学习目标
- Understand the challenges of Object Localization, Object Detection and Landmark Finding
-
Understand and implement non-max suppression
-
Understand and implement intersection over union
-
Understand how we label a dataset for an object detection application
-
Remember the vocabulary of object detection (landmark, anchor, bounding box, grid, ...)
Objective Localization
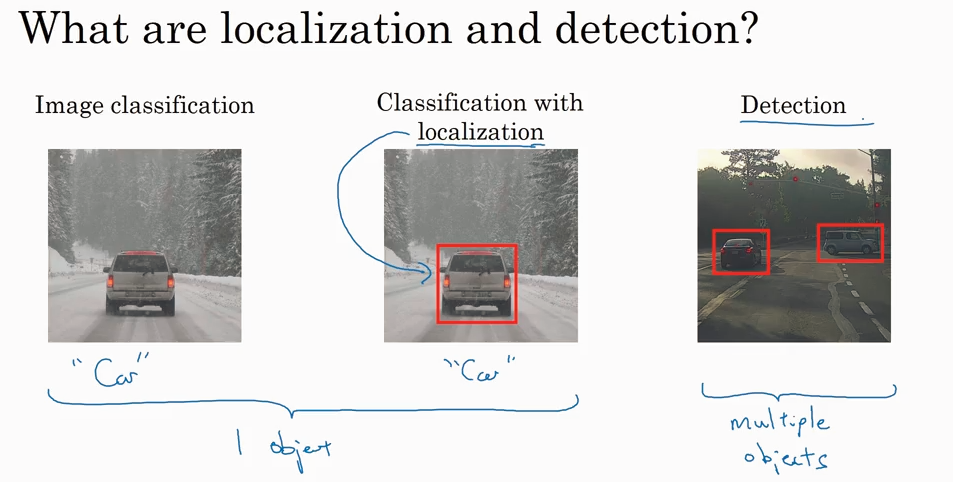
分类,分类加定位,检测。前两种问题都是针对一个object, detection 是针对多个object
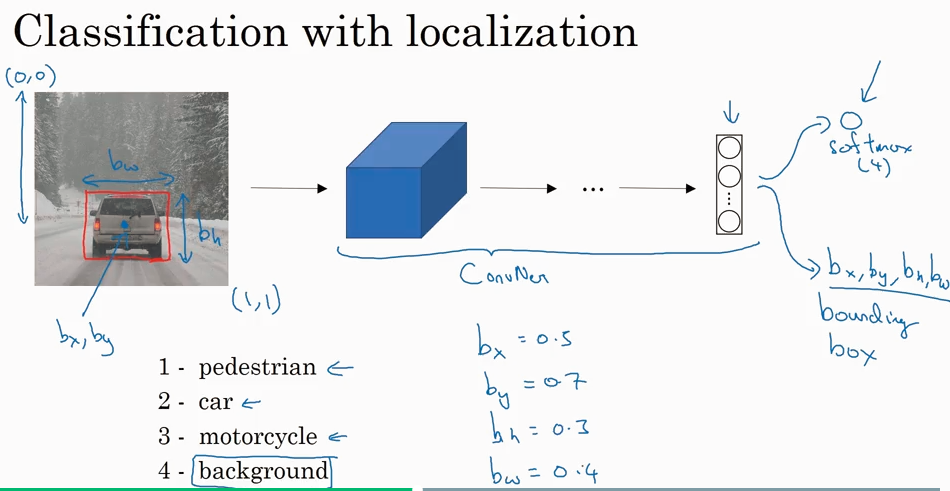
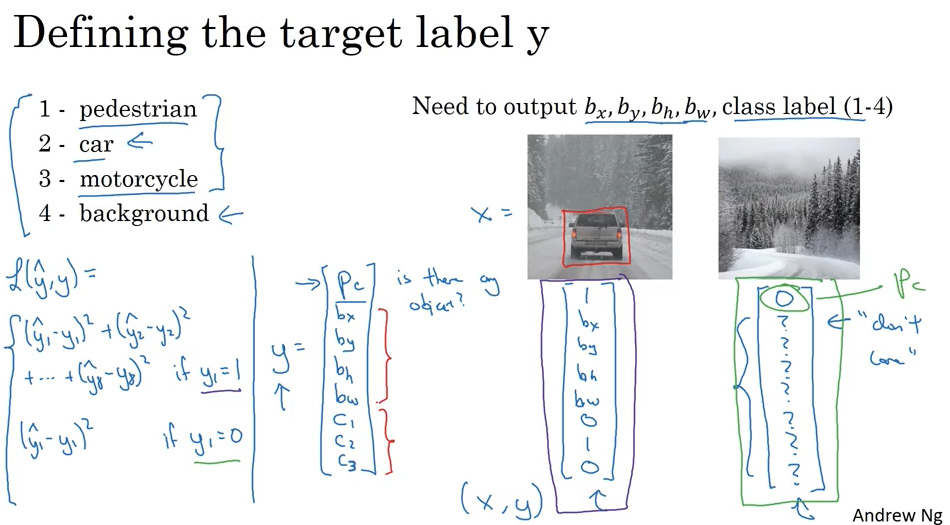
在classification with localization 问题中,就是在output 的 softmax 输出的基础上在加了4个参数来定位bounding box.
