urllib是python自带库,不要专门安装,还挺好用的。
脚本语言的好处之一就是随写随用,有些东西用C语言写真的是能把人累死,换成python就是几行代码,so easy,对于喜欢偷懒的同学绝对是上帝的礼物~~~
目前我用到的两个常用函数是urlopen, read, urlretrieve这三个函数,讲一下简单的功能,看其他的请移步https://docs.python.org/2/library/urllib.html#urllib.urlopen。
urlopen函数可以用来打开http的网页链接,挺好用的,然后read函数能够直接获取html文本。样例脚本如下:
1 import urllib 2 3 url_obj = urllib.urlopen ( 'http://www.cnblogs.com/' ) 4 htmlfile = url_obj.read ()
代码只有2行,第一行是打开这个网站,第二行是直接获取html的文件,操作流程很简单,有这个基础,组织下数据存储,搞个网页爬虫的基础就有了。
然后在网上看了下,有这样一段代码,用来扒网站上图片的:
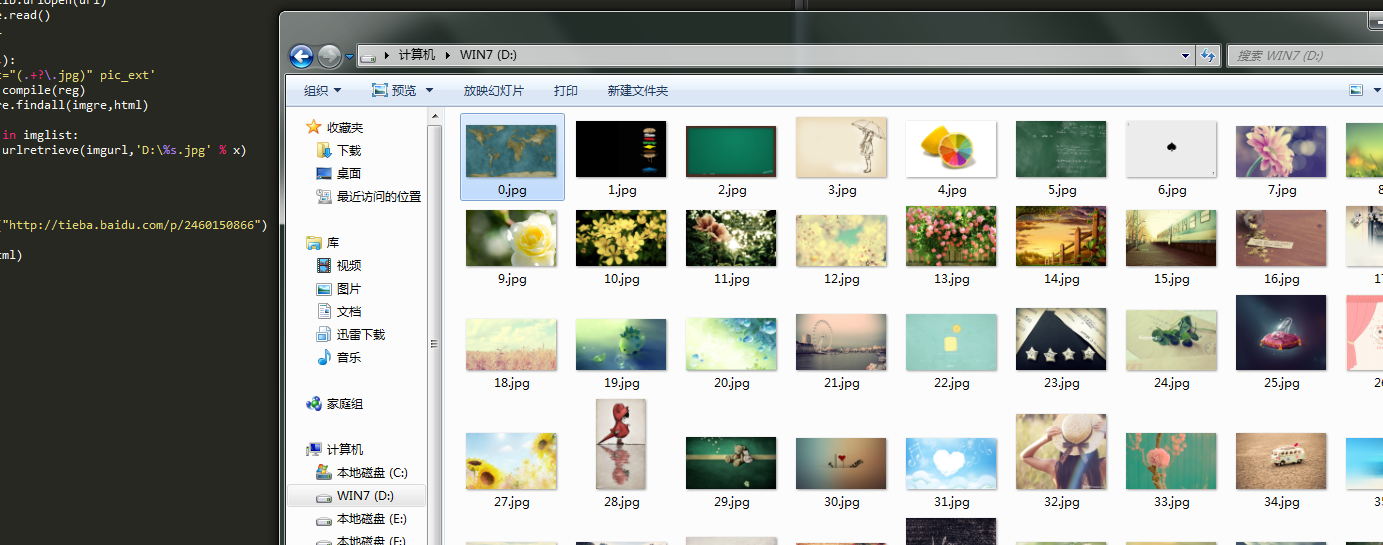
1 #coding=utf-8 2 import urllib 3 import re 4 5 def getHtml(url): 6 page = urllib.urlopen(url) 7 html = page.read() 8 return html 9 10 def getImg(html): 11 reg = r'src="(.+?.jpg)" pic_ext' 12 imgre = re.compile(reg) 13 imglist = re.findall(imgre,html) 14 x = 0 15 for imgurl in imglist: 16 urllib.urlretrieve(imgurl,'%s.jpg' % x) 17 x+=1 18 return x 19 20 21 html = getHtml("http://tieba.baidu.com/p/2460150866") 22 23 print getImg(html)
上面这段示例代码水平写得挺不错的,应该是经常使用python的高手写的,没什么多余的东西,刀刀入肉。python网站上写的这个函数介绍。

在urlretrieve函数中如果只传入两个参数,那么第二个参数将作为文件名,保存在python脚本文件所在的路径下。应该也是支持绝对路径的。试验了一下,确实支持。
研究了下这个函数的入参格式,也是httphttps格式开头的url:

然后看了下代码的格式,写正则表达式的时候,用了(),应该是通过这个取出来的,python的正则表达式之前用过,已经过去好久了。
