【1】 诊断的作用

【2】过拟合

【3】

【4】

高偏差bias,欠拟合underfitting
高方差variance,过拟合overfitting
【5】参数λ
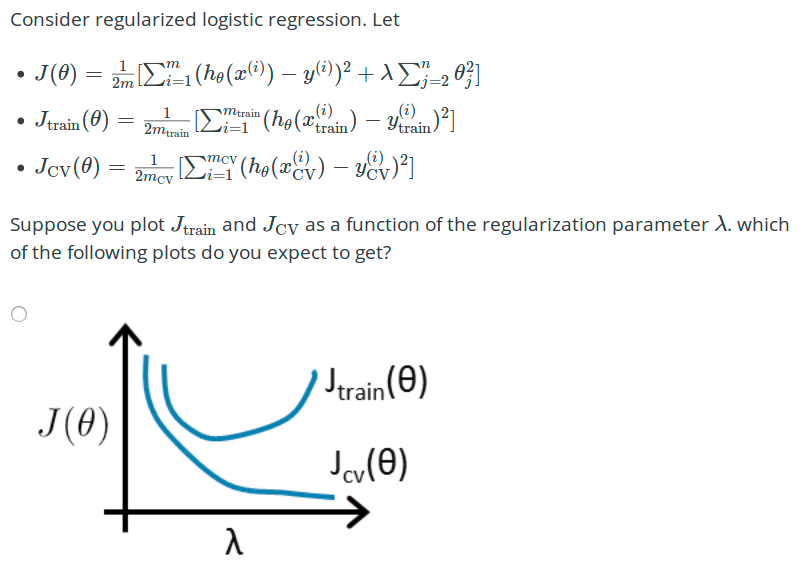

Answer: λ太大,则参数都被惩罚,导致欠拟合,两个J都大。 λ太小,则欠拟合,Jtrain 小,Jcv大。
【6】

Answer:过拟合的时候,增加训练集有用。
【7】

Answer:过拟合,增加 hidden 层数无用。
-------------------------------------- 下面是Lecture 11 的内容
【8】
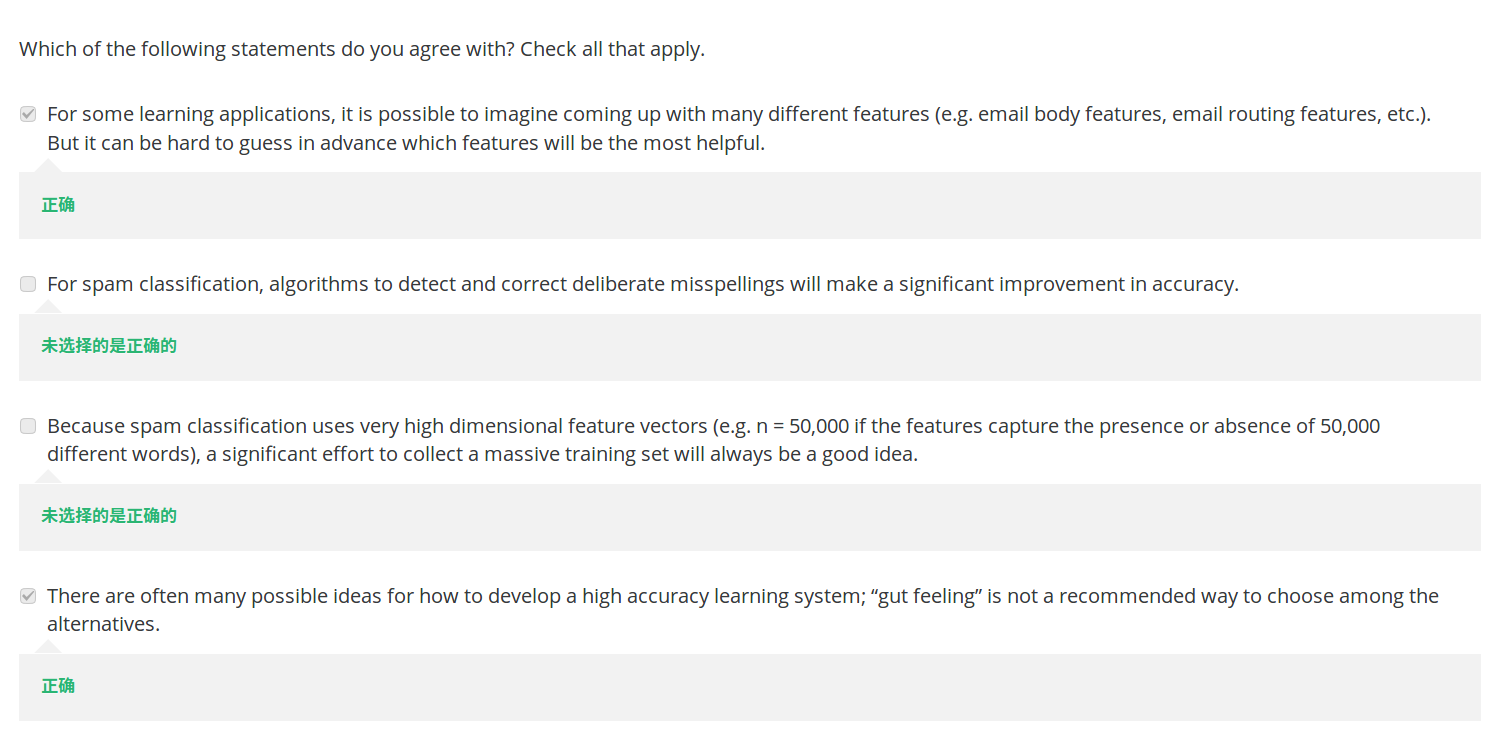
Answer:
A 正确。不容易猜测哪个feature是最有用的
B 错误。是一种方法,significant improve 不一定
C 错误。 是一种方法,always be good 不一定
D 正确。gut feeling直觉,不推荐只根据直觉判断。
【9】Jtest 和 Jcv

