尝试一下抓取微信公众号历史文章。
采集的主要信息有:标题、描述、作者、评论数、阅读数、在看数、发布时间、文章链接
主要有这几个步骤:
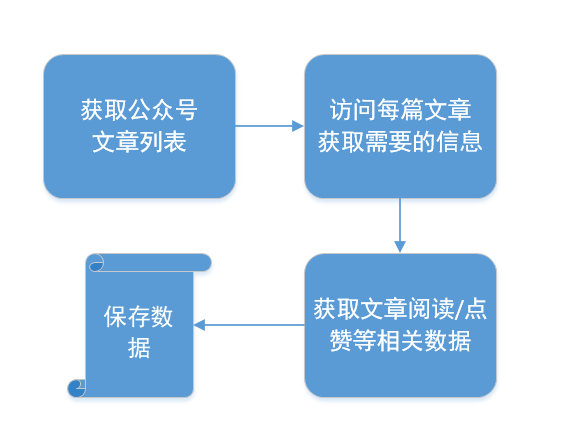
需要准备工具:
fiddler
微信PC客户端
使用python3,相应环境自己搭建。
分析流程:
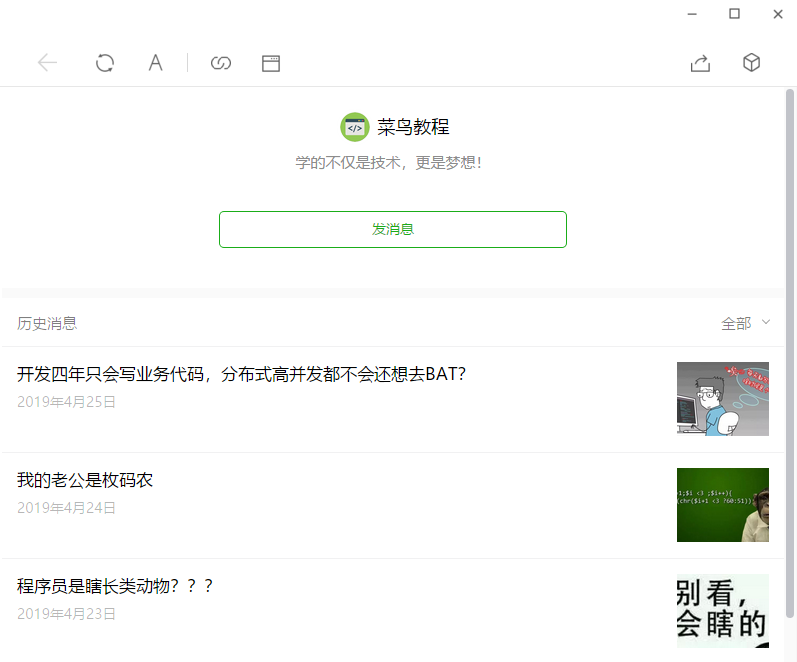
首先,打开fiddler,操作一下自己的微信,访问一些公众号,然后看一下请求,这里我访问菜鸟教程的历史文章,界面如下
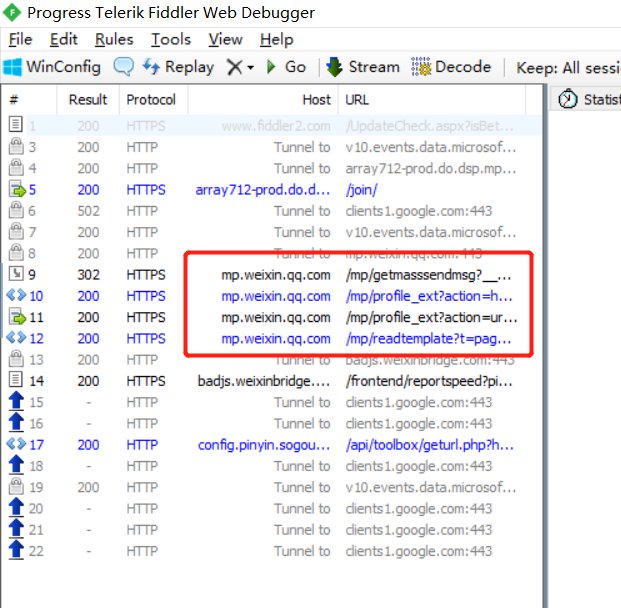
在fiddler里面找到微信相关的请求。如下
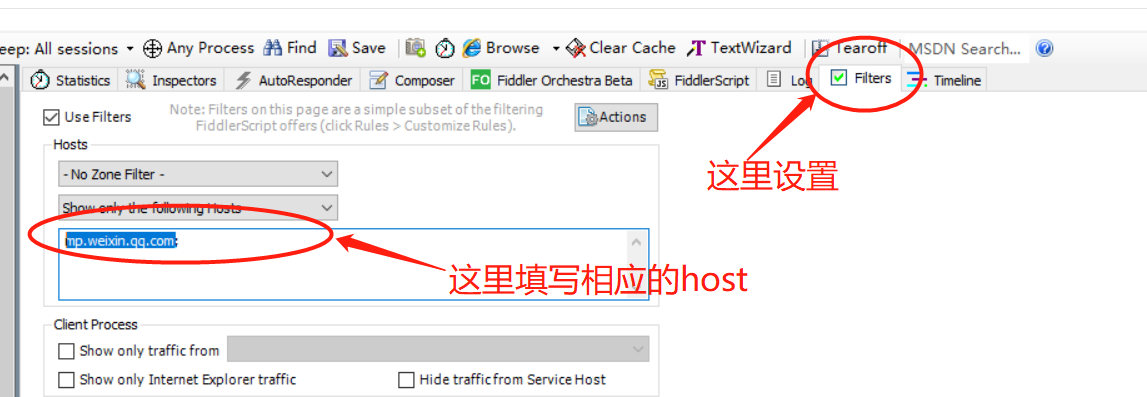
如果请求太多,可以设置过滤“mp.weixin.qq.com”,就可以只看微信这边过来的请求了。
我们将上面发现的几个请求每个都看一遍,可以发现在第二个请求“/mp/profile_ext?action=home...”里面有一些数据
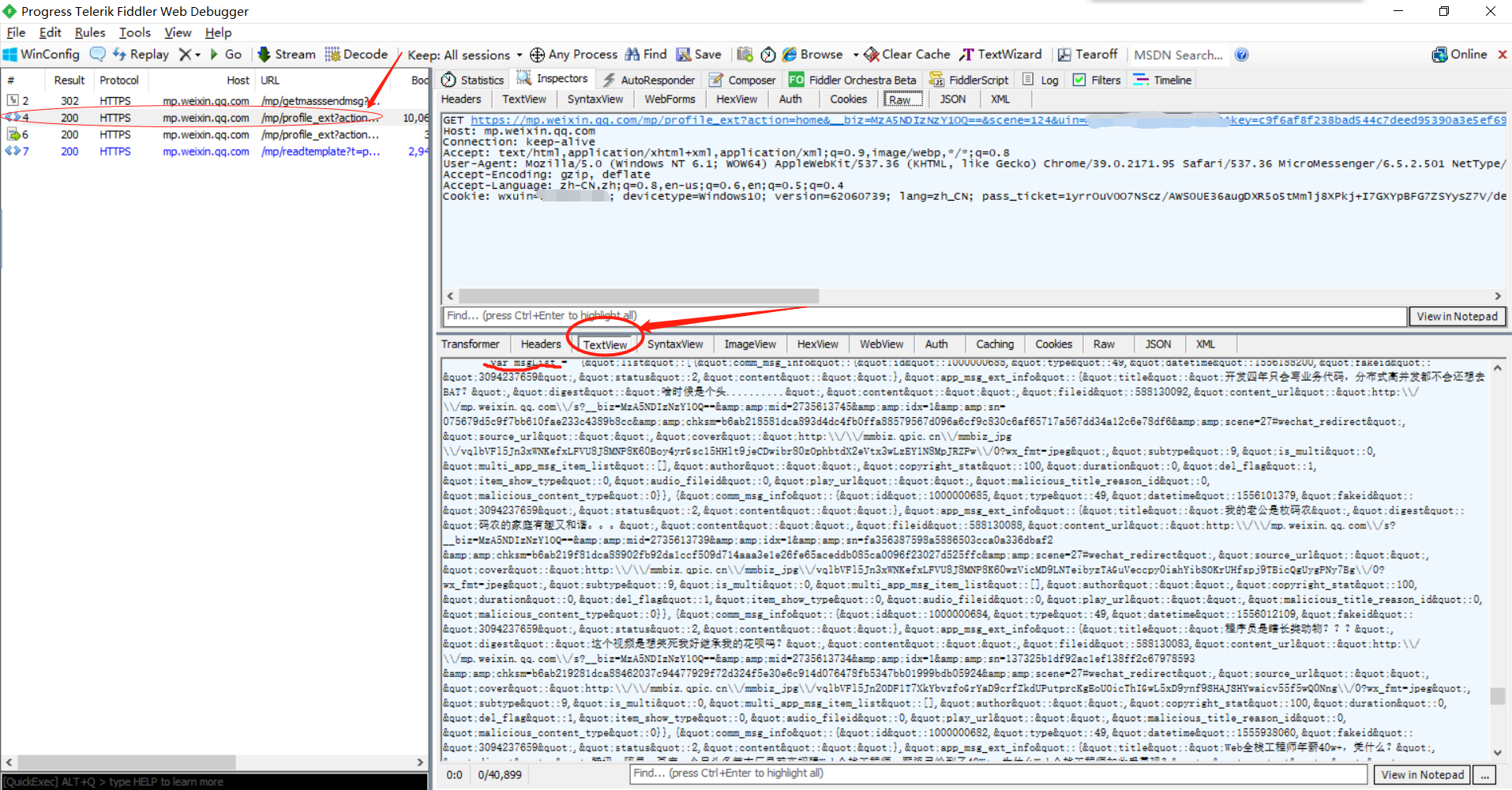
可以看到这个就是上面截图中的页面,里面有个'msgList'的js变量,存的貌似是页面内容的json。
也就是说我们请求到这个页面就可以获取这个文章列表了。
**注意到TextView这个tab的时候可能会告诉你页面没有解码,点击解码就可以了。
到现在是不是就可以着手开发代码了?别慌。
我们只知道这个页面有数据,但还不知道怎么下一页的数据怎么获取,先将界面上的文章拉到第二页看一下。(这个时候需要先关注公众号)
我们可以看到第二页相同链接的请求已经变成了json。
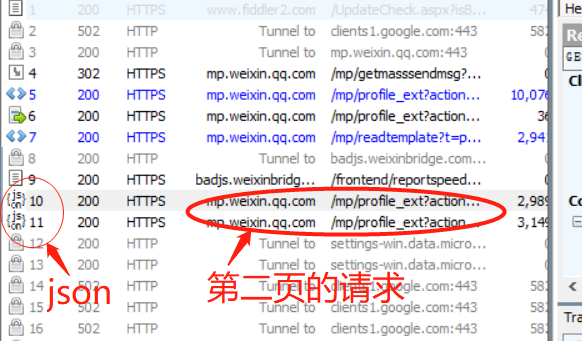
json数据,比解析网页似乎要方便许多。
分析请求:
看一下找到的这个请求的具体内容。
通过观察,我们可以知道这是一个get请求,通过研究,摸清了一些参数的含义,如下:
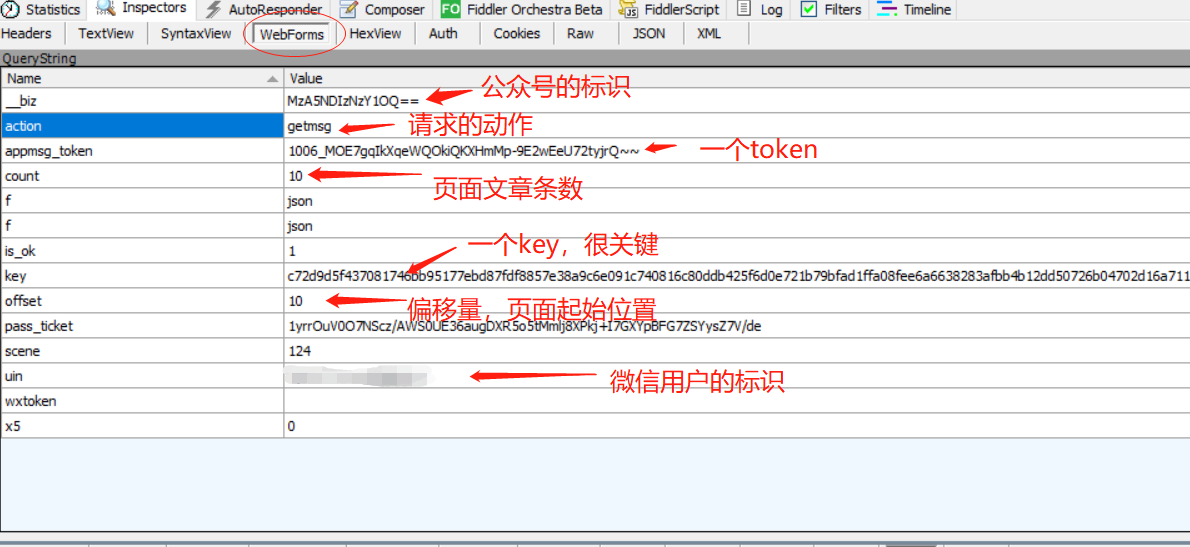
**一般不懂的参数可以试试不要,或者直接写死,很多情况是可以采集到数据的。
接下来写代码。
# encoding=utf-8 # date: 2019/4/26 __author__ = "Masako" import json import requests import urllib3 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) headers = { 'Host': 'mp.weixin.qq.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400', 'X-Requested-With': 'XMLHttpRequest', } biz = 'MzA5NDIzNzY1OQ==' # 公众号id uin = 'MjM4NTIzNzQ5MQ==' # 用户id key = '08039a5457341b11f0c0b7e68e3cda9f6cbf593f925e8716293a13998bece633ea775eeb0159' 'a1183ca88d27b3060f6fc2c3428ef633f851029a64fa0638e41d111e13dce78055e01a39d3d0fdd2f657' # 是个变量 pass_ticket = 'dKBE2K1SSAJHmrnd8fMJpWD6j52ASjpQfBiMjm74DyZd1Y7TsoOD/25GgM80trTX' # 似乎用处不大 offset = 0 pagesize = 10 proxies = { 'https': '218.86.87.171:53281' } url = "https://mp.weixin.qq.com/mp/profile_ext" params = { "action": "getmsg", "__biz": biz, "f": "json", "offset": offset, "count": pagesize, "is_ok": 1, "scene": 124, "uin": uin, "key": key, "pass_ticket": pass_ticket, "wxtoken": "", # "appmsg_token": appmsg_token, } response = requests.get(url, params=params, headers=headers, proxies=proxies, verify=False) print(response.text)
这里面的参数都是直接从fiddler里面复制过来的,由于开着fiddler,所以使用了verify=False,然后使用urllib3关闭了告警。
这份代码里面的参数基本可以不变,除了key大约十几分钟会过期。然后采集文章比较多的时候(好像几百条?)会封ip,需要使用ip代理。也就是设置proxies。
翻页的时候改变offset即可。
具体封装可以自己写函数。
运行结果:
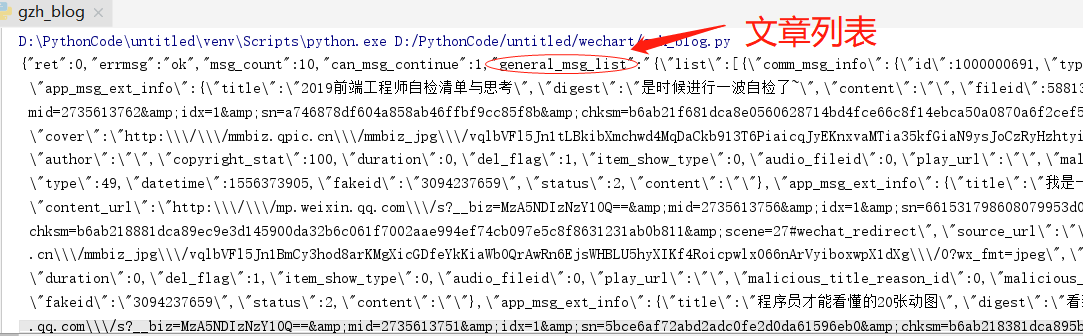
