1. 介绍
早期的NAS算法大都是针对某一个具体的硬件平台做模型搜索。换句话说,对于新的平台则需要重新搜索,这样既耗时又耗资源。所以这篇文章(简称OFA)的主要目的是只需要搜索一次就能为不同的平台找到合适的模型结构,所以论文名字取为 Once for All。
2. 搜索空间
OFA采用的也是权重共享的搜索策略,Supernet结构基于MobileNet的设计。
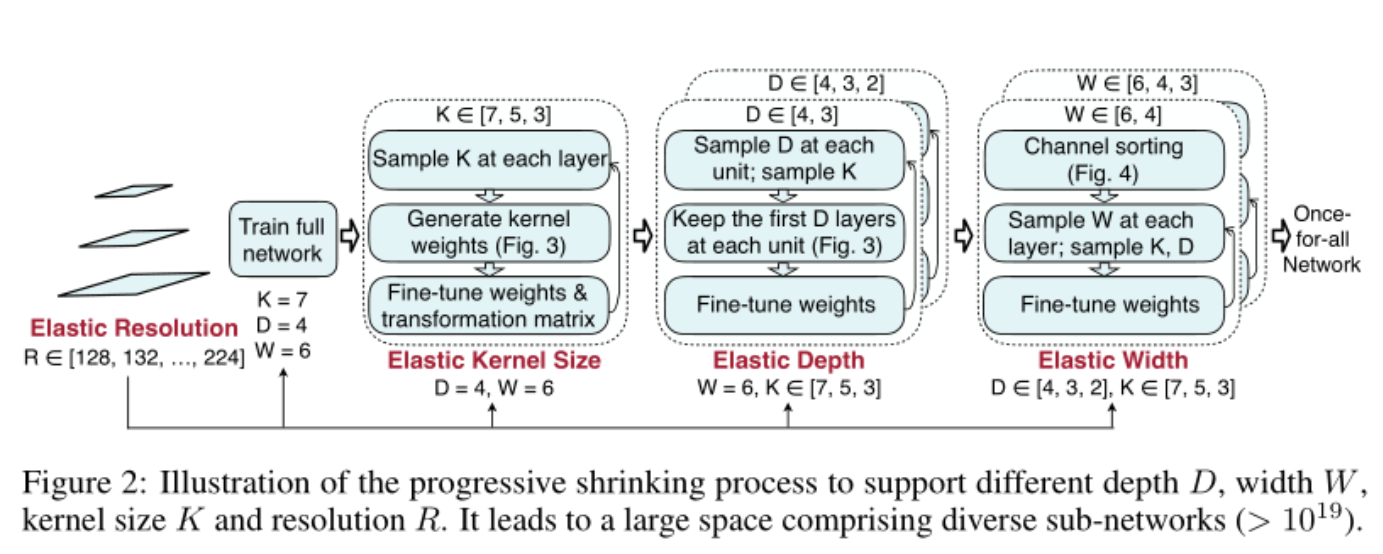
整个搜索空间(如Figure 2)主要包含三大块:
- Depth (D):Supernet可以看成是由多个Block组成的结构,而每个Block包含不同数量的layers,即为深度(Depth),论文中每个Block的layer数量搜索范围是 [4,3,2]
- Width (W):每个layer可以理解成是一个inverted residual module,其通道数由expand ratio控制,即为宽度(Width),论文中每个layer的expand ratio搜索范围是 [6,4,3]
- Kernel size (K):这个很好理解,就是卷积核大小。论文中搜索范围是 [7,5,3]
- OFA还额外搜索了不同分辨率的ImageNet数据输入,这可不会对模型结构有什么影响,只不过能提高模型对不同大小的数据的泛化能力
OFA中的Supernet由5个block组成,而每个block的搜索空间大小是 (S_i=(3 imes3)^2+(3 imes3)^3+(3 imes3)^4),所以整个搜索空间大小为(S=prod_1^5S_iapprox2 imes10^{19})
3. 搜索策略
再强调一遍,OFA的目的希望是只做一次搜索,之后就可以根据这个搜索的结果自动去找适合于指定平台的模型结构。
形式化的数学表达如下:
说人话就是 让所有候选架构在验证集上的结果都尽可能的好,即最小化所有架构的期望损失函数之和。
但是搜索空间非常大,不可能遍历所有模型,所以一个很naive的思路是是通过随机采样的方式来近似优化。但是如何采样确实很有门道的,OFA就提出了 渐进式收缩 (progressive shrinking, PS)的采样策略.
