一、resize的源码
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
重点代码
Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; }
而 newTab[j + oldCap] = hiHead;这一步,是一个非常巧妙的地方,
解释
经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,经过rehash之后,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。对应的就是下方的resize的注释。

看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希值(也就是根据key1算出来的hashcode值)与高位与运算的结果。

因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。
由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,而JDK1.8不会倒置。
为什么刚好原位置+原数组长度就会等于新的数组中的位置呢?
假设某个元素的hashcode为52:

而假设某个元素的hashcode为100:

jdk1.7 中resize() ,重新计算存放的位置代码
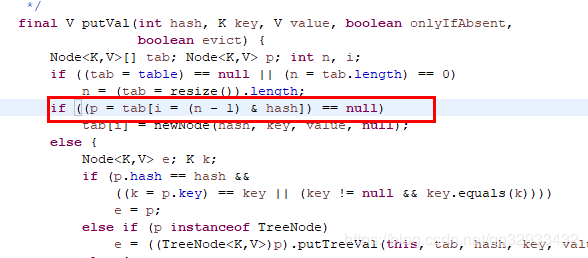
而在jdk1.8中
16扩容后变成32.那么1.7中计算元素的位置方式为 31&52, 31&100.我们把他与扩容前的15&52。15&100做对比看看
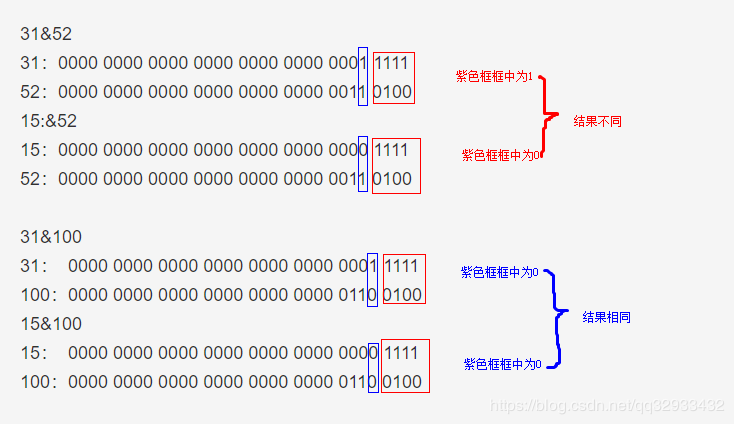
可以看到,扩容前和扩容后的位置是否一样完全取决于多出来的那一位是与新数组计算后值是为0还是1.为0则新位置与原位置相同,不需要换位置,不为零则需要换位置。而为什么新的位置是原位置+原数组长度,是因为每次换的位置只是前面多了一个1而已。为什么是前面多1,因为数组扩容为原来的两倍也是高位进1,比如15是0000 1111,而31就是0001 1111. 那么新位置的变化的高位进1位。而每一次高位进1都是在加上原数组长度的过程。
正好1+2=3 3+4=7 7+8=15 。也就验证了新的位置为原位置+原数组长度。

参考:https://www.jianshu.com/p/9e5d235b4ade
总结
jdk1.8中在计算新位置的时候并没有跟1.7中一样重新进行hash运算,而是用了原位置+原数组长度这样一种很巧妙的方式,而这个结果与hash运算得到的结果是一致的。
并且1.7中resize()使用的是头插法的形式,多线程并发下容易造成 Entry链表的闭环,查询数据时出现死循环。
1.8采用的是尾插法,虽然用多了一些内存空间,但是避免了出现死循环的情况。