1. 主要创新点
本文基于block-wise搜索空间做了一下的改进:
- 提出ensemble bootstrapping训练策略,这样可以不用教师网络,避免引入biased supervision (candidate preference和teacher preference)
- 提出了 非监督的评估指标(公式5)
- 在三个不同的搜索空间和数据集上都取得了不错的效果
- 基于MBConv的搜索空间,在ImageNet上取得了0.78的Spearman相关系数
- 基于NATS-Bench \(S_S\)搜索空间,在CIFAR-100上取得了0.76的Spearman性关系数
- 提出了HyTra (即CNN+Transformer混合模型)的搜索空间,在ImageNet上取得82.5%的accuracy,比EfficientNet高2.4%。
2. Methods
2.1 Ensemble Boostrapping训练Supernet
BossNAS整体的的训练方式和DNA不太一样,在DNA里,学生网络每个block彼此之间的训练是独立开来的,比如学生网络 \(block_k\)的输入是教师网络 \(block_{k-1}\)的输出,然后使用知识蒸馏(MSE loss)来使得学生网络的输出尽可能和教师网络输出保持一致。BossNAS认为这样会使得搜到的子网和教师网络高度相关,即搜索结果是带有bias的。
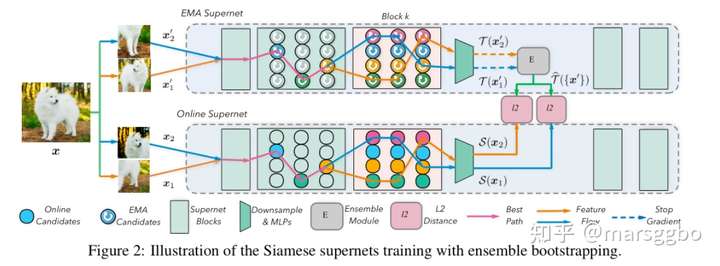
为了解决原本block独立训练的问题,BossNAS提出了Ensemble Bootstrapping策略
记\({S(W, A), T (W^T , α^T )}\)分别表示学生和教师网络(由权重W和结构A决定)。为了拜托教师网络带来的束缚(即学生网络很可能会非常像教师网络的结构,导致bias和diversity低),教师网络和学生网络是一样的,即\(\alpha^T=A\)。更具体地说,教师网络是用EMA策略更新的Supernet,学生网络就是常规的Supernet。
假设某个搜索阶段,我们采样了 p 个不同的子网,因为使用自监督训练方式,所以对于同一个样本会有 p 组不同的增强样本 (上图中 p=2),所谓 Ensemble Bootstrapping其实就是教师网络的第 k个block的输出是这 p 个网络输出的平均值,记为
上面公式中的 \(\mathcal{W}^{\bullet}\) 表示教师网络的权重,是使用EMA更新的,即 \(\mathcal{W}_{t}^{\bullet}=\tau \mathcal{W}_{t-1}^{\bullet}+(1-\tau) \mathcal{W}_{t}\), 其中 \(\mathcal{W}_t\)是online Supernet(学生网络)的权重。
