转载:http://www.cnblogs.com/zhijianliutang/p/4009829.html
本篇文章主要是继续上一篇Microsoft决策树分析算法后,采用另外一种分析算法对目标顾客群体的挖掘,同样的利用微软案例数据进行简要总结。
应用场景介绍
通过上一篇中我们采用Microsoft决策树分析算法对已经发生购买行为的订单中的客户属性进行了分析,可以得到几点重要的信息,这里做个总结:
1、对于影响购买自行车行为最重要的因素为:家中是否有小汽车,其次是年龄,再次是地域
2、通过折叠树对于比较想买自行车的顾客群体特征主要是:家里没有车、年龄在45岁一下、不在北美地区、家里也没有孩子(大米国里面的屌丝层次)、
同样还有就是家里有一辆车、年龄在37到53之间、通勤距离小于10Miles,家里孩子少于4个,然后年收入在58000$以上(大米国的高富帅了)
其实决策树算法最主要的应用场景就是分析影响某种行为的因素排序,通过这种算法我们可以知道某些特定群体他们都会有几个比较重要的属性,比如家里有没有车、年龄等,但是我们想要分析这部分特定群体其特有属性就没法做到,而要分析这种特定群体所共同含有的共同属性就需要今天我们的Microsoft聚类分析算法出场了,简单点讲就是:物以类分、人以群分,通过聚类分析算法我们要找到那些将要买自行车的顾客群里都有哪些属性,比如当我们晚上进入广场会看到,广场大妈一群、儿童扎在一群、打篮球的一群、还有一群情侣在广场边幽暗的树林里等等,而他们这些团队之间是有差别的,若果要去卖儿童玩具...那种群体是你最想靠近的自然而然了。
技术准备
(1)同样我们利用微软提供的案例数据仓库(AdventureWorksDW2008R2),两张事实表,一张已有的历史购买自行车记录的历史,另外一张就是我们将要挖掘的收集过来可能发生购买自行车的人员信息表,可以参考上一篇文章
(2)VS、SQL Server、 Analysis Services没啥可介绍的,安装数据库的时候全选就可以了。
下面我们进入主题,同样我们继续利用上次的解决方案,依次步骤如下:
(1)打开解决方案,进入到“挖掘模型”模板
通过上面可以看到已经存在一种决策树算法了,我们来添加另外一种算法。