【10】错误度量
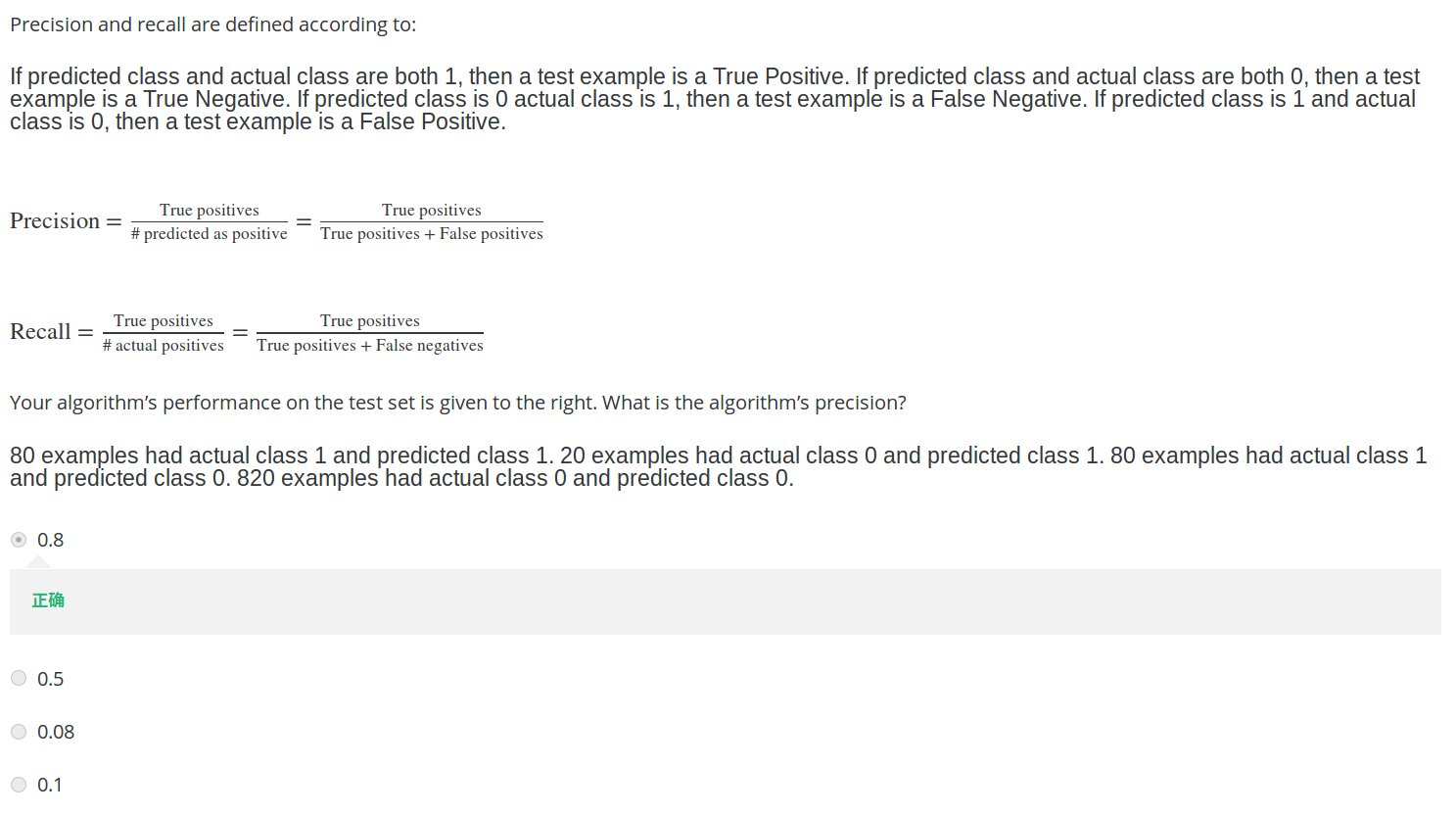
Answer: Precision = 80/(20+80) = 0.8, Recall = 80/(80+80) = 0.5
【11】 F1 score