得到json的返回,解析其中的文章列表即可得到文章标题,头图,作者,链接等信息。
在这个json中还有"next_offset"(下一页的起始位置),"can_msg_continue"(是否可以继续翻页),等相关信息,可以帮助翻页采集。
更详细的数据
我们在这里只获取到了文章的基本信息,和链接,将链接拿下来使用get访问也可以获取到文章内容,但还获取不到阅读数,所以需要进一步分析。
现在我们在历史消息列表中随便找一篇文章,点击进入。
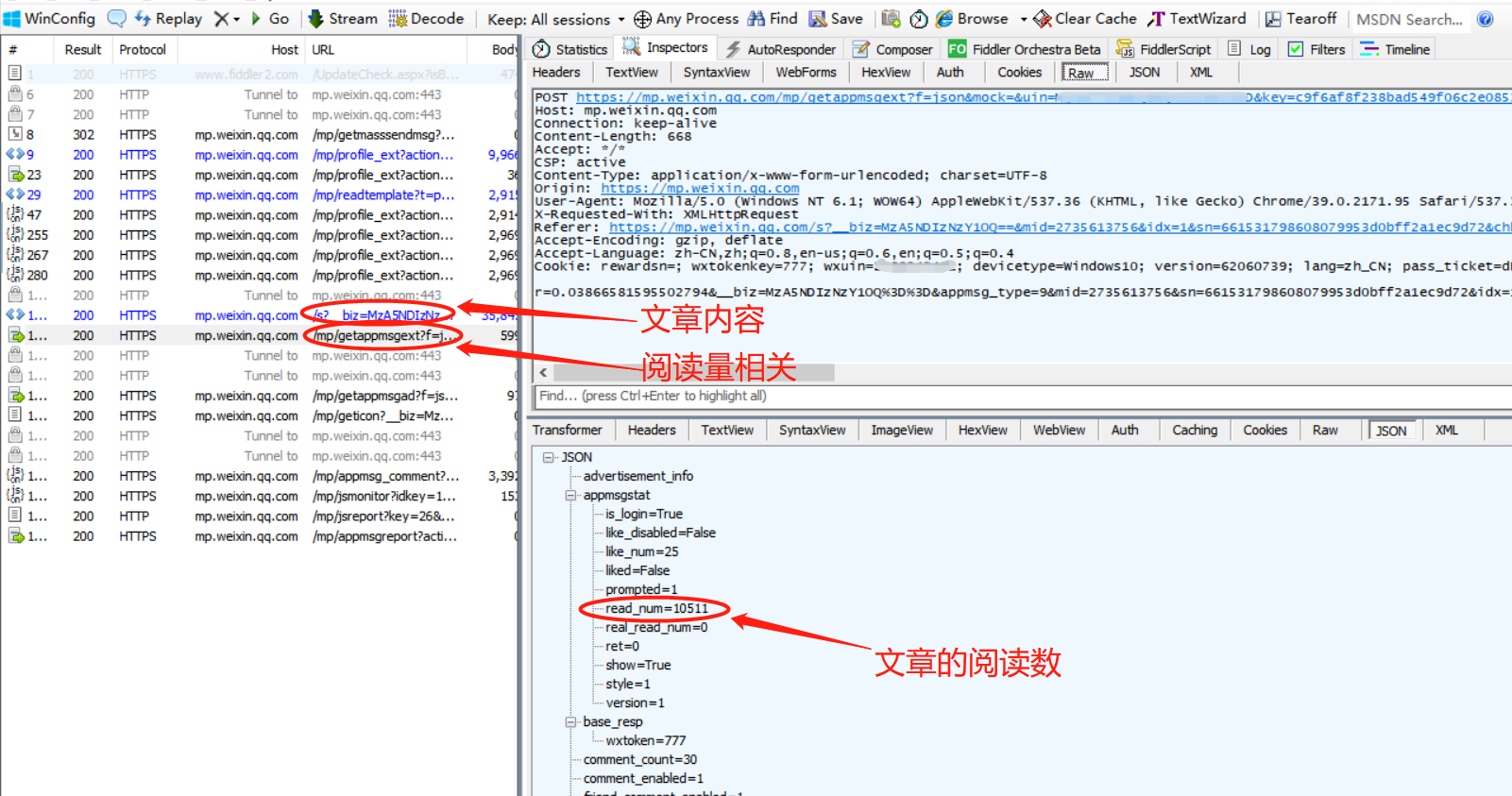
可以看到先请求了一个文章链接,就是上一步文章列表中获取到的链接,里面包含文章内容,我们自己也可以请求到。
在文章链接下面有一条包含“getappmsgext”的请求,点进去可以看到是一个json,我们解析这个json,可以看到read_num,
对比页面数据可以知道这个read_num就是阅读量了,这里还包括like_num在看数,comment_count评论数等(这个评论数似乎不是显示的评论,而是总数)。
那么我们要获取的就是这个请求了,分析过程同上面分析列表一样,接下来直接上请求代码:
# encoding=utf-8 # date: 2019/5/15 __author__ = "Masako" import time import requests import urllib3 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) proxies = { 'https': '218.86.87.171:53281' } headers = { 'CSP': 'active', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat ' 'QBCore/3.43.901.400 QQBrowser/9.0.2524.400', 'X-Requested-With': 'XMLHttpRequest', } biz = 'MzA5NDIzNzY1OQ==' # 公众号id uin = 'MjM4OTIzNzY1OQ==' # 用户id key = '333b7957c9b8367188f9a405069beed8a92625eae5e601ffda55443a53b7779af3d96bcd7' 'f992fb9f12557105abab467a55862681e76178e39b239a57d0c9aef7b324eb5fd1ae706b3aeef6c8f9d31a4' pass_ticket = 'dKBE2K1SSAJHmrnd8fMJpWD6j52ASjpQfBiMjm74DyZd1Y7TsoOD/25GgM80trTX' url = "https://mp.weixin.qq.com/mp/getappmsgext" params = { "mock": "", "f": "json", "uin": uin, "key": key, "pass_ticket": pass_ticket, "wxtoken": "777", "devicetype": "Windows%26nbsp%3B10", # "appmsg_token": appmsg_token, } t = int(time.time()) # 以下参数先使用复制的,后续再说获取 appmsg_type = "9" msg_title = "%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9A%84%E6%97%A5%E5%B8%B8%E5%A4%A7%E6%8F%AD%E9%9C%B2%EF%BC%8C" "%E5%A4%AA%E7%9C%9F%E5%AE%9E%E4%BA%86%EF%BC%81" req_id = "1516dM576eEqb9OJ50G0ECvJ" comment_id = "802341523856785408" mid = "2735613806" sn = "48862f1fb98b5d1a0550ce27594f1361" idx = "1" scene = "38" appmsg_like_type = "2" data = { # "r": "0.48046619608066976", "__biz": biz, # 公众号id "appmsg_type": appmsg_type, # 信息类型 "mid": mid, # 一个参数 "sn": sn, # 一个参数 "idx": "1", "scene": scene, # 一个数字 "title": msg_title, # 文章标题 "comment_id": comment_id, # 评论id "ct": t, # 时间戳 "pass_ticket": pass_ticket, # 一个参数 "req_id": req_id, # 一个参数 "abtest_cookie": "", "devicetype": "Windows+10", "version": "62060728", "is_need_ticket": "0", # 