主要方法:
- id定位:find_element_by_id(' ')
- name定位:find_element_by_name(' ')
- class定位:find_element_by_class_name(' ')
- tag定位:find_element_by_tag_name(' ')
- link定位:find_element_by_link_text(' ')
- partial link定位:find_element_by_partial_link_text(' ')
- xpath定位:find_element_by_xpath(' ')
- CSS定位:find_element_by_css_selector(' ')
- By定位
https://www.baidu.com/
搜索框
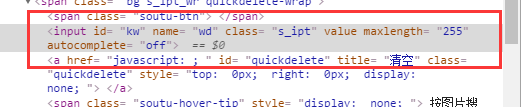
1.利用ID定位元素
from selenium import webdriver
# 设置浏览器
browser = webdriver.Chrome()
#设置浏览器大小:全屏
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
#定位百度搜索输入框之前,先分析下它的html结构
#<input type="text" class="s_ipt nobg_s_fm_hover" name="wd" id="kw" maxlength="100" autocomplete="off">
#发现它的 id="kw" ,接下来我们就通过id进行定位
try:
browser.find_element_by_id('kw').send_keys('哈哈')
print('test post:id')
except Exception as e:
print('test fail')
#输出内容:test post:id2.利用name定位元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
#搜索框的html结构:<input type="text" class="s_ipt nobg_s_fm_hover" name="wd" id="kw" maxlength="100" autocomplete="off">
# 根据name属性定位
try:
browser.find_element_by_name('wd').send_keys('哈哈')
print('test post:name')
except Exception as e:
print('test fail')
#输出内容:test post:name3.利用class定位元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
#搜索框的html结构:<input type="text" class="s_ipt nobg_s_fm_hover" name="wd" id="kw" maxlength="100" autocomplete="off">
# 根据class_name属性定位
try:
browser.find_element_by_class_name('s_ipt').send_keys('哈哈')
print('test post:class_name')
except Exception as e:
print('test fail')
#输出内容:test post:class_name4.利用tag_name定位元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
#搜索框的html结构:<input type="text" class="s_ipt nobg_s_fm_hover" name="wd" id="kw" maxlength="100" autocomplete="off">
# 根据tag_name属性定位
try:
browser.find_element_by_tag_name('form')
print('test post:tag_name')
except Exception as e:
print('test fail')
#输出内容:test post:tag_name5.利用link_text定位元素
- link_text:根据跳转链接上面的文字来定位元素。
from selenium import webdriver
browser = webdriver.Chrome()
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
# 根据link_text属性定位元素“新闻”,然后点击按钮
try:
browser.find_element_by_link_text('新闻').click()
print('test post:tag_name')
except Exception as e:
print('test fail')
#输出内容:test post:link_text6.利用partial_link_text定位元素
- 和link_text定位元素差不多,partial_link_text是通过文字信息中的部分字段来定位元素。
from selenium import webdriver
browser = webdriver.Chrome()
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
# 根据partial_link_text属性定位元素“新闻”,然后点击按钮
try:
browser.find_element_by_partial_link_text('闻').click()
print('test post:tag_name')
except Exception as e:
print('test fail')
#输出内容:test post:partial_link_text7.利用xpath定位元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
# 根据xpath定位元素
try:
browser.find_element_by_xpath('//*[@id="kw"]').send_keys('哈哈')
print('test post:xpath')
except Exception as e:
print('test fail')
#输出内容:test post:xpath
比如:

xpath = "//a[@class='nav-link' and @data-route='store/storeList']"
注意标签为 “a”
其他例子:
button

xpath = "//button[@class='btn red-diy pull-right']"
input

xpath = "//input[@value='我是总部管理者']"
8.利用CSS定位页面元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.maximize_window()
#打开百度首页
browser.get('https://www.baidu.com/')
# 根据css_selector定位元素
try:
browser.find_element_by_css_selector('#kw').send_keys('哈哈')
print('test post:xpath')
except Exception as e:
print('test fail')
#输出内容:test post:css_selector
By定位 :例子,百度页面

#导入By类
from selenium.webdriver.common.by import By- 那么上面的方法还可以改写为:
browser.find_element(By.ID,'kw')
browser.find_element(By.NAME,'wd')
browser.find_element(By.CLASS_NAME,'s_ipt')
browser.find_element(By.TAG_NAME,'form')
browser.find_element(By.LINK_TEXT,'新闻')
browser.find_element(By.PARTIAL_LINK_TEXT,'闻')
browser.find_element(By.XPATH,'//*[@id="kw"]')
browser.find_element(By.CSS_SELECTOR,'#kw')