省流总结
Retiarii意思是 网斗士,是古罗马以仿渔夫装备——手抛网(rete)、三叉戟(fuscina 或 tridens)和匕首(pugio)进行搏斗的角斗士。官方的解释是因为神经网络可以看成是一个网,然后Retiarii就是去搜索网的斗士,哈哈哈,有点意思~~
Retiarii的主要贡献有三点:
- 提供了搜索空间和搜索策略的接口,我们可以基于这个接口灵活地设计我们自己的算法,而且这两个接口功能是解耦的,也就是说你定义好一个搜索空间后,可以无痛切换不同的搜索策略,而早期很多算法搜索空间和搜索策略是强耦合在一起的,牵一发而动全身,魔改起来很让人头痛
- 实现了Just-In-Time(JIT) 引擎。Retiarii框架下模型会被表示成graph,JIT引擎的作用就是将graph实例化为模型,收集搜索过程中产生的信息,并执行指定的策略等
- 实现了一系列跨模型(cross-mdoel)的优化方法来提高搜索效率。因为权重共享是在实现NAS时比较常用的一种策略,也就是说搜索空间内的子模型彼此之间有不少模块都是overlap的,对于共享的模块我们显然没必要重复定义和训练,所以Retiarii对这个需求做了优化。
1. 前言
神经网络架构搜索(NAS, Neural Architecture Search)俨然成为目前最热门的AI研究方向之一,它的目的是让算法去找到最优的模型结构,将人们从繁琐的调参和试错中解救出来。如果你对NAS技术还不太熟悉,建议你参考阅读一下我之前的文章AutoML综述。
NAS领域比较经典的工作有ENAS(基于强化学习),DARTS(基于梯度下降),AmoebaNet(基于进化算法)等等,可是这些算法的实现各不相同,想要把这些算法移植到自己的任务上难度不小,而且辛辛苦苦地魔改了很多地方还不一定能跑起来,总之这就是目前NAS研究的一个窘境。根本原因是因为现有的Deep learning框架,如Pytorch和TensorFlow本身对NAS这个需求的支持不是很好。
因此,有不少工作尝试自动化来减轻工作量,例如AutoSklearn,TPOT,H2O.ai, Auto-Weka,Google Vizier及其开源实现Advisor,这些主要是对传统的机器学习算法(例如SVM,决策树等)做超参数搜索。实现对神经网络架构进行搜索的框架有 Auto-Keras,亚马逊的AutoGluon,华为的Vega。
本篇文章主要介绍微软发表在OSDI2020的工作 《Retiarii: A Deep Learning Exploratory-Training Framework》,现已集成到其开源框架NNI。
2. 现有框架的痛点
