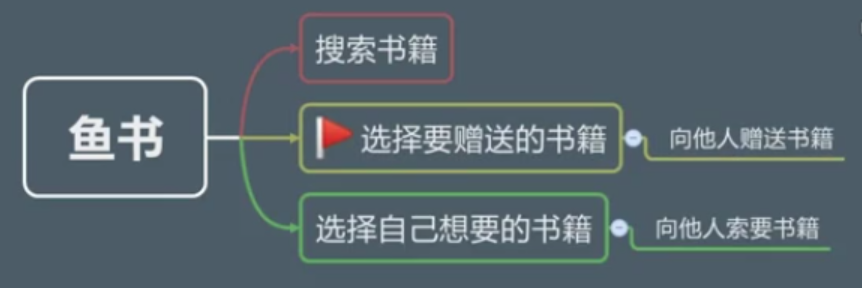
要完成是这样一个网站:http://www.yushu.im/,该网站主要是赠送书的一个平台(公益性的)
网站框架功能:
网站的搭建
前期准备(用pycharm直接创建应该也可以,感觉直接创简单)
新建文件夹,创建虚拟环境(创建虚拟环境的好处就不说了),安装需要的包。
1)安装pipenv包,pip install pipenv
2) 在项目文件下用pipenv创建虚拟环境,pipenv install

3)按照提示pipenv shell进入虚拟环境

进入虚拟环境后发现只有虚拟环境提供的包:

4)安装一些需要的包,首先flask,这时候安装不是pip,是pipenv install flask
关于虚拟环境pipenv
进入:pipenv shell
退出:exit
安装与卸载包:pipenv install 包名,pipenv uninstall 包名
查看包的安装关系: pipenv graph 详细看gitHub官方文档。
5)开发工具
pycharm,数据库mysql(直接安装Xampp),Navicat(数据库可视化管理工具),安装过程略
热身,补知识:
1)建立文件config.py作为配置文件,在主文件夹中肯定要导入配置文件,一般是from。flask有一个高尚的方法

业务代码开始
书籍搜索:
一般支持三种搜索方式:书名(精准与模糊),作者,ISBN
也可说两种:关键字检索,ISBN号检索
1)搜索的数据哪里来?
数据库?当然不是,没有这么多。这里依靠外部的API完成
图书数据的基地址:http://t.yushu.im
关键字搜索:http://t.yushu.im/v2/book/search?q={}&start={}&count={} 解释三个参数:q传递关键字,因为返回很多记录,start与count控制分页
ISBN搜索:http://t.yushu.im/v2/book/isbn/{isbn}
也可以用豆瓣API:http://api.douban.com/v2/book (此博客用的是上面api,豆瓣的API有访问频率控制)
为了方便编程,理解一下isbn,他有两种形式,isbn13(13个数字组成);isbn10(10个数字组成,不过中间可能含有‘ - ’)
为了方便阅读等好处:建立文件夹helper,放一些被调用的函数。