【12】大数据集

Answer:如果数据所含的信息很少,增大数据集也不能解决问题。
测验

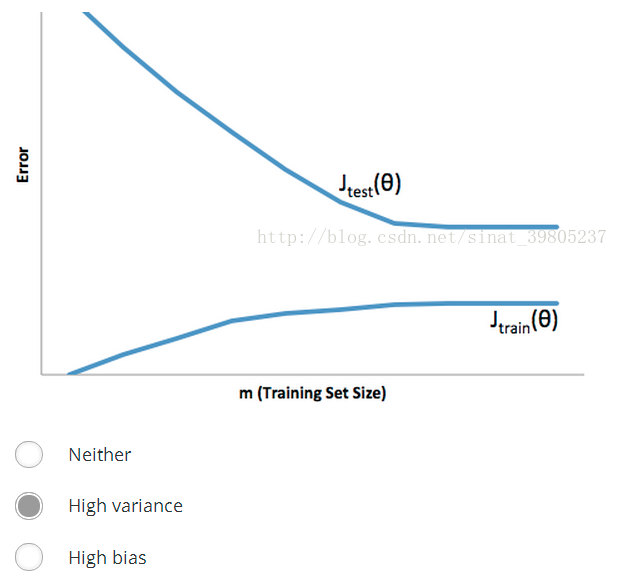
Answer:第一个欠拟合,两个误差都大。第二个过拟合,train小,cv大。

Answer:BC,过拟合:使用小的特征集, 增大λ。
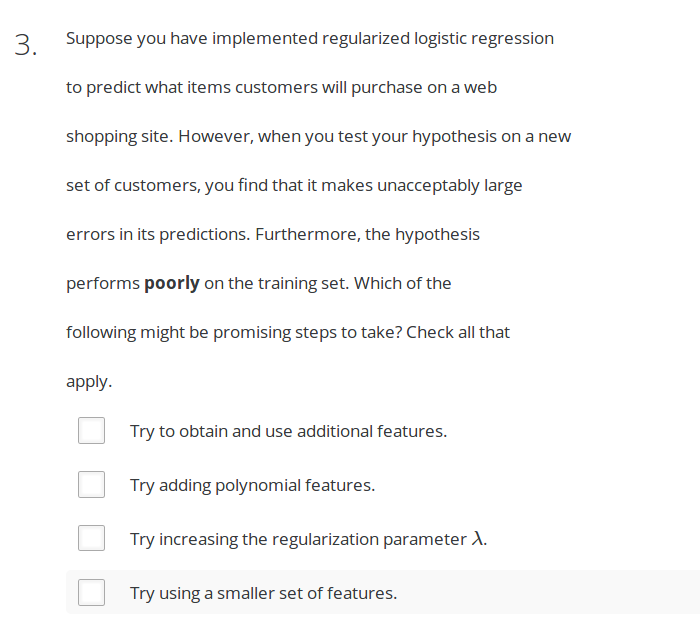
Answer:AB,欠拟合:增大特征集, 增加多项式次数,减小λ。

Answer:AD



Answer:ABCF
A 高偏差,欠拟合说明模型不好,应该增加feature
C 参数过多,更容易过拟合
D 错误。增加 hidden 数,不能解决过拟合
E 错误。欠拟合,通过增加feature可以优化
F 过拟合,通过增加训练集可以优化
--------------- 下面是Lecture11 的内容