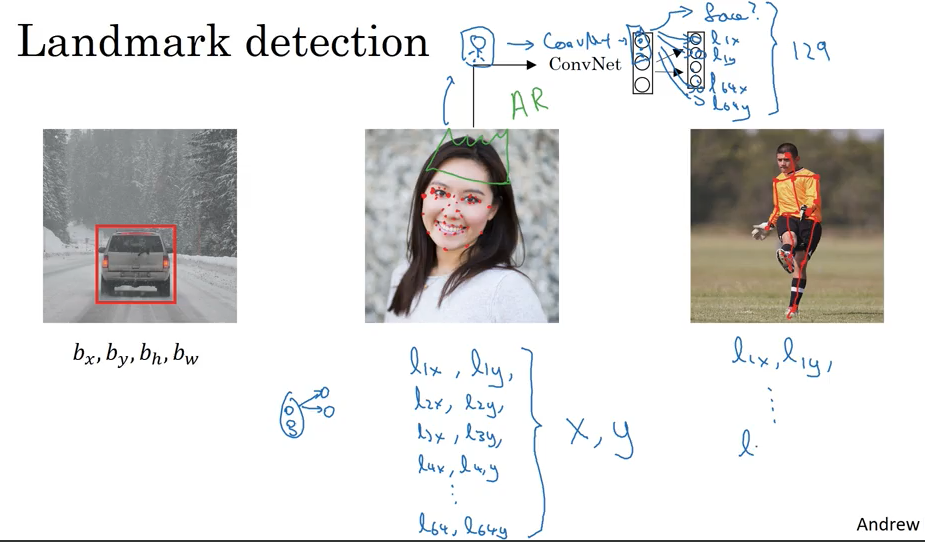
Landmark detection
Object detection


Sliding windown detection 算法最大的缺点是computational cost. 在早期人们用简单的线性分类器去分类的时候还好,现在用conv net 去分类尤其在stride 很小的情况下就cost太高了。幸运的是这个问题有办法解决. 接着往下看
Convolutional implementation of Sliding Windows
下图表示了怎么把fully connected layer 转化为convolutional layer.
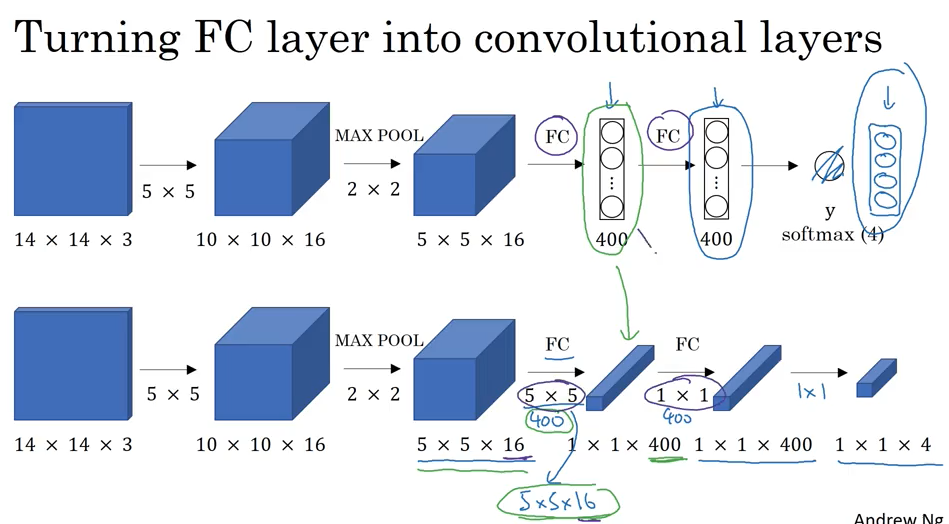
下面显示4次计算高度重复,下图第二行演示了使用第一行训练出来的filter parameter 去预测label,这样可以利用图像的share的重合的部分,极大提高计算效率。Convolutional 实现可以一次性求出结果而不是循环很多次.