痛点一:搜索空间的设计
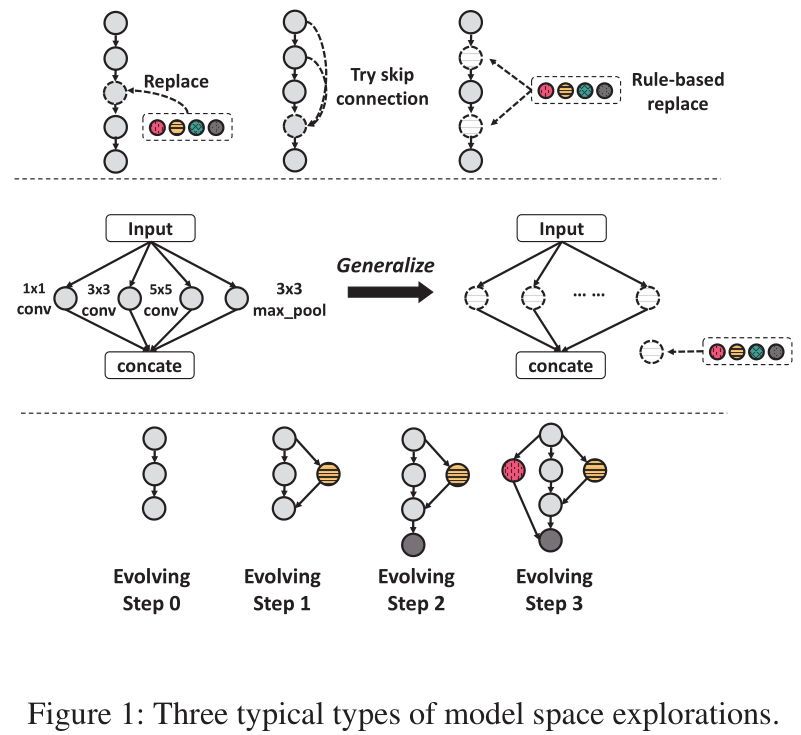
下图总结了现有NAS算法中涉及到的不同搜索空间的设计方式,分成了三大类
- 第一类是对单个或多个节点(节点也可以是一个复杂的模块)做替换操作,或者增减某个节点的输入
- 第二类是比较常见的cell结构,它和上面的替换其实有点类似,只不过差别在于这种设计方式可以使得子网络之间共享权重,但是显然灵活性没有第一类高
- 第三类也可以叫做network morphism的操作,无中生有,暗度陈仓。不过新的节点的生成是要以来一定规则的,相关原理可以阅读这篇论文 Net2Net: Accelerating Learning via Knowledge Transfer
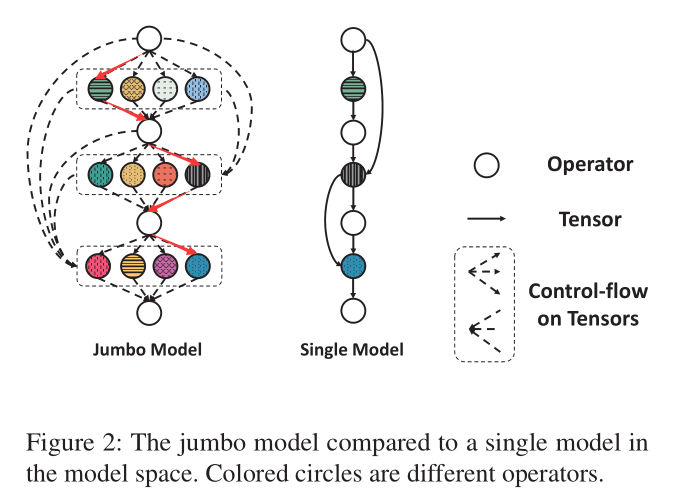
目前很多开源的NAS代码在实现各自的搜索空间时,以pytorch框架为例,都会在__init__和forward函数中添加逻辑控制语句,最后实现的模型非常臃肿。比如基于权重共享策略的ENAS和DARTS在搜索过程中虽然可能每次只更新某个比较小的子模型,但是整个supernet都放在了计算图中,而且由于前向传播过程中有很多逻辑控制,导致即使很小的模型跑起来也很耗时。
这个我自己之前跑实验也深有体会,DARTS的某个子模型的大小比resnet18小不少,但是同样跑一个batch的数据,resnet18就快不少。如果我没理解错的话,Retiarii的解决办法就是每次会实例化一个小模型(下图中的single model),而不是通过逻辑控制语句模拟了一个小模型(下图中的Jumbo model)。
痛点二:搜索策略和搜索空间高度耦合
如果你读过ENAS和DARTS的源代码你会发现,他们设计的搜索算法是与模型高度耦合的,虽然理论上他们的算法思路适用于很多模型的搜索,但是他们设计的接口不具备较强的通用性,Retiarii则尝试解决这一问题。
3. Mutator
我们知道现有框架定义DNN其实可以等加成数据流图,即data-flow graph (DFG), Retiarii也遵循这一思路,即每个节点(node)表示一个操作或者是一个子图,而每条边(edge)是有方向的,其表示数据的流动方向。
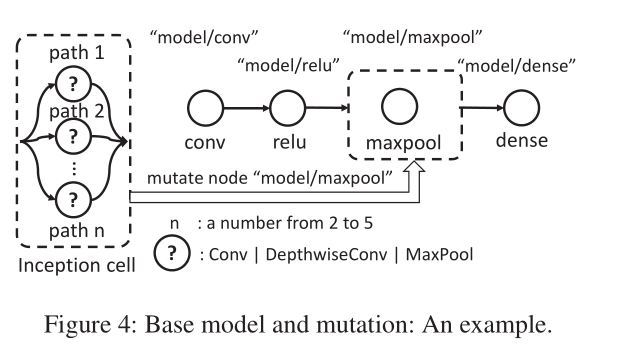
在Retiarii中,搜索初始时刻的模型定义为base model,如下图示。其中的maxpool节点被定义为Mutator类,其可以变化成一个Inception cell,而这个cell本身也可搜索的,因为我们知道Inception模块有多条路径,那么每条路径上的结构是什么可以通过搜索来确定。