其实,PS 这个策略其实也很符合直觉,我们看Figure 2,它把整个训练过程划分成多个phases:
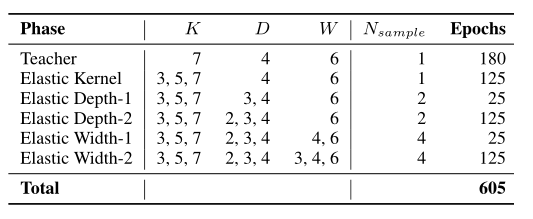
- Full Network:首先就是训练最大的模型,即每个Block由4个layer组成,每个layer的通道expand ratio设置为6,kernel size设置为7。这个模型会作为Teacher net来做知识蒸馏。这一过程使用32个GPU训练了180个epoch,batch size为2048,使用初始学习率是2.6的SGD优化器。
- Elastic Kernel Size:之后固定D和W,搜索K,每次只采样一个模型。训练了125个epoch,初始学习率是0.96,其余参数和phase-1一样
- Elastic Depth:固定W,搜索D和K。这个phase又划分成了两个stage:
- stage-1:D的搜索范围是 [4, 3],训练了25个epoch,学习率是0.08
- stage-2: D的搜索范围是 [4, 3, 2],训练了125个epoch,学习率是0.24
- Elastic Width:同时搜索D,K,W。类似Phase-3,这个过程也分成了两个stage,不再赘述。
4. 算法实现细节
4.1 搜索Kernel Size
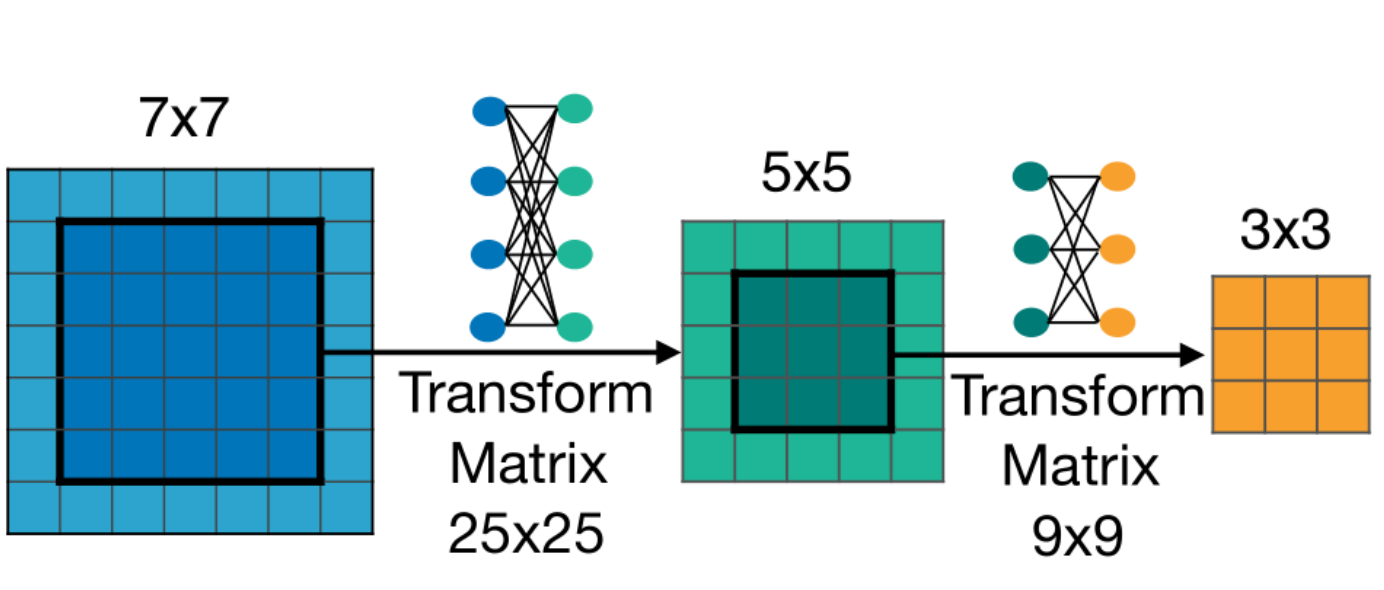