后面一些标识直接写死 "is_need_ad": "0", "is_need_reward": "1", "both_ad": "0", "send_time": "", "msg_daily_idx": "1", "is_original": "0", "is_only_read": "1", "is_temp_url": "0", "item_show_type": "0", "tmp_version": "1", "more_read_type": "0", "appmsg_like_type": "2" } response = requests.post(url, params=params, data=data, headers=headers, proxies=proxies, verify=False) print(response.text)
跑这份代码可以得到一个json

可以看到阅读数等信息都在这里面了。接下来我们解决上述代码中的一个问题——参数。
获取必要参数
上述代码中的部分参数是变量,每篇文章不同,示例中是直接复制下来使用,实际情况需要每次去获取的,如果每次都手动复制就没有意义了。
回到之前的文章内容页面
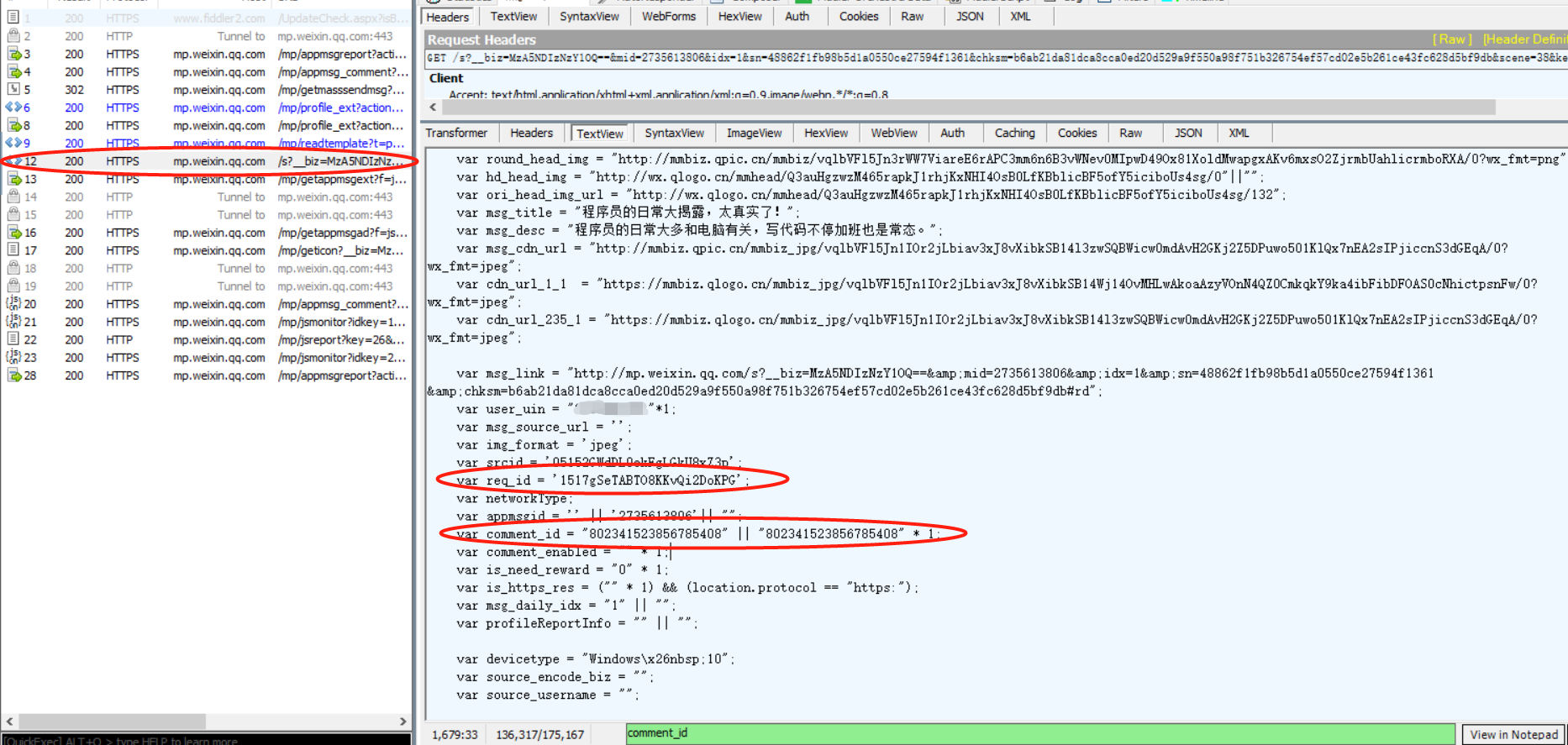
我们随便选一个参数在页面搜索一下就可以看到,有这些参数的定义,比如上图中的comment_id。
同样,其他参数也有,有的参数在链接中就有,都可以作为获取途径。
看这些参数都是JavaScript的定义,选择先访问这个页面直接用正则获取这些参数。代码如下:
# encoding=utf-8 # date: 2019/5/15 __author__ = "Masako" import re import requests import urllib3 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) headers = { 'Host': 'mp.weixin.qq.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400', 'X-Requested-With': 'XMLHttpRequest', } # 从文章列表获取到的链接,拼接域名 art_url = 'https://mp.weixin.qq.com/s?__biz=MzA5NDIzNzY1OQ==&mid=2735613806&idx=1&sn=48862f1fb98b5d1a0550ce27594f1361&chksm=b6ab21da81dca8cca0ed20d529a9f550a98f751b326754ef57cd02e5b261ce43fc628d5bf9db&scene=38&key=33ba9b7dde092b04c3cefb3cd24fa4be6815ea9c7ca566093b935014bef02d21bc4c1c28ba937ffdae3935020224da51188ae48f135981b067d3bf1ac5397375ef58670a5e9fcffdeefb069b04876363&ascene=7&uin=MjM4OTI0MzQ5MQ%3D%3D&devicetype=Windows+10&version=62060739&lang=zh_CN&pass_ticket=zGPZpVX8Mp%2BRMvVPKZF6Ci4MecfwbAppLGWvSu3bNP01O8gMXkV7%2B4pMIzep9g30&winzoom=1' # 请求到页面 response = requests.get(art_url, headers=headers, verify=False) content = response.text # 正则获取必要参数 appmsg_type = re.findall('appmsg_type = "(d+)"', content)[0] msg_title = re.findall('msg_title = "(.*?)"', content)[0] req_id = re.findall("req_id = '(.*?)'", content)[0] comment_id = re.findall('comment_id = "(.*?)"', content)[0] appmsg_like_type = re.findall('appmsg_like_type = "(.*?)"', content)[0] scene = re.findall('var source = "(.*?)"', content)[0] print(msg_title)
(代码未做错误处理,正则可能会报错。)
这份代码可以打印一些信息。
整合一下
将各个部分的代码整合一下。


