本文笔记参考Wang Shusen老师的课程:https://www.youtube.com/watch?v=Vr4UNt7X6Gw&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=9
1. 前言
2015年,在文献[1]中首次提出attention。到了2016年,在文献[2]中提出了self-attention方法。作者将self-attention和LSTM结合用在了机器阅读任务上。为了好理解,下文将LSTM表示成SimpleRNN。
在阅读以下内容之前,强烈建议先看看之前关于attention机制的文章介绍:Transformer自下而上(2) 注意力(Attention)机制。
2. SimpleRNN (LSTM)
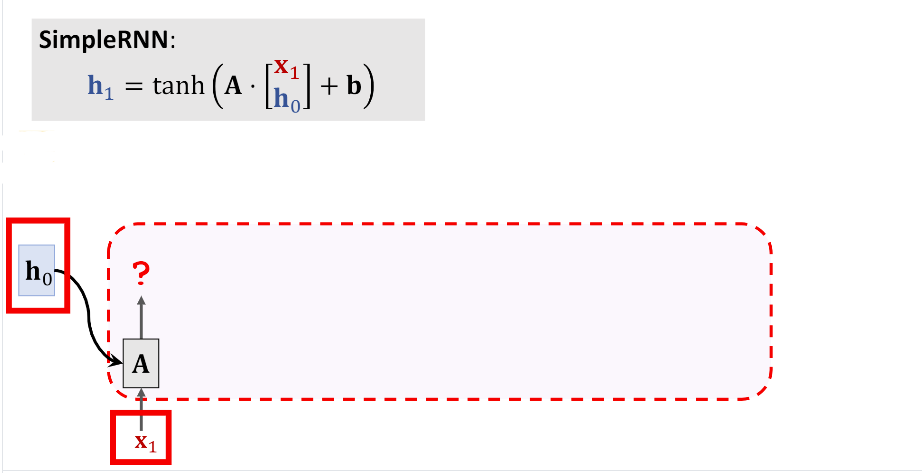
由下图可以看到传统的LSTM的第一个输出(h_1)只依赖于两个输入(x_1)和(h_0)
3. SimpleRNN + Attention
下面我们会逐项介绍计算过程。
3.1 计算(h_1)和(c_1)
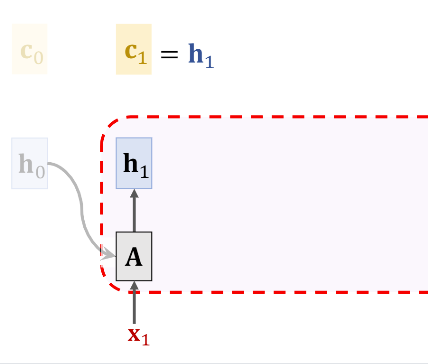
下图给出了加入Attention机制后的示意图,可以看到和Fig 1. 的区别在于我们把(h_0)替换成了(c_0)。由于(h_0)和(c_0)是已经初始化好了的,所以根据下图中的公式我们能直接计算出(h_1)

接下来我们需要计算(c_1)。Attention的目的是为了避免遗忘,所以一种很自然的思路就是(c_i)是所有之前状态({h0,..,h_{i-1}})的加权求和,他们的权重分别是({alpha_0,...,alpha_{i-1}})。由于通常(h_0)初始化为0向量,所以(c_1=h_1)
3.2 计算(h_i)和(c_i)
看完(h_1)和(c_1)的计算是不是还有点懵,没关系,下面我们加大学习力度,重复多看几次计算过程。
计算(h)的方法千篇一律,都是那当前的输入(x_i)和前一时刻的context vector (c_{i-1})拼接成一个向量后参与计算,即
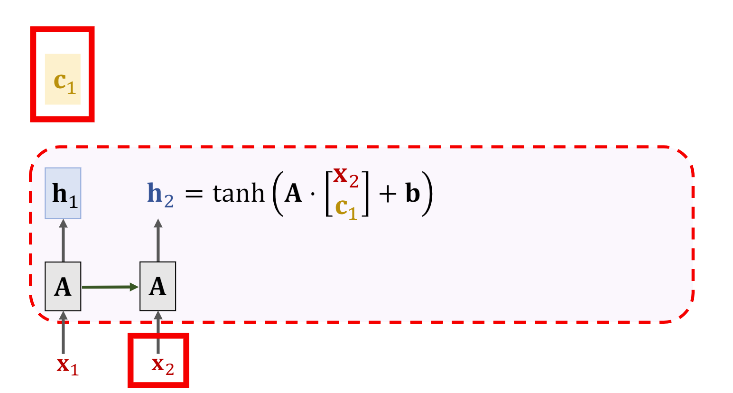
下一步是计算(c_2)。(c)的通用计算公式可以写成 (c_i=alpha_1 h_1+...alpha_{i-1} h_{i-1})
权重(alpha_i)的计算公式为
上面的(align)可以有不同的实现方法([3]),你只需要知道(alpha_i)表示(h_i)和(h_2)之间的权重(或者是相似度),计算出所有的(alpha_i)之后我们就能计算出(c_i)了,这里(c_2=alpha_1h_1+alpha_2h_2)

3.3 再计算一次
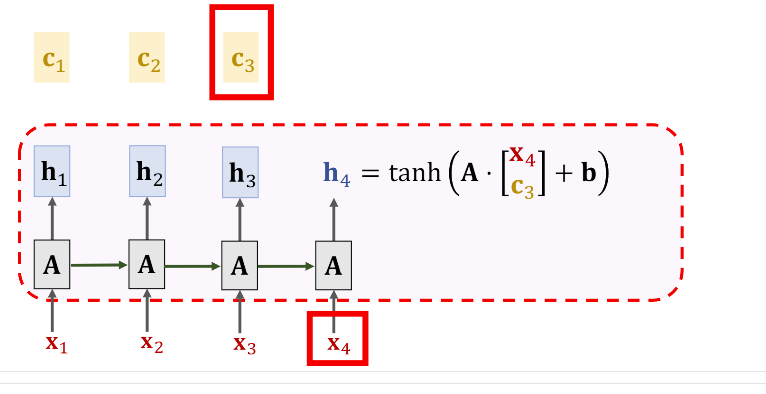
同理,要计算(c_4),我们仍然要通过使用(align)计算符计算出不同的(alpha)。
注意,Fig 7里的(alpha_1,alpha_2,...)和Fig 5里的(alpha)是不一样的,这里只是为了方便讲解。也就是说每计算新的(c)都要计算一遍不同的(alpha)。为了计算这些权重,我们每次都会遍历一遍之前的数据,所以这样可以有效解决SimpleRNN遗忘的问题。

参考文献
[1] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. In ICLR, 2015
[2] Cheng J, Dong L, Lapata M. Long short-term memory-networks for machine reading. In EMNLP, 2016
[3] Transformer自下而上(2) 注意力(Attention)机制 (https://zhuanlan.zhihu.com/p/374841046)