所以,搜索空间={base models + 对base models做mutation后产生的模型集合A + 对集合A做mutation后得到的模型 集合B + ...},换句话说随着不断搜索,base model的数量会从最初的一个变得越来越多,所以后面加了复数。
下面代码中给出了Mutator的一些基础操作,包括创建和删除节点,连接,更新节点参数,以及从多个candidates中选择一个或多个操作。
create_node(name:str ,op:Op,params:dict={})
delete_node(node:Node)
connect(src:NodeOutput ,dst:NodeInput)
del_connect(src:NodeOutput ,dst:NodeInput)
update_node(node:Node ,op:Op=None ,params:dict={},inputs:list=None)
choose(candidates:list ,n_chosen:int=1,type:str="choice",ctx:dict=None)
下面给出了Inception Cell的代码实现,可以看到其需要传入两个参数,paths_range表示边的数量范围,这是可搜索的,以及每条边上连接的节点的候选操作candidates。可以看到通过mutate函数实现了搜索和替换操作。
# define the graph mutation behavior
class InceptionMutator(BaseMutator):
def __init__(self , paths_range , candidate_ops):
self.paths_range = paths_range # [2, 3, 4, 5]
self.ops = candidate_ops # {conv , dconv , ...}
def mutate(self , targets):
if not three_node_chain(targets):
return err
n = choose(candidates=self.paths_range)
delete_node(targets[1])
for i in range(n): # create n paths
op = choose(candidates=self.ops)
nd = create_node(name=’way_’+str(i), op=op)
connect(src=targets[0].output , dst=nd.input)