卷积核大小搜索范围是 [3,5,7],在算法实现层面其实是共用一个7X7的卷积核,而要得到5X5的卷积核,OFA的做法是先截取中间的5X5的矩阵,然后把这个矩阵展开成一维向量,长度为25,然后再通过一个25X25的可学习的矩阵得到新的5X5的卷积核。3X3的卷积核的处理办法类似,不过是基于变换后的5X5卷积再做变换得到的。
4.2 搜索Depth
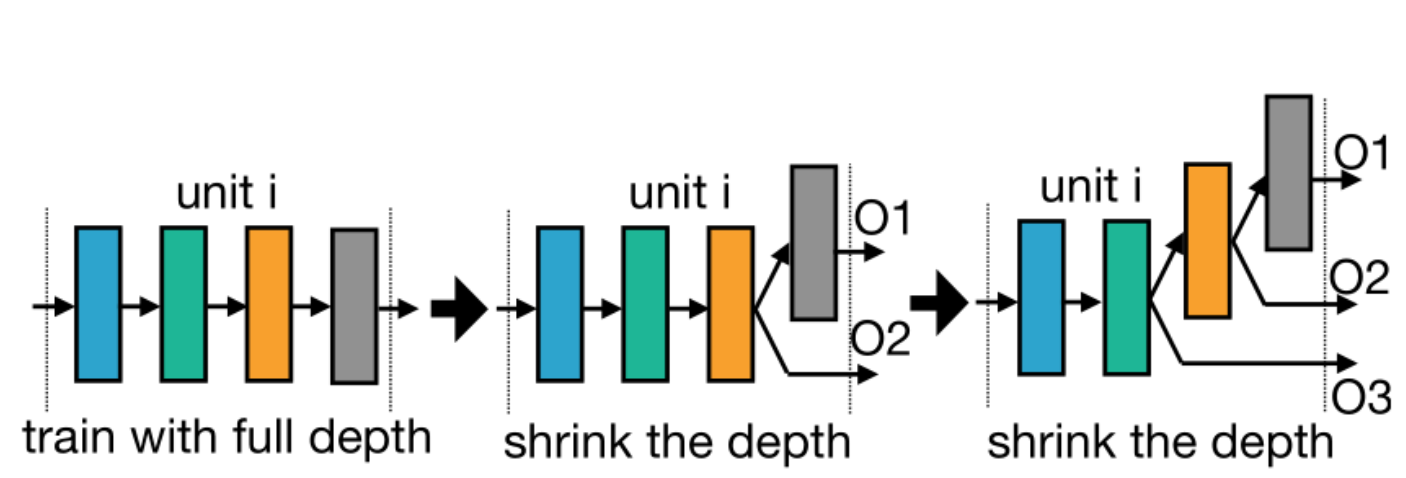
上图中的Unit可以理解成Supernet中的一个Block,所有Block初始化都是由4个layer组成。
在搜索depth的时候,假如搜索的结果是3,那么最后一个layer就不会参与计算。(如上图第二个unit所示)
4.3 搜索Width
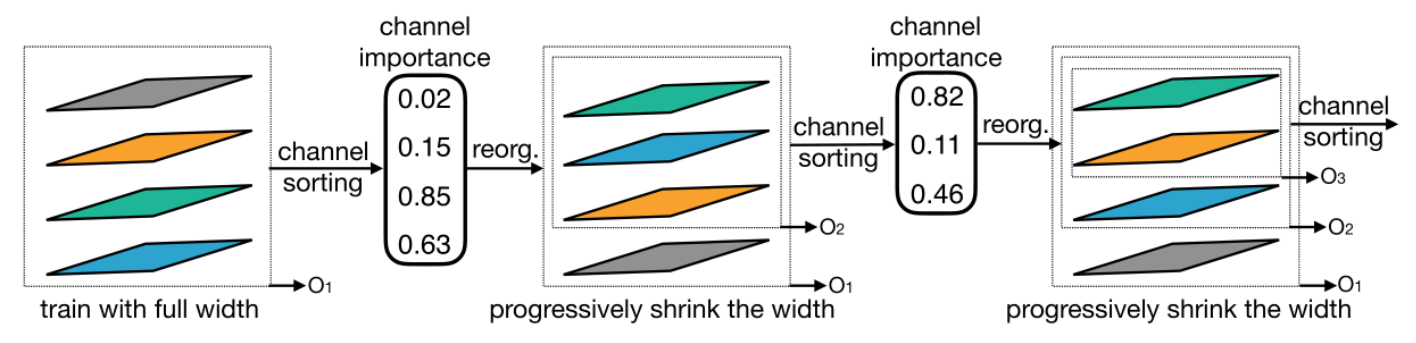