1 # encoding=utf-8 2 # date: 2019/5/15 3 __author__ = "Masako" 4 5 import re 6 import json 7 import time 8 import html 9 import requests 10 11 from Elise.crawler import Crawler 12 13 import urllib3 14 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) 15 16 17 class GZHSpider: 18 19 def __init__(self): 20 self.biz = "" 21 self.uin = "" 22 self.key = "" 23 self.pass_ticket = "" 24 self.proxies = {} 25 self.headers = { 26 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)' 27 ' Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI ' 28 'WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400', 29 } 30 31 def get_art_list(self, offset=0, pagesize=10): 32 """ 33 获取文章列表 34 所需参数是调用时的变量,其他参数可以固定,在初始化时设置 35 :param offset: int, 偏移量,相当于页码, 可由上一页的位置得到 36 :param pagesize: int, 每页条数,默认为10 37 :return: 访问到的json数据 38 """ 39 url = "https://mp.weixin.qq.com/mp/profile_ext" 40 result = {} 41 # offset = page * pagesize 42 params = { 43 "action": "getmsg", 44 "__biz": self.biz, 45 "f": "json", 46 "offset": offset, 47 "count": pagesize, 48 "is_ok": 1, 49 "scene": '38', 50 "uin": self.uin, 51 "key": self.key, 52 "pass_ticket": self.pass_ticket, 53 "wxtoken": "", 54 } 55 try: 56 response = requests.get(url, params=params, headers=self.headers, proxies=self.proxies, verify=False) 57 except Exception as e: 58 result['code'] = 1 59 result['msg'] = str(e) 60 return result 61 62 try: 63 data = json.loads(response.text) 64 data['code'] = 0 65 return data 66 except json.decoder.JSONDecodeError as e: 67 result['code'] = 2 68 result['msg'] = str(e) 69 return result 70 71 def get_art_page(self, art_url): 72 """ 73 从文章页面获取采集阅读量需要的数据 74 :param art_url: str, 文章链接 75 :return: 76 """ 77 result = {} 78 try: 79 response = requests.get(art_url, headers=self.headers, proxies=self.proxies, verify=False) 80 # print(response.text) 81 except Exception as e: 82 result['code'] = 1 83 result['msg'] = str(e) 84 return result 85 86 # 处理文章错误 87 try: 88 if '访问过于频繁' in response.text: # 访问频繁,需换ip 89 result['code'] = 4 90 result['msg'] = "ip banned" 91 return result 92 if '无法查看' in response.text: # 无法查看,被删除或者被违规被举报 93 result['code'] = 5 94 result['msg'] = "content violation" 95 return result 96 data = self.parse_art_page(response.text) 97 except Exception as e: # 其他错误导致解析失败 98 result['code'] = 2 99 result['msg'] = str(e) 100 return result 101 102 result['data'] = data 103 result['code'] = 0 104 return result 105 106 @staticmethod 107 def parse_art_page(content): 108 """ 109 解析文章 html 110 :param content: 文章页面的html, 字符串 111 :return: 112 """ 113 def get_value(s, name): 114 value_str = re.findall('var %s = (.