2、右键单击“结构”列,选择“新建挖掘模型”,输入名称即可

点击确定,这样我们新建立的聚类分析就会增加在挖掘模型中,这里我们使用的主键和决策树一样,同样的预测行为也是一样的,输入列也是,可以更改。
下一步,部署处理该挖掘模型。
结果分析
同样这里面我们采用“挖掘模型查看器”进行查看,这里挖掘模型我们选择“Clustering”,这里面会提供四个选项卡,下面我们依次介绍,直接晒图:
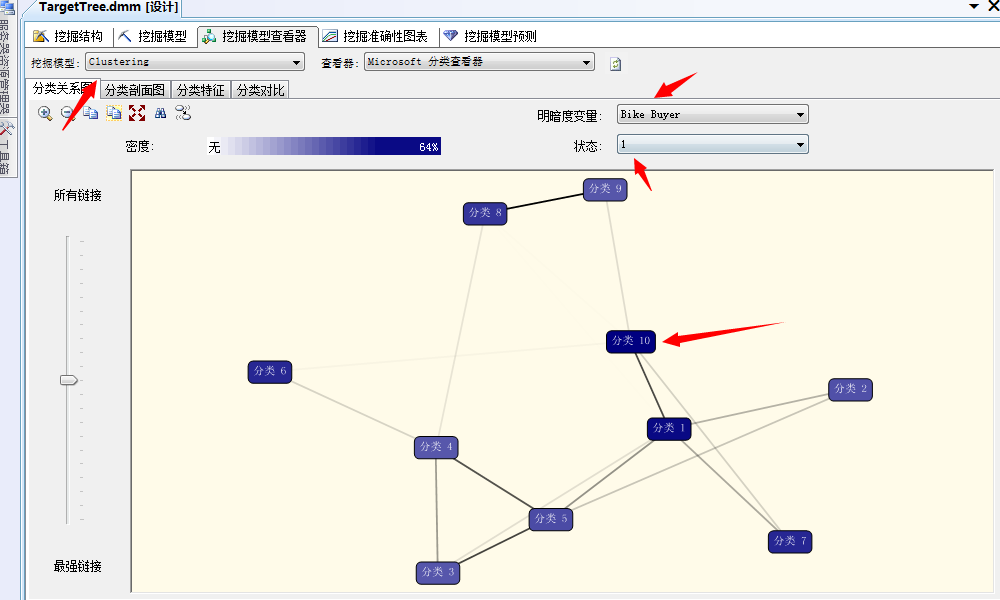
同样这里面我们选择要发生购买自行车的群里,颜色最深的为最可能购买自行车的群里,图中箭头我们已经显示出来了,同样我们也可以找到最不可能买自行车的一群人,也就是“分类四”,他们之间线条的强弱表示关联关系强弱,当然这里为了好记我们可以给他们改改名,直接选择类,右键重命名。
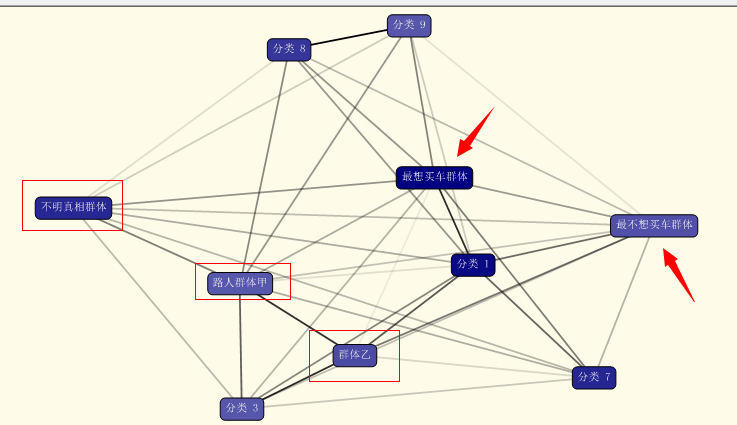
如上图,下面我们要做的就是要分析这些群体有啥特征了,当然我们最关心的为:最想买自行车的一群人、不想买自行车的也可以分析,至于不明真相的群体、路人群体甲、乙...这些个都是些打酱油的了,我们就不分析了。
我们打开“分类剖面图”看看:
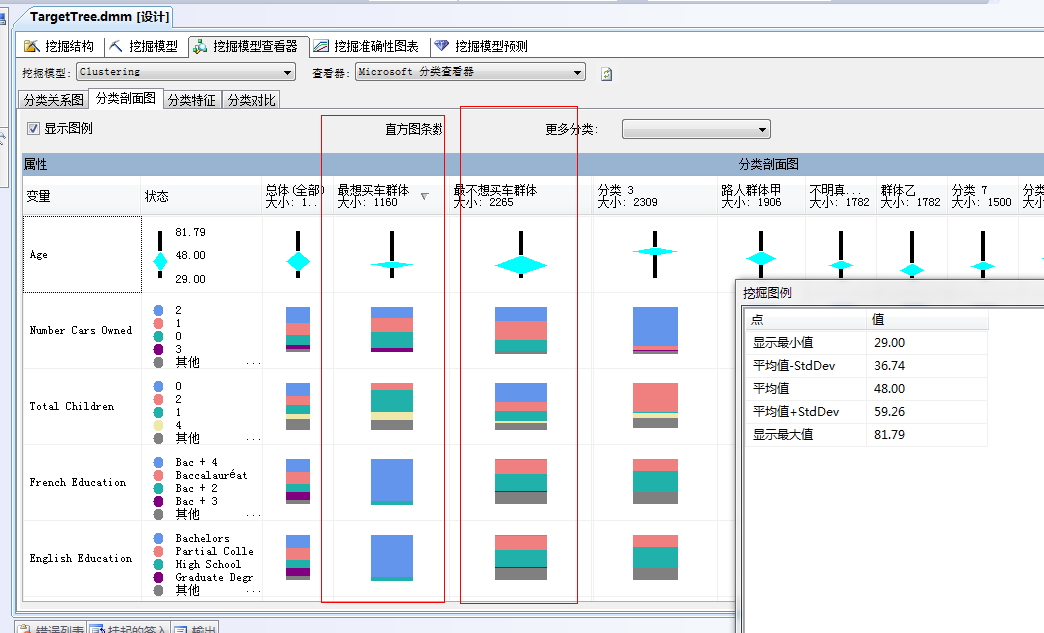
哈...这几类群体的特征已经展示出来了,如果玩数据久了,会对图表有一种直观敏锐,对数据也要保持一种特定的嗅觉。
我们重新整理一下这个“分类剖面图”的列的顺序,根据我们关注的强弱横向依次展开,如图:
图中第一列为属性,比如年龄、小汽车的数量、家里孩子数量等,第二列为各个属性的图例,这里面是根据属性的值类型进行的图例展示,一般分为两种,比如年龄在库中存储的值类型通常分布在1-100之间,故图例采取分段取样,形成一个从小到大的柱状体,中间含有有一个棱形图,棱形图的大小代表属性中群体的密集度,比如上图的顾客集中在29岁到48岁之间:
当然如果该属性值不为离散的属性值的话,就采取不同颜色的原型图表表示,专业术语叫做:直方图,面板中有一个地方可以设置直方图条数,也就是该属性值所取得的最多属性值个数。比如:家里孩子的总数,一般分为0个、1个、2个、3个、其他...

