开始介绍之前还是老样子先吐槽一下教科书不说人话,喜欢端着,真是耽误了一群数学天才。
伯努利分布
伯努利分布很好理解,常见的例子就是抛硬币,假设硬币正面朝上的概率是 p,所以伯努利分布的概率质量函数(probability mass function,简写作pmf)是:
注意区分概率质量函数和概率密度函数,前者是针对离散情况而言的,后者是针对连续情况
二项分布
上面只是一个实验,如果抛10次有8次是正面朝上的概率就是 \(C_{10}^8 p^8(1-p)^2\),这个其实就是二项分布,换言之二项分布的每一个单次实验其实就是服从伯努利分布。二项分布的概率质量函数是
泊松分布
那泊松分布是什么呢?其实现实中很多事情都可以用泊松分布来描述,而且其实泊松分布可以简单地是伯努利分布的极限情况。
我们看一个马同学给的例子,
假如你开了个馒头店,每天营业时间是早上12点到下午6点,是的你就是这么仁慈,员工得休息好才能好好上班。然后你统计了一周的顾客数量,发现每天来的人顾客数量不一样。那很自然地你就想根据来的顾客的数量来提前准备制作馒头的数量,免得顾客数量多的时候,馒头数量不够,导致钞票赚少了。同样的,如果馒头做多了,又浪费了。所以你想知道每天顾客数量是100的概率(也可以是200,400等)。要计算这个就需要用到泊松分布。
为方便计算,假设你的店新开张,总共5个顾客来消费了,分别是在1点,2点,3点,4点和6点到的,此时我们可以把整个营业时间划分成6个时间段,那么每个时间段顾客来与不来其实就是一个服从伯努利分布的随机变量。假设每个时间段内来顾客的概率是 p, 那么一天内来5个顾客的概率就是 \(C_{6}^5 p^5(1-p)^1\)。
看到这你肯定在想了,那如果第一天开张来了10个顾客呢?是的,你的想法很好。此时我们可以把时间段划分的更加小,可以是秒也可以是分钟。我们假设总共划分了\(n\)个时间段,当\(n\)趋于无穷小的时候,每个时间段也就趋于无穷小了,那么在这\(n\)个时间段来了\(k\)个顾客的概率(一个时间段内最多只有一个顾客出现或者没有顾客)是
发现了没,这不就是二项分布吗?所以这也就解释了前面我们说泊松分布可以简单地是伯努利(或二项)分布的在时间段是极限小的情况。因为我们说抛硬币的时候通常是不考虑时间的,即基本上不会说我们每分钟或者每秒抛一次硬币,而泊松分布是将时间划分成若干个时间段,而这个时间段的大小视情况而定。
因为连续时间上的泊松分布被转化成了二项分布,而二项分布的期望是
所以在这\(n\)个时间段来了\(k\)个顾客的概率
我们把这个概率带入到上面的极限中去可以得到(推导过程省略了)
可以看到当时间段趋于无穷小时,最终得到的概率是与\(n\)无关的,只跟均值和你想预测的\(k\)有关。一般会把\(\mu\)用\(\lambda\)表示,所以泊松分布下的概率质量函数(注意泊松分布也是离散的概率分布)是
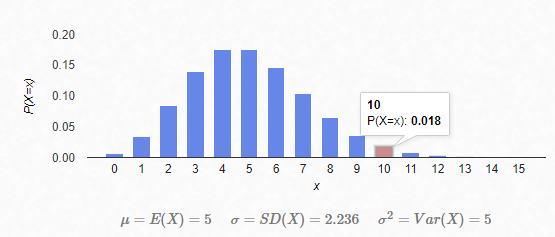
那么根据今天新开张的数据,均值\(\mu\)(或者说\(\lambda\))的值就是5,开门营业的时间越久,才会评估越准确。我们用这个网站画出了概率质量函数,可以越靠近均值,概率越高。另外来10个顾客的概率只有0.018。所以说你还是趁早把店铺转租出去吧,好好进厂里搬砖吧。
指数分布
指数分布是从泊松分布推断出来,泊松分布考虑的是在时间间隔足够小的情况下每天来的顾客的数量的概率,而指数分布考虑的是时间间隔的概率。比如你想求出\(T\)个时间段内都没来一个顾客的概率,这就等价于k=0,即 \(P(t>T)=P(X=0)=e^{-\lambda}\)。把时间t作为变量对泊松分布公式稍微扩展一下就得到了指数分布
同理
所以指数分布的累积分布函数是
对 \(F(t)\)求导后可以得到概率密度函数(注意这里不是概率质量函数了,因为指数分布是连续分布):
对应到上面的例子,\(\lambda\)是每天来的顾客数量均值,假设是5,我们可以画出此时的指数分布的概率密度函数
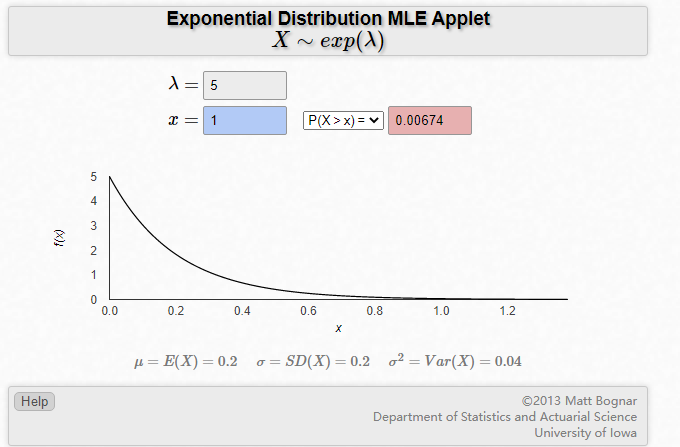
因为我们上面的例子考虑的是每天的顾客数,所以\(x=1\)时,计算得到的\(p(X>1)\)表示超过1天都没有顾客的概率是0.00674,这表示你开的店每天大概率还是有人回来关顾的哈哈哈
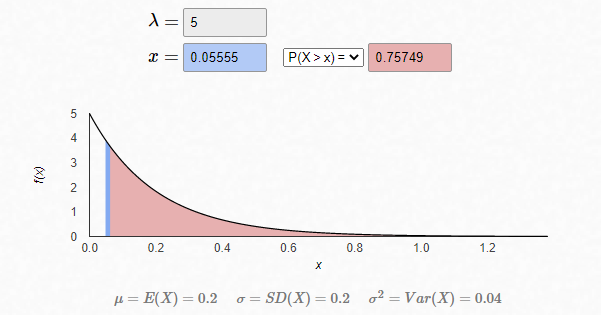
当我们把\(x=\frac{1}{18}\approx 0.0555\)时,就表示 超过 \(6*\frac{1}{18}=\frac{1}{3}\)小时 (20分钟)(因为你一天只开门营业6个小时)没顾客来的概率是0.75749。
因为指数分布有个特点是无记忆性,换言之,不管你从哪个时间点(比如下午1点或者2点)去计算 \(p(x>0.1)\),得到的结果都是一样的,即未来20分钟内没顾客来的概率是0.75749,所以你买出一个馒头后可以比较放心的打一把农药来打发时间。
注意泊松分布和指数分布的前提是,事件之间不能有关联,否则就不能运用上面的公式。
总结
伯努利分布 > 二项分布 > 泊松分布 > 指数分布 就是一个个套娃的关系。