connect(src=nd.output , dst=targets [2].input)
# mutation applied to the graph
apply_mutator(targets=["model/relu", "model/maxpool", "model/dense"],
mutator=InceptionMutator(
[2, 3, 4, 5], [conv , dconv , pool]))
4. JIT引擎
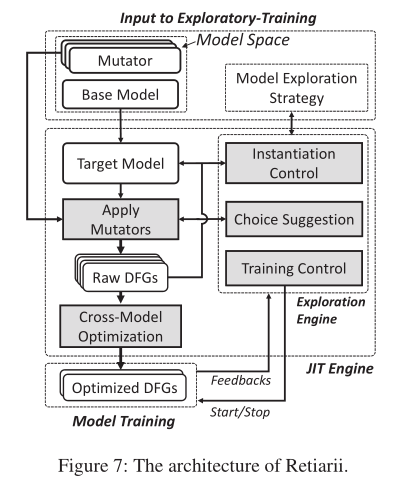
上图给出了Retiarii的框架的架构示意图,主要分成三个部分
- Input: Retiarii论文中将NAS理解为探索训练(Exploratory-training),第一部分就是输入,这个输入表示的是用户自定义的模型搜索空间(Mutator,Base Model) 以及 模型搜索策略(Model Exploration Strategy)
- JIT引擎是第二部分,也是整个框架的核心。它的运行思路是这样的
- 1)Instantiation Control:JIT首先根据用户指定的Exploration策略来确定本轮需要做mutation的目标模型(target model),以及需要采取什么样的
Mutator操作。上一节的代码中apply_mutator函数表示目标模型为["model/relu", "model/maxpool", "model/dense"],需要执行的变异操作是InceptionMutator。 - 2)Choice Suggestion:这个其实就是
Mutator类里面定义的mutate函数。通过(1)和(2)步骤,我们可以找到指定的Target Model,并对其Apply Mutators,进而生成若干个原始的DFG。 -
- Cross-Model Optimization: 这个的作用是对raw DFGs做优化,具体细节在后面一个小结介绍,你只需要知道这样做的目的是提高效率
- 1)Instantiation Control:JIT首先根据用户指定的Exploration策略来确定本轮需要做mutation的目标模型(target model),以及需要采取什么样的
- Model Training:JIT中的Training Control模块会管理生成的若干个实例化模型的训练过程,即解决可能存在的性能瓶颈,如CPU、GPU利用率问题
5. Cross-Model Optimization