现在还剩一个问题就是只考虑了分类问题没有考虑定位localization问题. 那么怎么定位呢,我们很容易想到前面介绍的classification+localization, 请继续往下看。
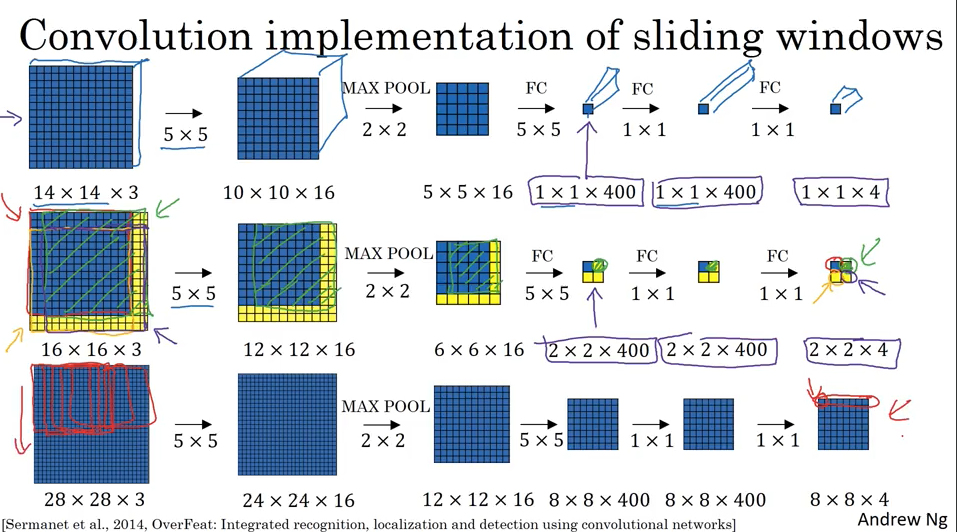
下图演示了用3x3的分割来做分类和定位,实际工作中会更细的分割,比如19x19。
一个对象的midpoint在哪个cell里,就说这个对象属于哪个cell.
YOLO 算法
YOLO 算法就是前面介绍的知识点的集成,对每一个小方框使用了classification+localization, 然后对整个9个小方框并没有循环,而是使用了convolutional 实现一次性计算。
YOLO 算法能更精确的预测bounding box. 因为解决了不能正好框住object的问题.
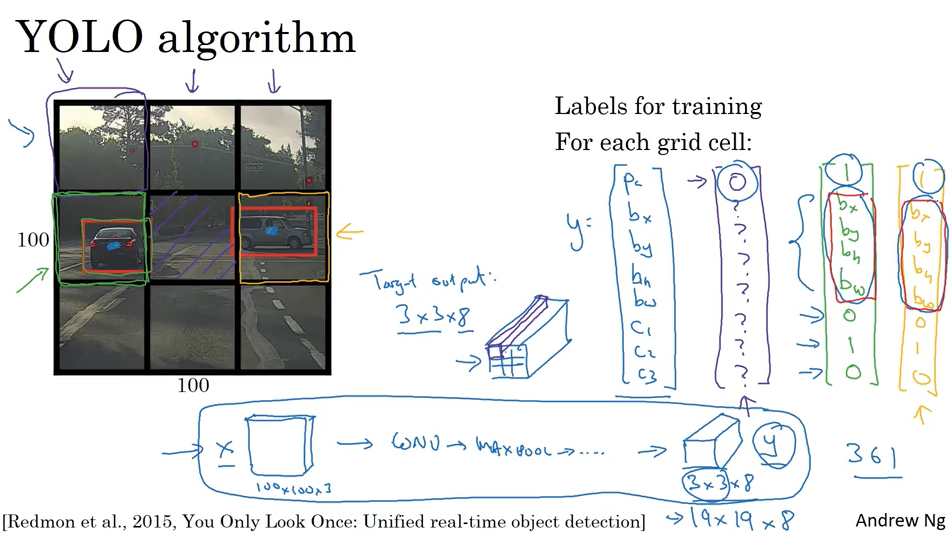
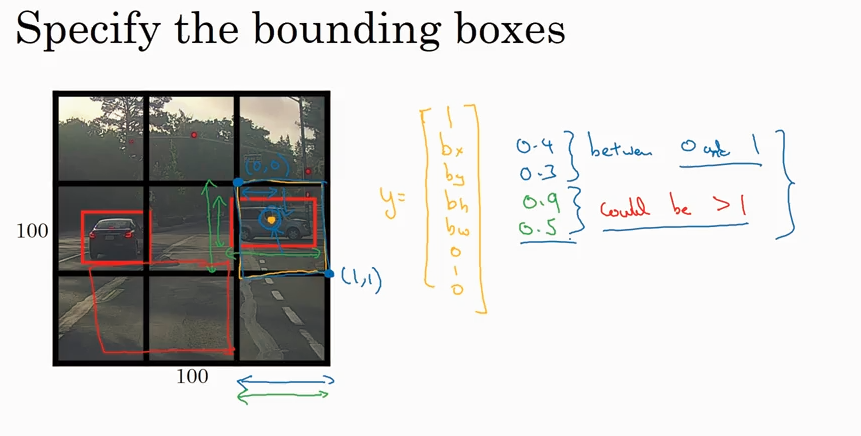
bounding box 的encoding. bh, bw 是和小框边长的比例,可以>1.
IoU (Intersection over Union)

Non-max suppression