纳尼!...上面这个图例中没有3个孩子的,这里面的图例也是通过数据采样得到,只取量比较多的作为展示,上图说明家里有3个孩子的比较少。
下面我们分析一下最想购买自行车的群体特征:
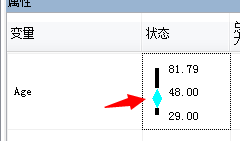
首先从图中可以看到年龄集中在40来岁,平均为43.65岁
我汗....最小年龄为29岁.平均年龄43.65岁..最大年龄81.79岁..估计微软案例数据库中的数据也不一定可靠,抑或者米国的人群特征就这样三十岁以下的人都不喜欢骑自行车反而80多岁的人还买自行车,或者这个店就不卖给三十岁以下的顾客,当然有可能年轻人没有买的,大部分是老人给孩子买的,这个就不分析了..反正数据是这么说的,有图有真相!
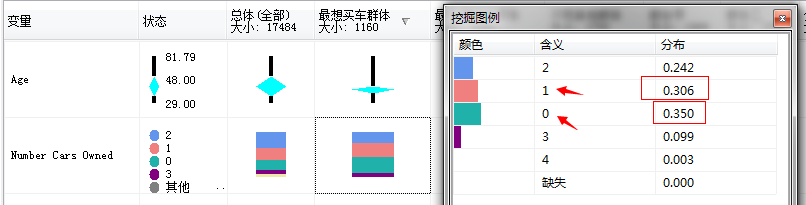
家里没有小汽车的或者只有一辆小汽车的购买的概率大部分集中在0.3以上...而大于一辆小汽车的家庭购买自行车的概率就很少...家里四辆车的概率则少到了0.003...接近不会买的概率了...
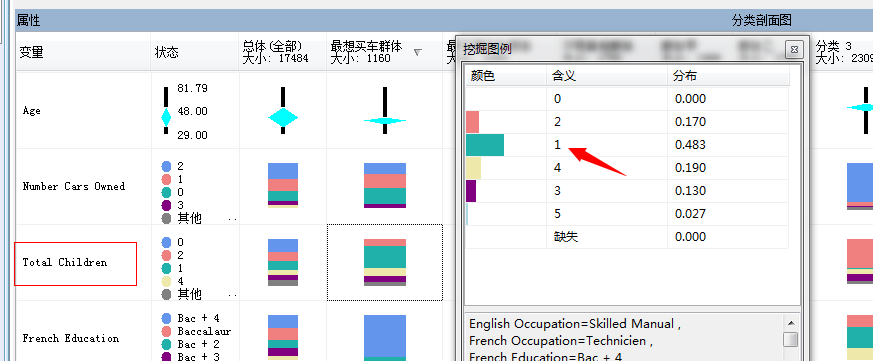
家里有一个孩子的概率最高0.483...家里没有孩子的根本不会买自行车...我去...基本验证了我上面的推测,看来大部分人是买自行车给子女骑的,没有孩子就不买了,上图中的没有子女的购买自信车的概率为0.000,还有一个属性可以研究下,那就是是否有房子,看图:

嗯...想买车的群体家里大部分都有房子,也就说有固定住所,他们买自行车的概率高达0.854...而没有房子的则少到可怜...为0.146。
别的属性也可以通过该属性面板进行分析,可以分析出我们想要的那部分群体的属性特征,有针对性的做到定向营销。
以上只是通过分类的剖面图进行了局部分析,VS还提供了另外一个专门列举属性特征的面板:分类特征。
我们点击开这个面板看看:
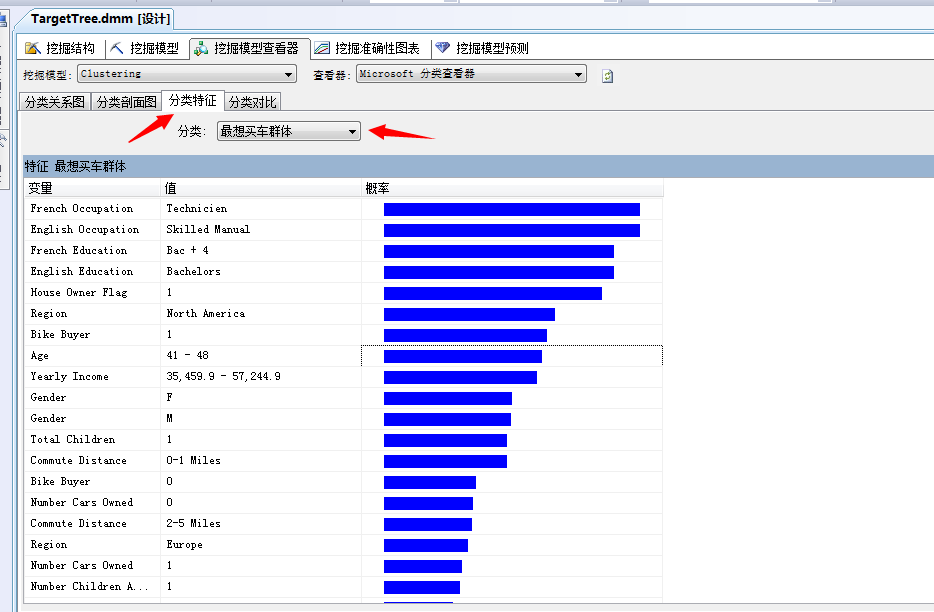
通过上面的图表展示,已经将我们想要了解的这部分群体,赤裸裸的展现出来了,嗯,来瞅瞅..法国职业:、英国职业:
同样我们也可以针对某一个属性,有针对性的对两组群体进行比较,这里就应用到另一个面板:“分类对比”,我突然想到可以针对“性别”这个属性,把IT行业和非IT行业进行对比,估计结果应该不寒而栗...呵呵...题外话,下面看图:
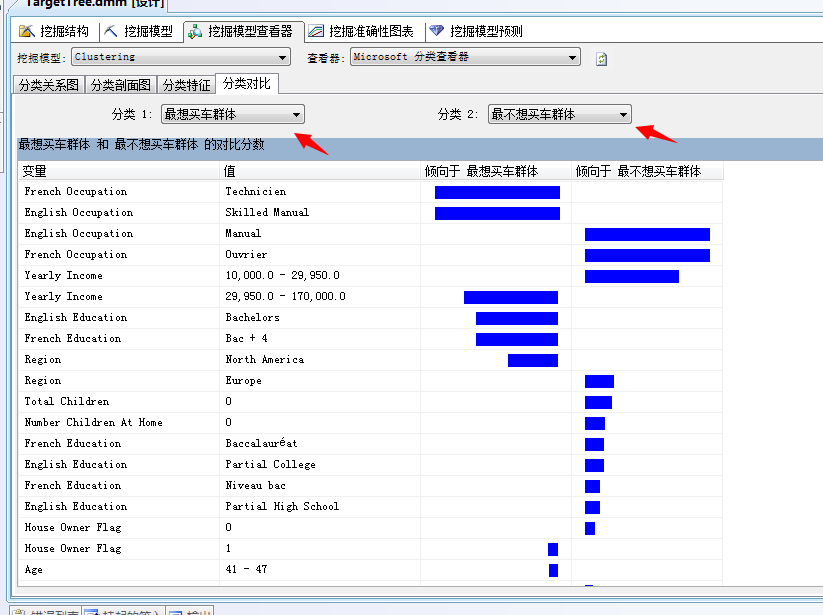
尼玛...上图的图片我看了下..发现有一个属性值特别有趣,年收入在10000-29950之间的基本是不打算买自行车了,然而年收入到了29950-1700000,想买自行车的概率就高很多了,上图中可以看到。嗯...自行车也是车...想要买车还是得有钱才行。
准确性验证
最后我们来验证一下今天这个聚类分析算法的准确性如何,和上篇文章中的决策树算法有何差距,我们点击进入数据挖掘准确性图表:
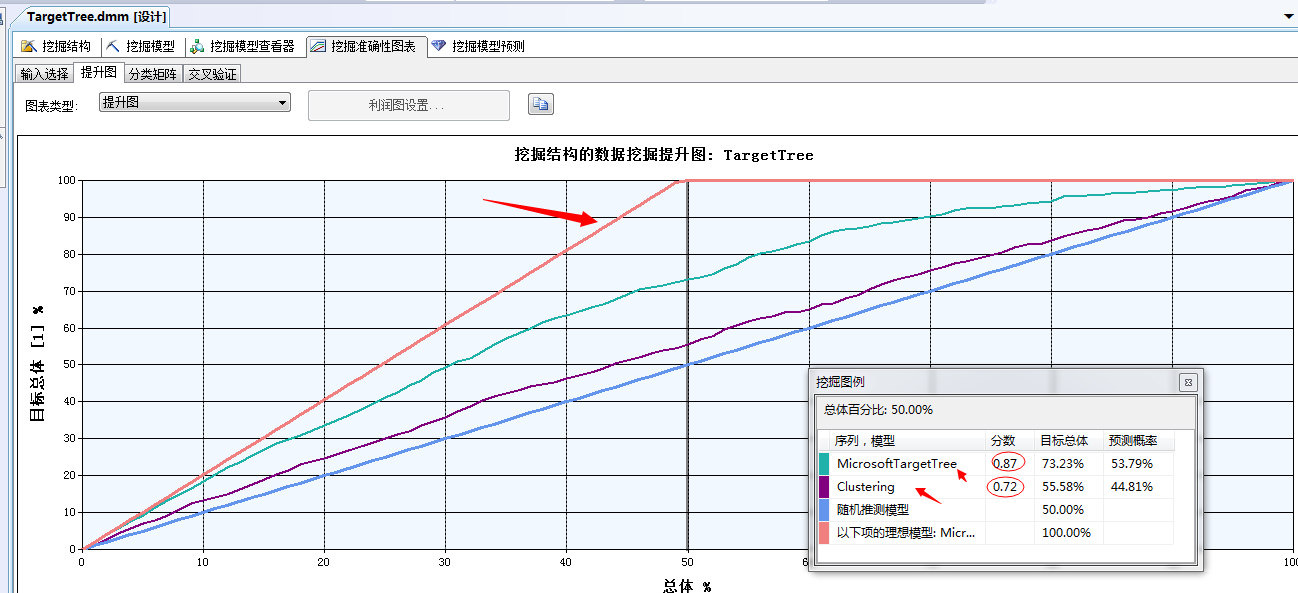
上图中我们可以看到,今天这次用的聚类分析算法,分数为0.72,比上一篇的决策树算法0.87,还是略有差距的,当然不能仅以分数来评比两种算法的好坏,不同的挖掘需求需要不同的挖掘模型,同样不同的挖掘模型就需要不同的挖掘分析算法。
不过通过上图有几点需要特别注意的,数据分析算法的准确性是要取决于基础数据的多少,也就是说数据量越大,你所分析的数据结果将越准确,同样这也是未来大数据的概念的形成,没有数据任何牛逼的算法也没有招,而当数据达到一定量级别之后,任务个别的不准确也将被大数据的事实所掩盖,这就是大数据时代的意义所在。
当然凡事都得拿数据说话,不能凭空乱想,上图中的理想模型也就是红色的那条就验证了我刚才的说法,当数据总体达到50%以后,我们的数据挖掘结果就是100分,100分啥含义?完全正确!也就是说你下一步想干啥是我们完全能推测出来的,当然在数据量少的时候,我们就无能为力了,我们所利用的任何数据挖掘算法理论上讲将无限的接近这条红线(理想模型),将永远无法超越,而这接近的过程就是我们大数据时代的推动。
当然还有一条最烂的随机预测模型它永远的以50%的概率神一般存在着...因为对于买自行车这件事只有两种结果,一个是买,另一个就是不买,它所预测准确的概率永远就是一半一半...50%.....。
对大数据有兴趣的不要忘记你的“推荐”哦。