前面介绍了,Retiarii是基于base models执行mutation操作来不断搜索不同的模型结构,那么很显然这些模型其实有很大一部分的结构(子图)是相同的。一般来说,找出两个graph的最大公共sub-graph是一个NP-hard问题,但是由于Retiarii中的所有Mutator都被定义了唯一的索引值或者是key值,所以可以很轻易地找到两个模型之间的最大子图。Retiarii主要从以下三个方面来对公共子图做了优化。
5.1 Common Sub-expression Elimination (CSE)
公共子表达式消除(CSE)优化算法常用来消除一个程序中的相似操作,下面举个简单的例子帮助理解,假如我们在代码里写了这么一串计算流程:
a = 1+2+3/8+6+25
b = 15+1+2+3/8+6
c = a + b
仔细观察可以看到变量a和b之间的公共子表达式是1+2+3/8+6,所以CSE要实现的目的就是把这个公共部分抽离出来,尽可能只执行一次,即
cse = 1+2+3/8+6
a = cse + 25
b = 15 + cse
c = a + b
这样1+2+3/8+6就只需要执行一次即可。
那么对应到NAS任务,我们知道子网络之间除了结构会有overlap的地方以外,数据预处理等操作基本上是一样的,所以Retiarii则通过CSE优化算法将子网络之间所有non-trainable的操作都merge在一起,因此只执行一次,从而大大提高了效率。注意,那些trainable的部分,比如重复的网络结构是没办法merge的,因为权重需要更新。
5.2 Operator Batchting
还有一个做跨模型优化的场景就是在transfer learning的时候我们搜索模型结构,可以对不同模型的相同operator做融合。
什么意思呢?假设我们现在需要对一个新的任务场景来搜索网络结构,但是我们已经有了一个比较好的base model,而且该模型已经有了预训练权重。我们的目的是基于这个base model的结构和预训练权重来搜索出新的模型结构。
假设我们通过执行mutation操作得到了如下图示的两个graph,其中灰色的模块表示之前base model中已有的结构,因为是transfer learning,其权重是固定的,所以属于non-trainable操作。
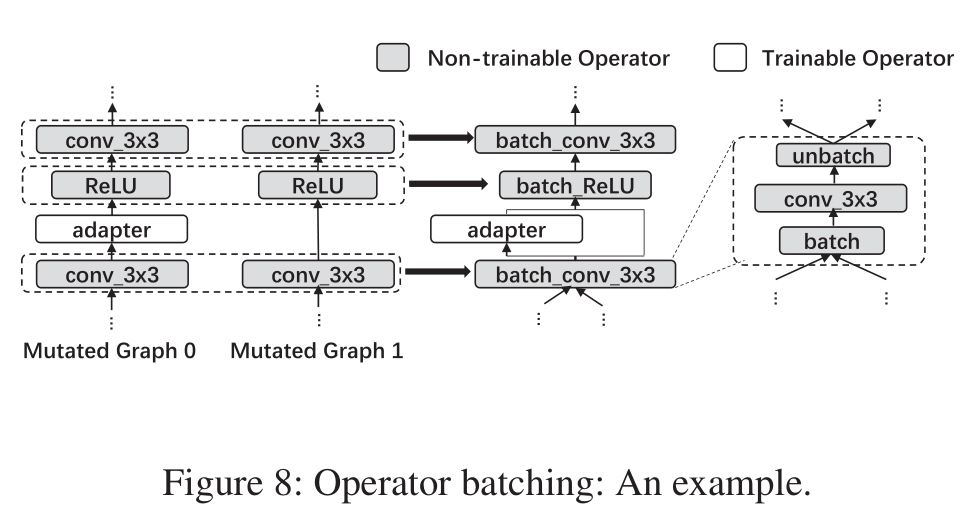
graph0和graph1的差别在于左边有个adapter,这个adapter就表示新插入的操作,它是一个可搜索可训练的模块。右边其实应该也有adapter,只不过没画出来而已,这里只是为了表示两个graph绝大部分的模型架构都是一样的。