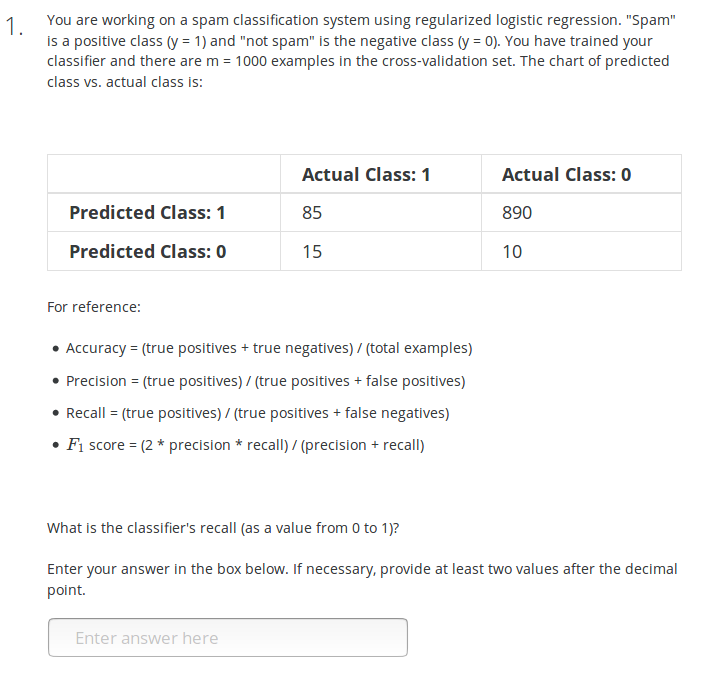
Answer: recall=85/(85+15)=0.85
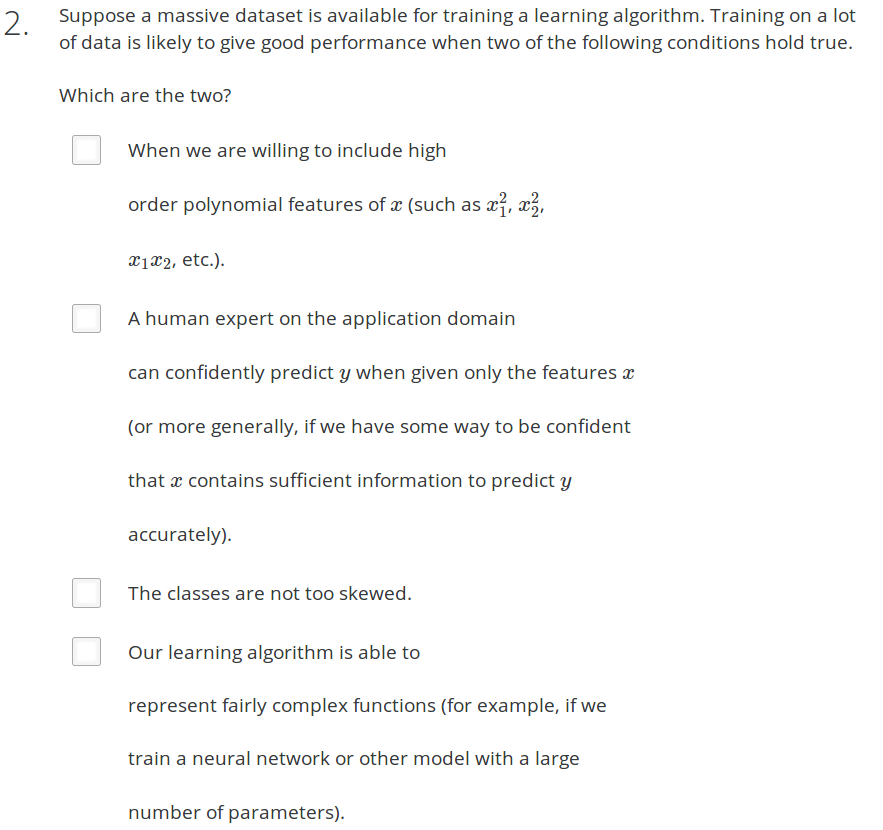
Answer: BD
A 错误。如果features太少,多加入polynomial features 也不能够完全模拟出训练样本的特征。就像预测房价,只用房子面积这一个特征,再加上面积1次方,2次方组成的polynomial,就算训练样本再多,也不能预测出正确的房价
B 正确 给专家一个x feature就可以准确的预测出y. 即所选的特征x含有足够的信息来准确预测y
C
D 正确。我们的学习算法能够表示相当复杂的功能(例如,训练神经网络或其他具有大量参数的模型)。模型复杂,表示复杂的函数,此时的特征多项式可能比较多,能够很好的拟合训练集中的数据,使用大量的数据能够很好的训练模型。