#!/usr/bin/env python #-*-coding:utf-8 -*- ''' 编写一些函数,用于调用 ''' def is_isbn_or_key(word): """ 判读输入的参数是关键还是isbn,isbn有两种,isbn10,isbn13 :param word: q :return: 'key' 或者 ‘isbn’ """ isbn_or_key = 'key' if len(word) == 13 and word.isdigit(): isbn_or_key = 'isbn' short_word= word.replace('-', '') if '-' in word and len(short_word)==10 and short_word.isdigit(): isbn_or_key = 'isbn' return isbn_or_key
这样视图函数就比较干净:(当然还没写完)
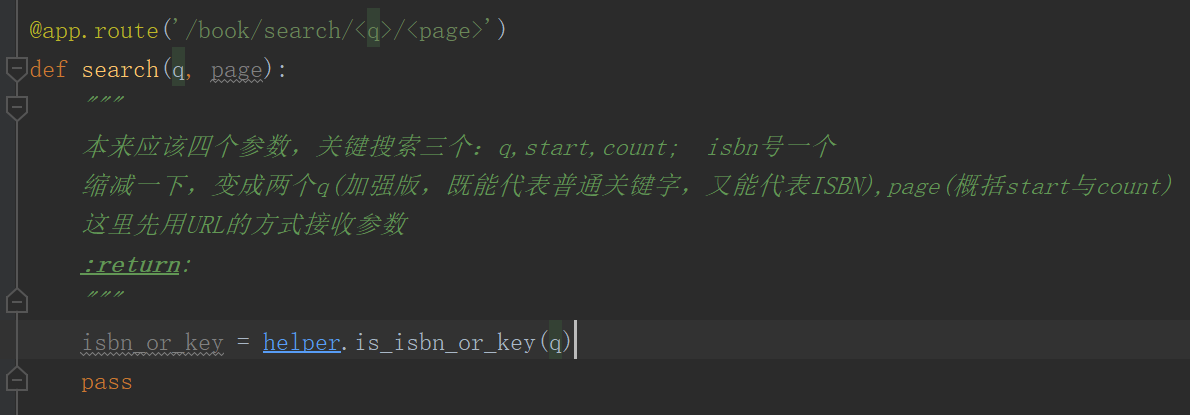
如何在python代码中调用上面的外部API(按照restful标准来的)?
先观察API返回的数据类型,找一个isbn编号为9787501524044,访问http://t.yushu.im/v2/book/isbn/9787501524044,发现是json格式。
但是当我们输入错误数据时(isbn错误),返回{"msg": "book not found", "code": 2000}。所以这种异常也要考虑。HTTP 200表示成功
写一个http请求函数(放在http.py中)
# 两种http请求,urllib(from urllib import request)与requests import requests class HTTP: @staticmethod def get(url, return_json=True): r = requests.get(url) # 因为我们调用的API是get型,json型 if r.status_code != 200: return {} if return_json else '' return r.json() if return_json else r.text # 与上面等价 # if r.status_code == 200: # if return_json: # return r.json() # else: # return r.text() # else: # if return_json: # return {} # else: # return ''
请求API之前,要拿到url,所以还要写一个函数拼接url,并且调用上面的请求函数,拿到结果给视图函数search()用.这里先简单一点,默认关键字搜索的后面两个参数。
#!/usr/bin/env python #-*-coding:utf-8 -*- from http import HTTP class YuShuBook: isbn_url = 'http://t.yushu.im/v2/book/isbn/{} ' keyword_url = 'http://t.yushu.im/v2/book/search?q={}&start={}&count={}' @classmethod def search_by_isbn(cls, isbn): url = cls.isbn_url.format(isbn) result = HTTP.get(url) # python中将json转化为dict return result @classmethod def search_by_keyword(cls, keyword, count=15,start=0): url = cls.keyword_url.format(keyword, count, start) result = HTTP.get(url) return result
因此,此时的搜索的视图函数为(未写完),进一步整理,将所有视图函数放在app文件夹下对应的文件夹,这里放在web文件下book.py中。因为启动文件要干净。
def search(q, page): isbn_or_key = helper.is_isbn_or_key(q) if isbn_or_key == 'isbn': result = YuShuBook.search_by_isbn(q) else: result = YuShuBook.search_by_keyword(q) return jsonify(result)
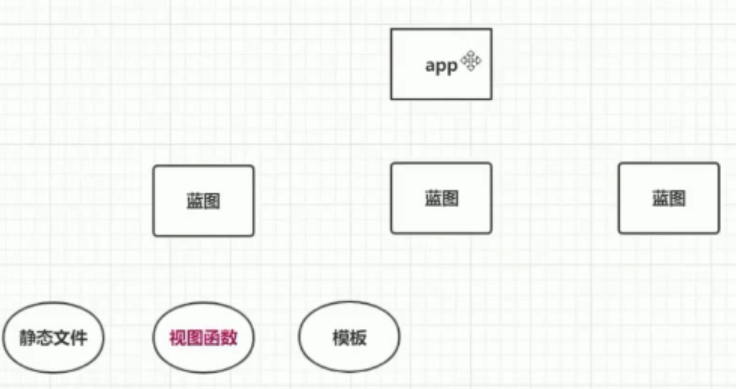
将试图函数放在其他文件中,@app.toute()报错怎么解决。这里要用到flask的蓝图。flask核心对象app就像一个插座,蓝图不能独立存在,它必须插入flask核心对象中的。蓝图是如何解决视图函数分文件的尼?我们可以注册多个蓝图,然后将不同的视图函数注册到不同的蓝图中。虽然app是万能插座,视图函数也可以直接注册到app中,但是不好,不方便阅读管理的等等。