上图中间部分画出了Operator Batchting的示意图,因为graph0和1的那些灰色模块是同样的结构,Retiarii的做法是把两个模型具有相同结构的部分合并在一起,我们看上图最右边,其实现方法是在合并后的operator的前后插入了batch和unbatch的操作,batch操作应该就是concatenate操作,即把原本两个模型的输入拼接在一起,这样就将一个operator合并了,提高了计算效率;类似地,unbatch操作就是把前面计算得到的feature tensor从batch的维度划分成两部分。
前面介绍的operator batching是假设他们的权重是相同的,例如第一个conv_3x3是有着相同权重的。其实即使权重不同也是可以做batch操作的,只需要使用比如grouped convolution或者batch_matmul等操作处理一下就可以了。
5.3 Device Placement of CSE-Optimized Graphs
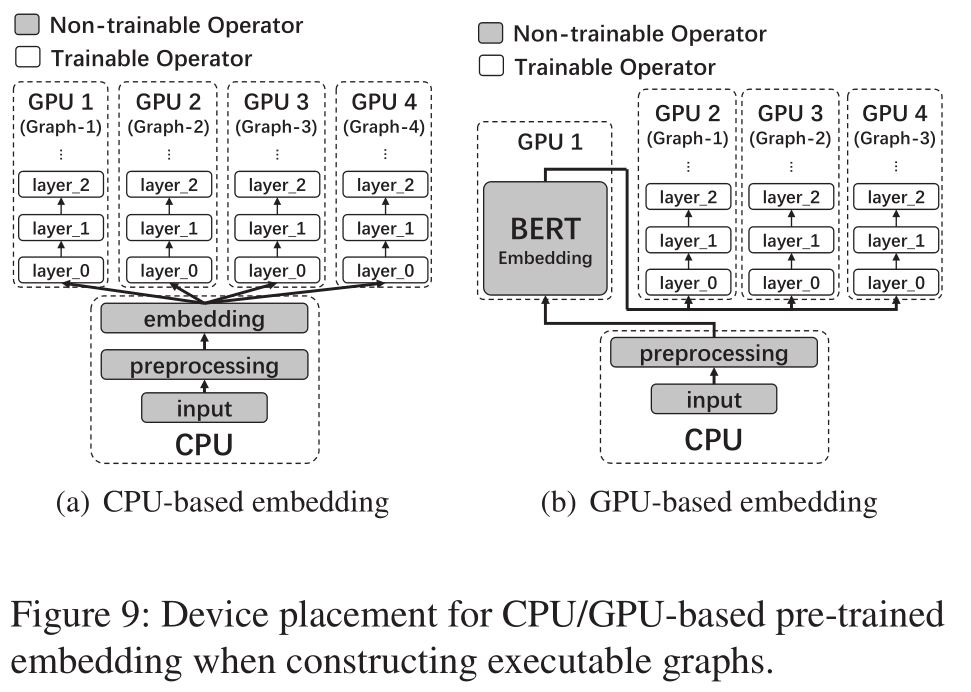
另一个跨模型优化的场景则是设备放置问题。我们看看上图就能知道是什么意思了,假设我们有4个GPU,每个GPU上对应一个Graph。这个任务预处理部分包含preprocessing(比如数据增广),embedding。如果embedding方法用的是word2vec,因为处理器来速度比较快,所以这个时候Retiarii会将这个操作放在CPU上执行。但是如果embedding操作是BERT网络,那这个时候CPU计算就会成为bottleneck,所以Retiarii就会牺牲掉一个GPU专门来计算BERT embedding,然后其他GPU共用这个embedding。
这个策略和Pytorch-lightning有点类似,实现方法就是预先跑几个iteration,profile一下iteration的时间,GPU的peak memory和利用率等信息,然后基于这些信息来分配设备和计算流程。
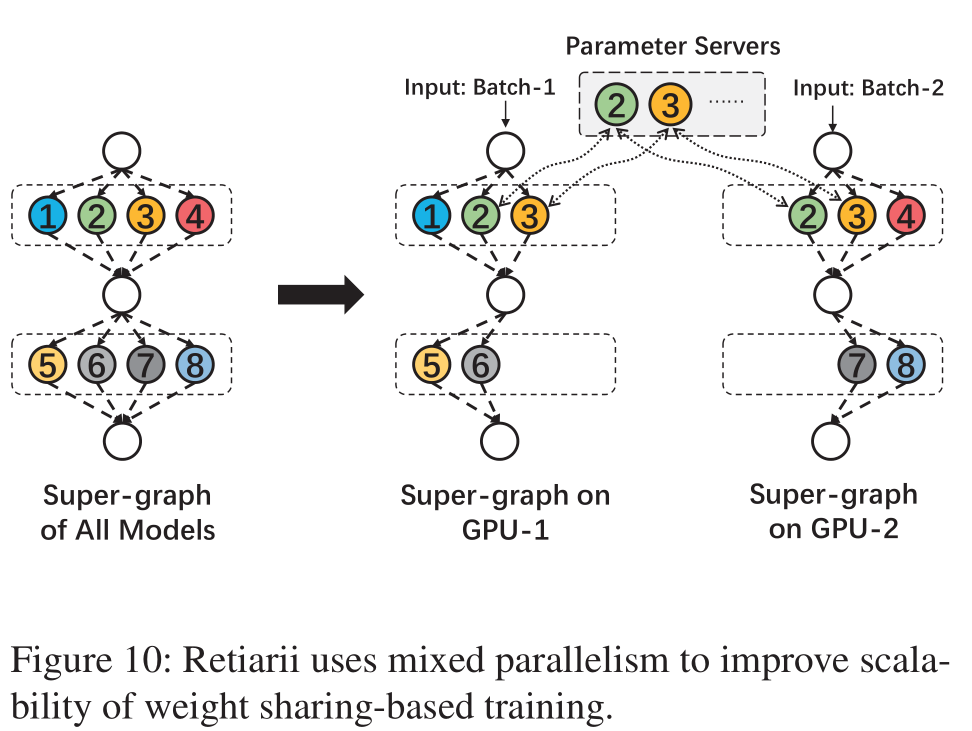
5.4 Super-Graph for Weight Sharing
常见的加速DNN训练的方式主要分成两种,一种是模型并行,另一种则是数据并行。
模型并行常见的应用场景比如说一个模型特别大,达到一个GPU都装不下,这个时候就人为地把模型划分成若干个部分,然后每个GPU负责不同部分的计算,只不过后一个GPU每次都需要等前一个计算的结果。当然也可以通过一些schedule的方式隐藏掉等待时间,这不是本文的重点。