解决同一个对象被多次检测到的情况, 去除那些可能性小的bounding box 只留下最可能的


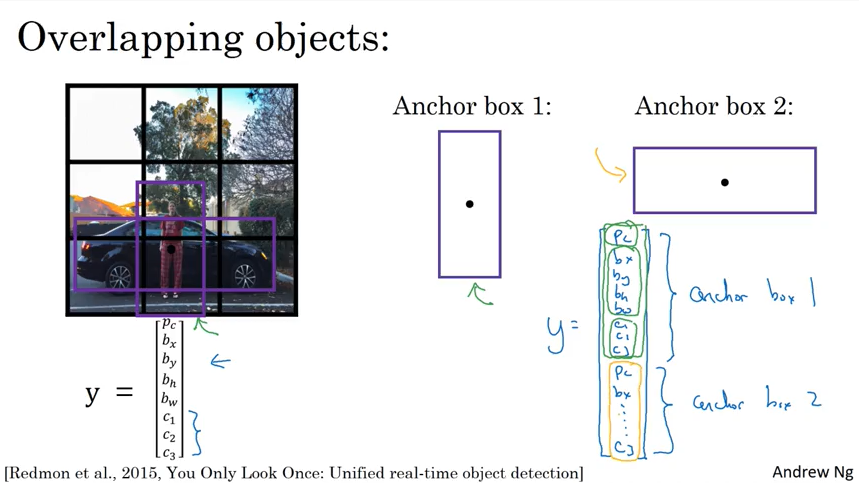
Anchor Boxes
Anchor Boxes 是干什么的?- 使得可以检测多个Object.
为什么之前讲的就是一个cell 只能检测一个Object呢?因为一个y 向量里面只有一个bounding box.
学习过程了产生了一个问题,为什么一定要预定义一些Anchor Box呢?直接像只处理单个Object那样测量一个bounding box, 只不过对多个object的情况测量多个bounding box 不就行了吗? 这里加一些个人理解,我觉得测量多个bounding box这样做也可以,本质上来说Anchor Box 就是bounding box, 只是Anchor Box 尺寸固定更加容易对input 图片标注. 纯属个人理解,希望有人看到这里指教一下.
2019/11/01 update: 感觉理解了Anchor box, 就是把对象按照形状大小分成几类,就是几个anchor box, 然后把对应大小的对象就到对应的 anchor box 里面,这个我理解主要能提高bbox 边框回归精度.