*?);' % name, s)[0] 115 patten = re.compile('"(.*?)"') 116 r_list = re.findall(patten, value_str) 117 for i in r_list: 118 if i: 119 return i 120 else: 121 return '' 122 123 # 直接正则获取了 124 appmsg_type = re.findall('appmsg_type = "(d+)"', content)[0] 125 msg_title = re.findall('msg_title = "(.*?)"', content)[0] 126 req_id = re.findall("req_id = '(.*?)'", content)[0] 127 comment_id = re.findall('comment_id = "(.*?)"', content)[0] 128 129 mid = get_value(content, 'mid') 130 sn = get_value(content, 'sn') 131 idx = get_value(content, 'idx') 132 scene = re.findall('var source = "(.*?)"', content)[0] 133 publish_time = re.findall('var publish_time = "(.*?)"', content)[0] 134 135 appmsg_like_type = re.findall('appmsg_like_type = "(.*?)"', content)[0] 136 137 params = { 138 "appmsg_type": appmsg_type, 139 "msg_title": msg_title, 140 "publish_time": publish_time, 141 "mid": mid, 142 "sn": sn, 143 "idx": idx, 144 "scene": scene, 145 "req_id": req_id, 146 "comment_id": comment_id, 147 "appmsg_like_type": appmsg_like_type, 148 } 149 return params 150 151 def get_art_about(self, params_data): 152 """ 153 获取阅读量点赞数等相关信息 154 :param params_data: dict, 需要的参数 155 :return: 156 """ 157 url = "https://mp.weixin.qq.com/mp/getappmsgext" 158 result = {} 159 # offset = page * pagesize 160 params = { 161 "mock": "", 162 "f": "json", 163 "uin": self.uin, 164 "key": self.key, 165 "pass_ticket": self.pass_ticket, 166 "wxtoken": "777", 167 "devicetype": "Windows%26nbsp%3B10", 168 # "appmsg_token": appmsg_token, 169 } 170 t = int(time.time()) 171 # title = requests.utils.quote(title) 172 data = { 173 # "r": "0.48046619608066976", 174 "__biz": self.biz, 175 "appmsg_type": "9", # 复制下来的值,会被覆盖掉 176 "mid": "", 177 "sn": "", 178 "idx": "1", 179 "scene": "", 180 "title": "", # 为空,后面覆盖 181 "ct": t, 182 "abtest_cookie": "", 183 "devicetype": "Windows+10", 184 "version": "62060728", 185 "is_need_ticket": "0", 186 "is_need_ad": "0", 187 "comment_id": "", 188 "is_need_reward": "1", 189 "both_ad": "0", 190 "send_time": "", 191 "msg_daily_idx": "1", 192 "is_original": "0", 193 "is_only_read": "1", 