因为每个block彼此之间训练独立,所以每个block优化方式是一样的,这里给出学生网络第k个block的优化函数。简单理解就是子网的输出要和ensemble的结果接近,损失函数使用的也是MSE。
那一个完整的优化函数表示如下:
2.2 Search subnets
2.1节介绍了如何训练Supernet。在训练结束后,BossNAS使用进化算法基于训练好的权重选择模型结构。类似于公式(1)中对教师网络不同路径做ensemble,在搜索的时候也会对学生网络不同路径做ensemble,第 k 个block输出的ensemble结果表示如下:
最后最优的网络则是每个block的输出最接近ensemble的输出,优化函数表示如下:
3. CNN-Transformer混合搜索空间
3.1 Candidate Blocks
3.2 Hybrid CNN-Transformers
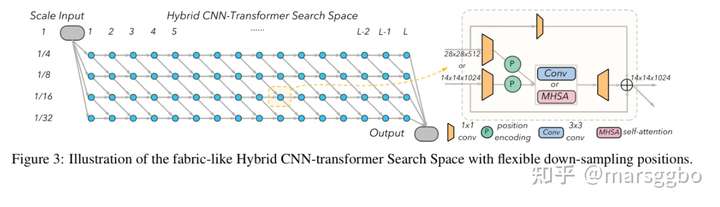
完整的模型结构如下图示,不仅会搜每一层的block结构,还会搜索每一层的下采样操作(控制resolution)。
4. Experiments
4.1 Setup
每个block训练20个epoch,其中第一个epoch是warmup epoch。每个training step随机采样4条路径。
4.2 搜索Hybrid CNN-Transformer的结果
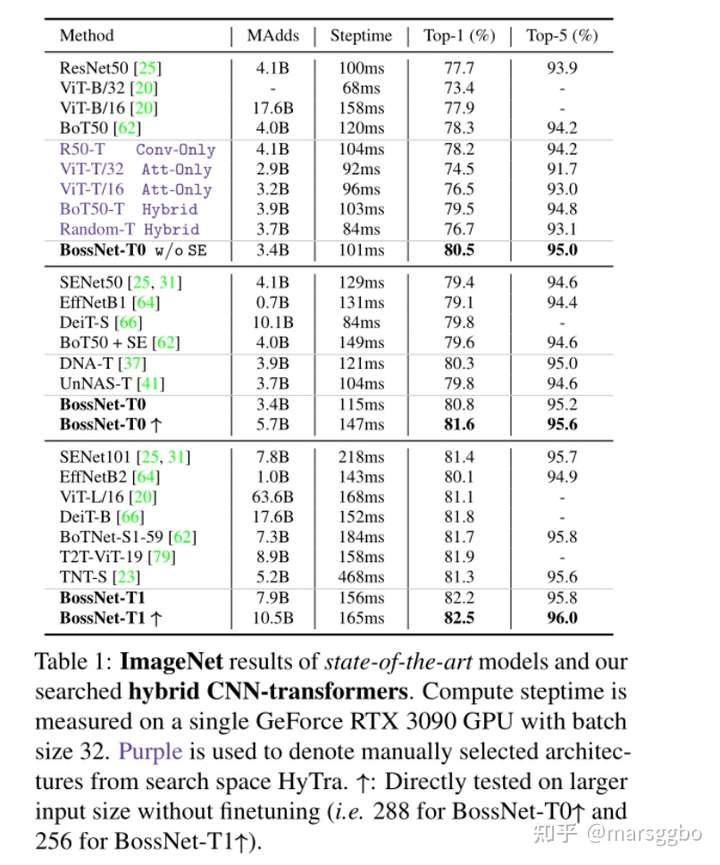
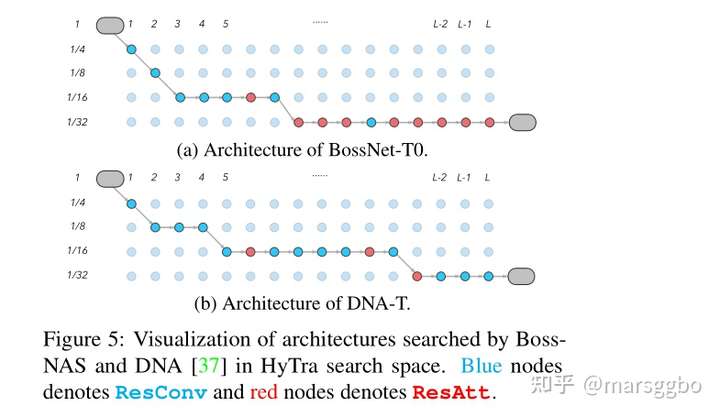
上图给出了使用DNA算法和BossNAS算法在相同的HyTra搜索空间上搜到的网络结构,可以看到 DNA搜到的网络更倾向于选择卷积操作,作者对此的解释是因为DNA使用了教师网络,而教师网络本身带来了biased supervision。文章把这一现象称作 candidate preference。
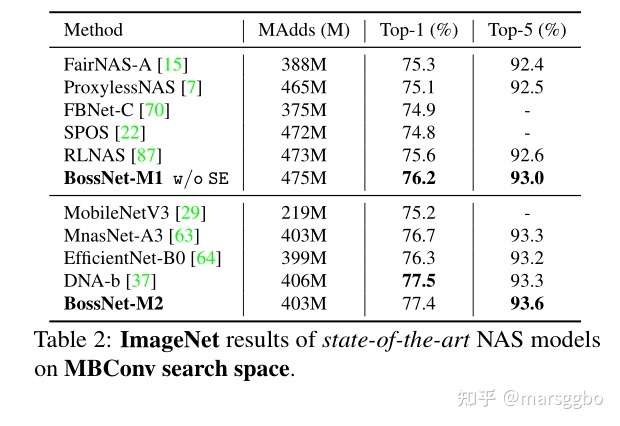
4.3 在MBConv 搜索空间上的结果
最终模型在ImageNet上的结果如下表,可以看到BossNAS结果的优势有一丢丢,但不明显
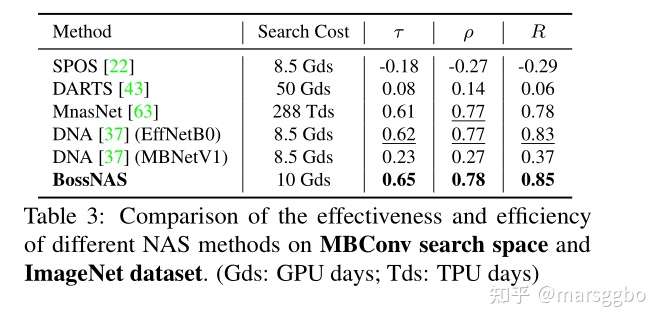