宽度的搜索其实就是通道数的搜索,OFA提出的策略是根据L1norm计算每个通道的重要性,然后对这些通道排序,最重要的排前面。比如总共有10个通道,某一时刻搜索的结果是只需要5个通道,那么就会对这个10个通道做排序,只用前5个通道做计算。我有试过这种策略,一旦对通道权重重新排序后,模型性能就会崩掉了,不过具体是我复现的代码有问题还是其他问题就没有细究了。
5. 实验结果
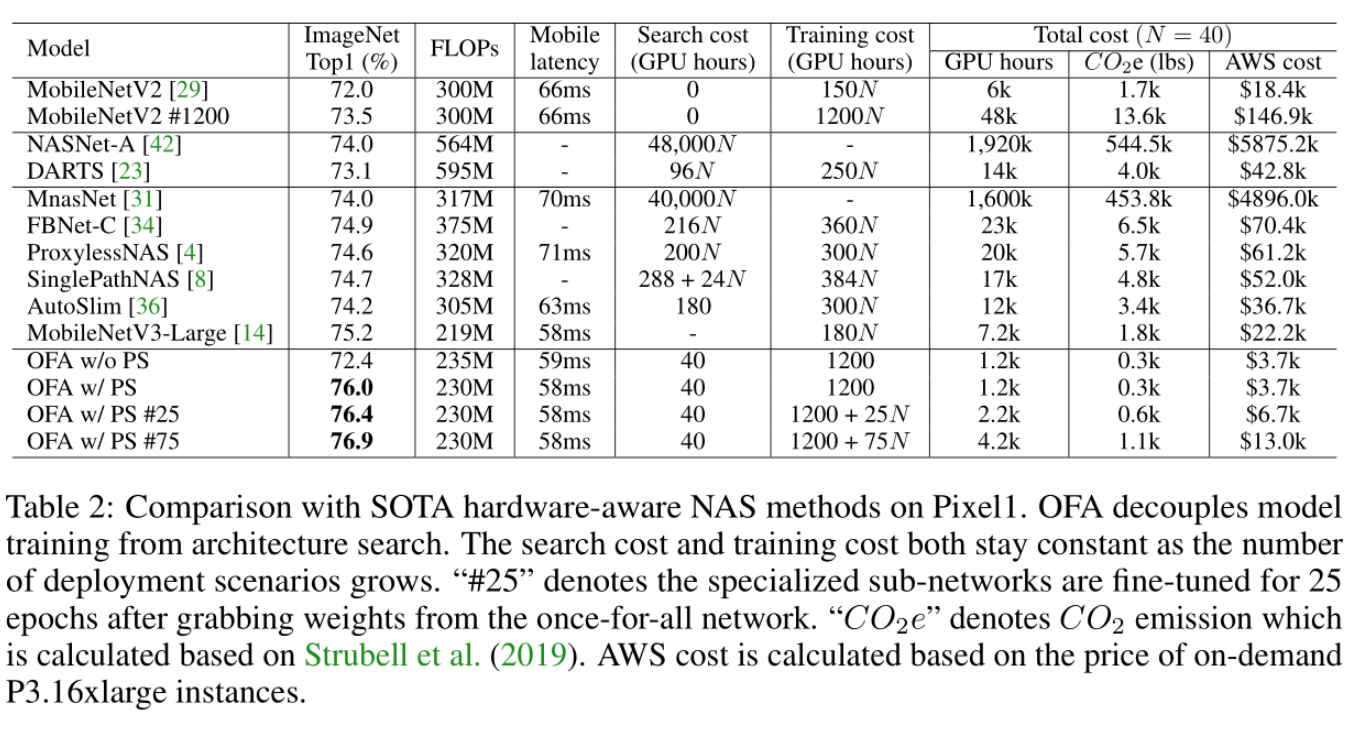
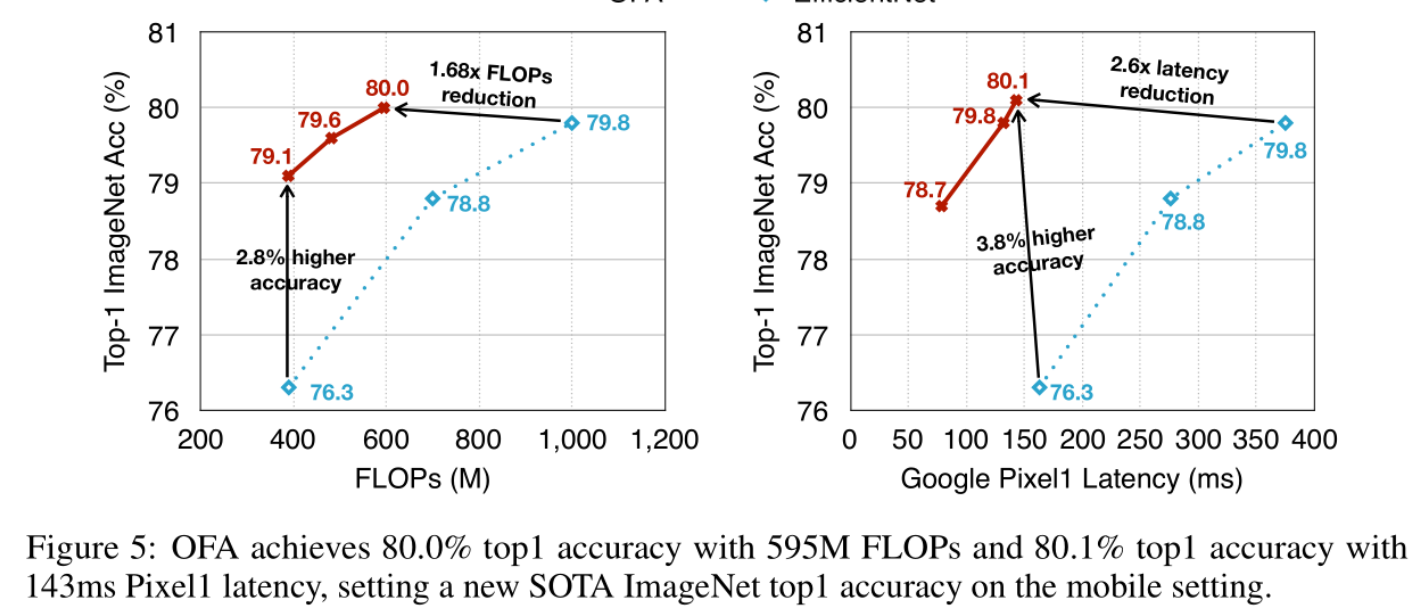
微信公众号:AutoML机器学习

MARSGGBO♥原创
如有意合作或学术讨论欢迎私戳联系~
邮箱:marsggbo@foxmail.com