194 "pass_ticket": self.pass_ticket, # 也可以写死 195 "is_temp_url": "0", 196 "item_show_type": "0", 197 "tmp_version": "1", 198 "more_read_type": "0", 199 "appmsg_like_type": "2" 200 } 201 if isinstance(params_data, dict): # 将传进来的参数和一些写死的参数合并到一个字典 202 data.update(params_data) 203 headers = { 204 'CSP': "active", 205 'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8", 206 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)' 207 ' Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI ' 208 'WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400', 209 } 210 try: 211 response = requests.post(url, params=params, data=data, headers=headers, proxies=self.proxies, verify=False) 212 except Exception as e: 213 result['code'] = 1 214 result['msg'] = str(e) 215 return result 216 217 try: 218 data = json.loads(response.text) 219 appmsgstat = data.get('appmsgstat') 220 if appmsgstat: 221 result['code'] = 0 222 result['data'] = data 223 return result 224 # {'base_resp': {'ret': 302, 'errmsg': 'default'}} 225 resp = data.get('base_resp', {}) 226 ret = resp.get('ret') 227 if ret == 302: 228 result['code'] = 0 # 先存下来再说 229 result['data'] = data 230 return result 231 except json.decoder.JSONDecodeError as e: 232 result['code'] = 2 233 result['msg'] = str(e) 234 return result 235 236 result['code'] = 3 # 表示登录信息过期 237 result['data'] = data 238 return result 239 240 def get_art_by_url(self, art_url): 241 """ 242 整合一下获取阅读量的过程 243 :param art_url: str, 文章链接 244 :return: 245 """ 246 r_0 = self.get_art_page(art_url) 247 code = r_0.get('code') 248 if code != 0: 249 return r_0 250 data = r_0.get('data', {}) 251 r_1 = self.get_art_about(data) 252 code = r_1.get('code') 253 if code != 0: 254 return r_1 255 result = r_1 256 result['data']['pre_info'] = data 257 # 记录采集时间 258 t = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())) 259 result['data']['c_time'] = t 260 return result 261 262 263 class GZHCrawler(Crawler): 264 def __init__(self, spider): 265 Crawler.