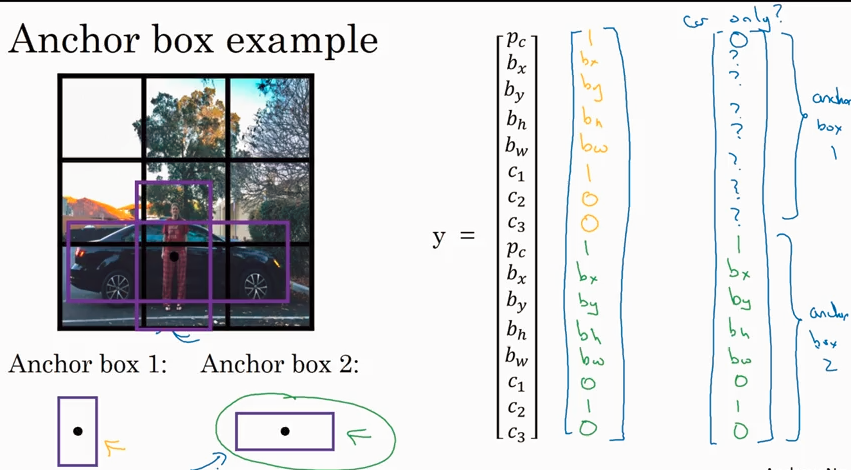
怎么选Anchor box呢?
人们一般手动选择5-10个可以cover 待检测对象的box. 更好的做法是用K-means算法来归类待检测对象,然后自动选出anchor box.
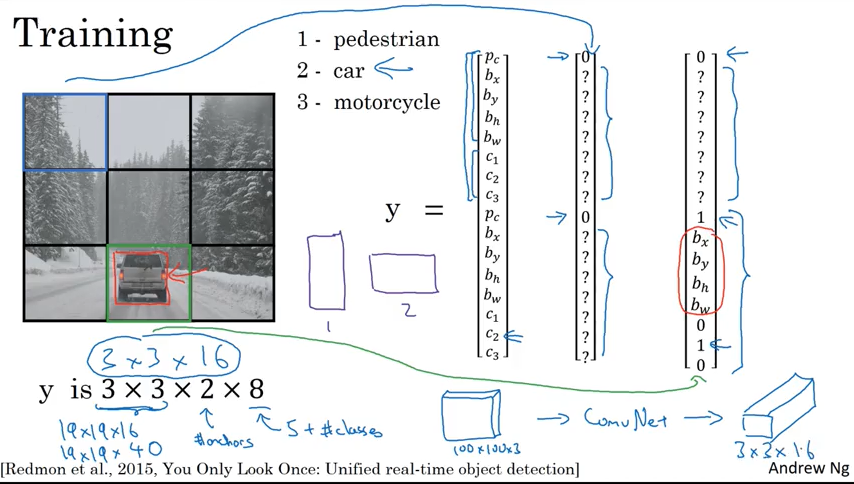
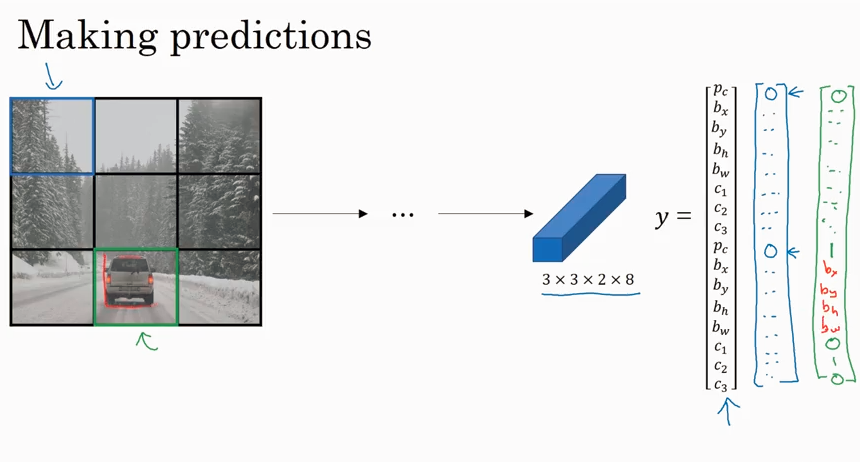
YOLO Algorithm
前面讲了核心的 YOLO算法,然后又讲了一个特殊情况的处理,已经一个对象多次被检测到的情况就需要 non-max suppression, 多个对象共同属于一个cell的情况就需要 Anchor Box. 所以这里集成了完整的YOLO算法.


R-CNN
Region CNN - 忽略一些明显没有用的grid cell