作者进一步比较了搜索一致性结果(Kendall tau: \(\tau\), Pearson: \(R\), Spearman: \(\rho\)),相关性结果是基于 DNA 提供的23个模型结构和acc计算得到的,结果如Table 3所示。可以看到MnasNet相关性还不错,但是由于是multi-trial方法,所以耗时巨大。 另外我们还可以看到 教师网络 的选择对DNA算法影响非常大。文章将这个现象称作 teacher preference 而BossNAS完全不需要teacher network。
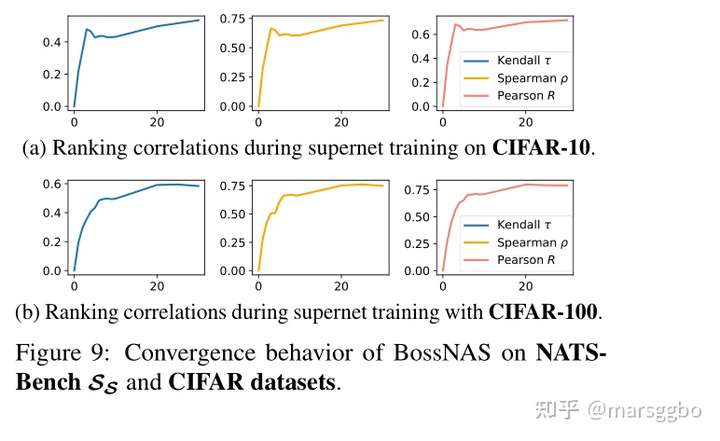
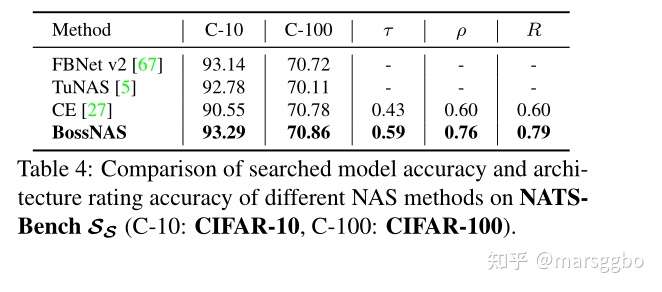
4.4 在 NATS-Bench \(S_S\)搜索空间的结果
该搜索空间基于CIFAR10/100进行试验。
4.5 Ablation Study
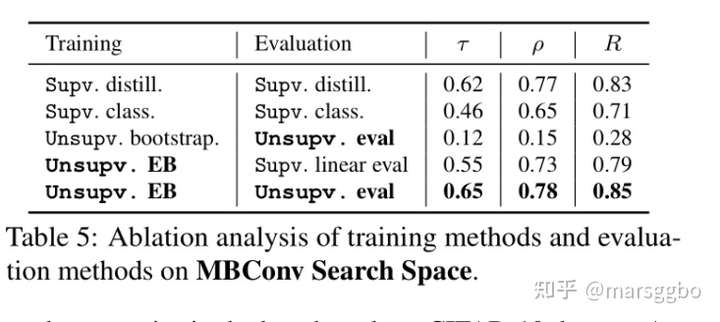
BossNAS的训练和评估都是非监督的,为此作者对比了不同的训练和评估方法对最终结果的影响,结果如Table 5所示。
Training
- Supv. distill. 表示supervised distillation,其实就是DNA算法,即对中间层做监督学习
- Supv. class. 即对最后输出层使用真实label做监督学习
- Unsupv. bootstrap,和本文方法类似,只不过是教师网络和学生网络对应的相同路径做知识蒸馏
- Unsupv. EB: 学生网络的所有路径和教师网络的ensemble结果做知识蒸馏
Evaluation
- Supv. distill. 和 Supv. class类似,就是根据学生和教师网络输出的相似度来评估网络的好坏
- Supv. linear eval 表示supervised linear evaluation。这个是最常规的权重共享的NAS评估方法。具体来说该方式是首先把supernet权重固定,然后finetune一个权重共享的线性分类器。这个分类器会和所有子网相连接,每个子网的排序就是根据分类器最后得到的accuracy结果决定的。
- Unsupv. eval就是本文的方法,如公式 (5)
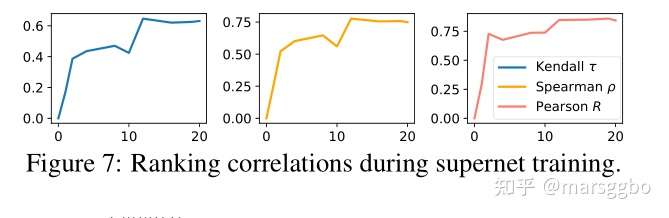
4.6 收敛表现
前面已经提到过,BossNAS的每个block只训练20个epoch就结束了,下图就给出了在MBConv搜索空间上,基于ImageNet数据集每个epoch对应的搜索一致性结果。可以看到基本上在第12个epoch的时候一致性基本上就固定了,另外前期相关性能够快速地提升。
在NATS-Bench上已有类似的结果