__init__(self, spider) 266 267 def _stop(self): 268 # self.input_que.clear() 269 self.input_que.unfinished_tasks = 0 # 清空队列的计数器 270 271 def crawl_list(self): 272 while True: 273 try: 274 offset = self.input_que.get() 275 print(offset) # 打印页码,可以直观看到进度 276 except Exception as e: 277 time.sleep(1) 278 continue 279 280 ret = self.spider.get_art_list(offset=offset) 281 code = ret.get('code') 282 if code != 0: 283 self.input_que.put(offset) 284 self.input_que.task_done() 285 continue 286 287 status = ret.get('ret') 288 if status == -3: # cookie过期 289 print(offset) 290 print(ret) 291 292 data_list_str = ret.get('general_msg_list') 293 try: 294 data = json.loads(data_list_str) 295 except Exception as e: 296 self.input_que.task_done() 297 continue 298 299 art_list = data.get('list') 300 for a in art_list: 301 # self.out_que.put(a) 302 data_info = a.get('app_msg_ext_info', {}) 303 title = data_info.get('title', '') 304 digest = data_info.get('digest', '') 305 content_url = data_info.get('content_url', '') 306 content_url = html.unescape(content_url) 307 fileid = data_info.get('fileid', '') 308 author = data_info.get('author', '') 309 d = { 310 "title": title, 311 "digest": digest, 312 "content_url": content_url, 313 "fileid": fileid, 314 "author": author, 315 "head": 1 316 } 317 # print(d) # 打印结果看看 318 if fileid: 319 self.out_que.put(d) 320 multi_app_msg_item_list = data_info.get('multi_app_msg_item_list', []) 321 for i in multi_app_msg_item_list: 322 title = i.get('title', '') 323 digest = i.get('digest', '') 324 content_url = i.get('content_url', '') 325 content_url = html.unescape(content_url) 326 fileid = i.get('fileid', '') 327 author = i.get('author', '') 328 if fileid: 329 d = { 330 "title": title, 331 "digest": digest, 332 "content_url": content_url, 333 "fileid": fileid, 334 "author": author, 335 "head": 0 336 } 337 self.out_que.put(d) 338 339 is_not_end = ret.get("can_msg_continue", 0) 340 next_page = ret.get("next_offset") 341 if is_not_end: 342 self.input_que.put(next_page) 343 344 self.input_que.task_done() 345 time.sleep(5) 346 347 def crawl(self): 348 while True: 349 try: 350 params = self.input_que.get(timeout=0.2) 351 print(params) 352 except Exception as e: 353 time.sleep(1) 354 continue 355 356 url = params.get('content_url', '') 357 result_data = self.spider.get_art_by_url(url) 358 data = result_data.get('data', {}) 359 code = result_data.get('code') 360 if code == 3: # 登录信息错误,就退出 361 # self.input_que.task_done() 362 self._stop() 363 if code == 4 or code == 5: # ip被封禁; 内容违规, 