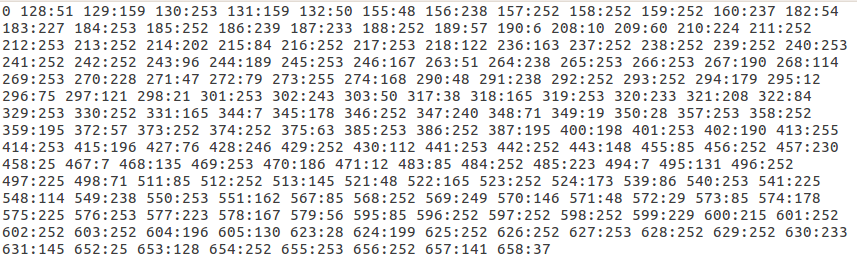
Spark MLlib 的官方例子里面提供的数据大部分是 libsvm 格式的。这其实是一种非常蛋疼的文件格式,和常见的二维表格形式相去甚远,下图是里面的一个例子:
完整代码
libsvm 文件的基本格式如下:
<label> <index1>:<value1> <index2>:<value2>…
label 为类别标识,index 为特征序号,value 为特征取值。如上图中第一行中 0 为标签,128:51 表示第 128 个特征取值为 51 。
Spark 固然提供了读取 libsvm 文件的API,然而如果想把这些数据放到别的库 (比如scikit-learn) 中使用,就不得不面临一个格式转换的问题了。由于 CSV 文件是广大人民群众喜闻乐见的文件格式,因此分别用 Python 和Java 写一个程序来进行转换。我在网上查阅了一下,基本上全是 csv 转 libsvm,很少有 libsvm 转 csv 的,唯一的一个是 phraug库中的libsvm2csv.py 。但这个实现有两个缺点: 一个是需要事先指定维度; 另一个是像上图中的特征序号是 128 - 658 ,这样转换完之后 0 - 127 维的特征全为 0,就显得多余了,而比较好的做法是将全为 0 的特征列一并去除。下面是基于 Python 的实现:
import sys
import csv
import numpy as np
def empty_table(input_file): # 建立空表格, 维数为原数据集中最大特征维数
max_feature = 0
count = 0
with open(input_file, 'r', newline='') as f:
reader = csv.reader(f, delimiter=" ")
for line in reader:
count += 1
for i in line:
num = int(i.split(":")[0])
if num > max_feature:
max_feature = num
return np.zeros((count, max_feature + 1))
def write(input_file, output_file, table):
with open(input_file, 'r', newline='') as f:
reader = csv.reader(f, delimiter=" ")
for c, line in enumerate(reader):
label = line.pop(0)
table[c, 0] = label
if line[-1].strip() == '':
line.pop(-1)
line = map(lambda x : tuple(x.split(":")), line)
for i, v in line:
i = int(i)
table[c, i] = v
delete_col = []
for col in range(table.shape[1]):
if not any(table[:, col]):
delete_col.append(col)
table = np.delete(table, delete_col, axis=1) # 删除全 0 列
with open(output_file, 'w') as f:
writer = csv.writer(f)
for line in table:
writer.writerow(line)
if __name__ == "__main__":
input_file = sys.argv[1]
output_file = sys.argv[2]
table = empty_table(input_file)
write(input_file, output_file, table)
以下基于 Java 来实现,不得不说 Java 由于没有 Numpy 这类库的存在,写起来要繁琐得多。
import java.io.*;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class LibsvmToCsv {
public static void main(String[] args) throws IOException {
String src = args[0];
String dest = args[1];
double[][] table = EmptyTable(src);
double[][] newcsv = NewCsv(table, src);
write(newcsv, dest);
}
// 建立空表格, 维数为原数据集中最大特征维数
public static double[][] EmptyTable(String src) throws IOException {
int maxFeatures = 0, count = 0;
File f = new File(src);
BufferedReader br = new BufferedReader(new FileReader(f));
String temp = null;
while ((temp = br.readLine()) != null){
count++;
for (String pair : temp.split(" ")){
int num = Integer.parseInt(pair.split(":")[0]);
if (num > maxFeatures){
maxFeatures = num;
}
}
}
double[][] emptyTable = new double[count][maxFeatures + 1];
return emptyTable;
}
public static double[][] NewCsv(double[][] newTable, String src) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(src)));
String temp = null;
int count = 0;
while ((temp = br.readLine()) != null){
String[] array = temp.split(" ");
double label = Integer.parseInt(array[0]);
for (String pair : Arrays.copyOfRange(array, 1, array.length)){
String[] pairs = pair.split(":");
int index = Integer.parseInt(pairs[0]);
double value = Double.parseDouble(pairs[1]);
newTable[count][index] = value;
}
newTable[count][0] = label;
count++;
}
List<Integer> deleteCol = new ArrayList<>(); // 要删除的全 0 列
int deleteColNum = 0;
coll:
for (int col = 0; col < newTable[0].length; col++){
int zeroCount = 0;
for (int row = 0; row < newTable.length; row++){
if (newTable[row][col] != 0.0){
continue coll; // 若有一个值不为 0, 继续判断下一列
} else {
zeroCount++;
}
}
if (zeroCount == newTable.length){
deleteCol.add(col);
deleteColNum++;
}
}
int newColNum = newTable[0].length - deleteColNum;
double[][] newCsv = new double[count][newColNum]; // 新的不带全 0 列的空表格
int newCol = 0;
colll:
for (int col = 0; col < newTable[0].length; col++){
for (int dCol : deleteCol){
if (col == dCol){
continue colll;
}
}
for (int row = 0; row < newTable.length; row++){
newCsv[row][newCol] = newTable[row][col];
}
newCol++;
}
return newCsv;
}
public static void write(double[][] table, String path) throws FileNotFoundException {
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(path)));
try{
for (double[] row : table){
int countComma = 0;
for (double c : row){
countComma ++;
bw.write(String.valueOf(c));
if (countComma <= row.length - 1){
bw.append(',');
}
}
bw.flush();
bw.newLine();
}
} catch (IOException e){
e.printStackTrace();
} finally {
try{
if (bw != null){
bw.close();
}
} catch (IOException e){
e.printStackTrace();
}
}
}
}
/