Answer:D
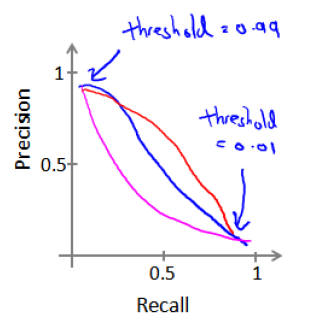
threshould 设定越低,查准率precision越低、查全率recall越高,因为更多负例被判断为正例。
threshould 设定越高,查准率precision越高、查全率recall越低,因为有更多正例被漏掉。


Answer:ACDFG
- Accuracy = (true positives + true negatives) / (total examples)
- Precision = (true positives) / (true positives + false positives)
- Recall = (true positives) / (true positives + false negatives)
- F1 score = (2 * precision * recall) / (precision + recall)
A 正确。好的模型应该同时具有较高的precision和recall
B 错误。表现应该类似
C 正确。如果都判断为非垃圾邮件,recall=0/(0+99)=0,precision=0/(0+1)=0,accurancy=(0+99)/100 = 0.99
D 正确。交叉验证集合和训练集来源相同,表现应该类似。
E 错误。如果都判断为垃圾邮件,recall=1/(1+0)=1,precision=1/(99+1)=0.01
F 正确。同C
G 正确。同E

Answer:DEF
A 错误。不应该开始就花大量时间去收集大量数据,而应该有重点地收集有用数据
B 错误。模型欠拟合,多收集数据没有帮助。如果模型太简单、特征太少,则应该增加多项式特征,而不是收集数据
C 错误。因为可能存在偏斜数据集,最终阈值不一定是0.5
D 正确。手动检查分类错误的数据会有帮助
E 正确。使用特别大的数据集合能避免过拟合
F 正确。在很偏斜的数据集上,应该使用F1 值,而不是使用accuracy