就丢弃 364 self.input_que.task_done() 365 continue 366 if code != 0: # 其他错误重新采集 367 self.input_que.put(params) 368 self.input_que.task_done() 369 continue 370 371 if data: 372 data.update(params) 373 self.out_que.put(data) 374 self.input_que.task_done() 375 time.sleep(3) 376 377 378 def test_spider(): 379 spider = GZHSpider() 380 spider.biz = 'MzA5NDIzNzY1OQ==' # 公众号id 381 spider.uin = 'MjM4OTIzNzY1OQ==' # 微信号id 382 spider.key = '014a8898c5f07cd6845f41fa83ff9b4edfa4556f8e3371f1e7d5081b24b931f317f94c48a4e42931b2a6ae5fe846ddc59749d081e5bbf45fc5ac93ebde78d13e7480dcf0b952752b993ac8158e936dbf' 383 spider.pass_ticket = 'nEfY/UYG8sVbejI2/vtgkoMsxh5cw4FgVeJpRIrQLOAbRTyczaZCoBRr97c9HsCi' 384 385 result_1 = spider.get_art_list() 386 # 打印获取到的列表 387 print(json.dumps(result_1)) 388 general_msg_list = result_1.get('general_msg_list', {}) 389 data_list_json = json.loads(general_msg_list) 390 art_list = data_list_json.get('list') 391 for article in art_list: 392 data_info = article.get('app_msg_ext_info', {}) 393 content_url = data_info.get('content_url', '') 394 content_url = html.unescape(content_url) 395 print(content_url) 396 result_2 = spider.get_art_by_url(content_url) 397 # 打印一下获取到的文章信息 398 print(json.dumps(result_2)) 399 break 400 401 402 def test_crawler(): 403 s = GZHSpider() 404 s.biz = 'MzA5NDIzNzY1OQ==' # 公众号id 405 s.uin = 'MjM4OTIzNzY1OQ==' # 微信号id 406 s.key = '014a8898c5f07cd6845f41fa83ff9b4edfa4556f8e3371f1e7d5081b24b931f317f94c48a4e42931b2a6' 407 'ae5fe846ddc59749d081e5bbf45fc5ac93ebde78d13e7480dcf0b952752b993ac8158e936dbf' 408 s.pass_ticket = 'nEfY/UYG8sVbejI2/vtgkoMsxh5cw4FgVeJpRIrQLOAbRTyczaZCoBRr97c9HsCi' 409 s.proxies = { # 设置ip代理 410 'https': '218.86.87.171:53281' 411 } 412 413 # 采集文章列表 414 crawler = GZHCrawler(s) 415 crawler.thd_num = 1 416 crawler.crawl_func = crawler.crawl_list 417 crawler.start_page_list = [0] 418 crawler.out_file = 'runoob_list.json' 419 crawler.run() 420 421 # 采集文章数据 422 crawler.crawl_func = crawler.crawl 423 crawler.input_file = 'runoob_list.json' 424 crawler.out_file = 'runoob_detail.json' 425 crawler.run() 426 427 428 if __name__ == "__main__": 429 test_crawler()
这样就可以自动获取文章列表并保存,随后获取文章阅读数等相关信息并保存。
这个缺点是并不完全自动化,因为key会过期,测试大约采集三四百条(十几分钟?)就过期了。访问频繁的时候也会封ip,所以需要ip代理。
以上所有代码要跑的话,务必更换 uin,key.