另一种是更常见的加速方式,即数据并行。在Pytorch中我们常用的DataParallel就属于这种,即我们把模型copy多分到不同GPU上,然后不同GPU用不同的batch的数据进行训练。
Retiarii的做法则是将二者融合,这一点天然地适合NAS任务,不过Retiarii论文中并没有系统地去评估这一方法。
6. 框架评估
Retiarii设计了一系列实验来评估它的计算性能,用到的指标是throughput (samples/s),即每秒能处理多少个样本数据。
6.1 Shared Data Loading and Preprocessing
前面已经提到过,NAS任务中,不同子模型其实是有着相同的数据读取和预处理操作的。 而为了提高效率,Retiarii使用了common sub-expression elimination (CSE) 优化算法。作为对比,baseline是每个模型就像普通的DNN一样单独训练,不过使用了NVIDIA提供的CUDA Multi-Process Service (MPS)。MPS的作用简单理解就是当我们在一个GPU上执行多个计算任务,MPS能够起到加速作用,具体地用法和原理参考官方技术文章。实验是在4个V100上跑的,CPU的核数是20。
模型根据round-robin(循环制)的方式分发,即假如有6个模型,只有4个GPU,那个前两个GPU上分发了2个模型,后两个GPU只有一个模型。下图给出了实验结果,可以看到随着模型数量的增加,使用的CSE的Retiarii框架的throughput基本呈现线性增长,而baseline无法scale。不过可以看到当模型数量从4扩展到5的时候,throughput没有提升,还反而下降了,文中的解释是第一个GPU由于需要训练2个模型,而且Retiarii将不同模型做了merge操作,所以其他模型必须等待第一个GPU。总之下图的结果表明CSE优化操作的确可以有效提高CPU的计算效率。
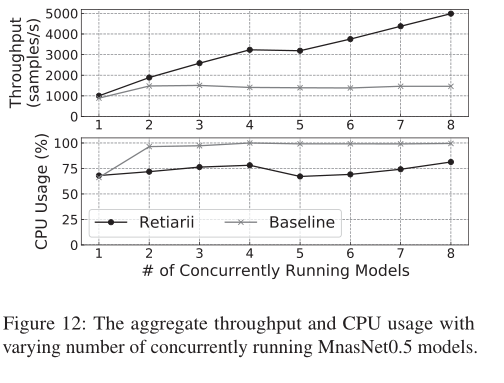
下图展示了TextNAS的测试结果,比较的方式是将BERT Embedding放置到CPU和GPU的throughput。因为Retiarii会牺牲一个GPU用来计算BERT embedding,所以下图中Retiarii的模型数量都是3的倍数。注意Baseline也将BERT embedding放置到了GPU上计算。
不过我们可以看到,即使少了一个GPU,但是Retiarii的计算性能还是远远高于baseline。
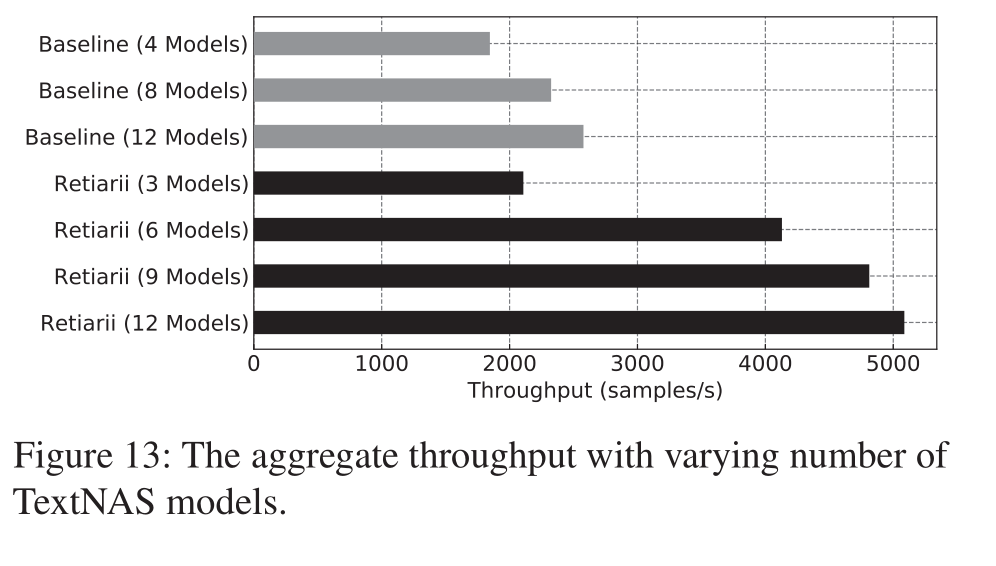
6.2 Operator Batching
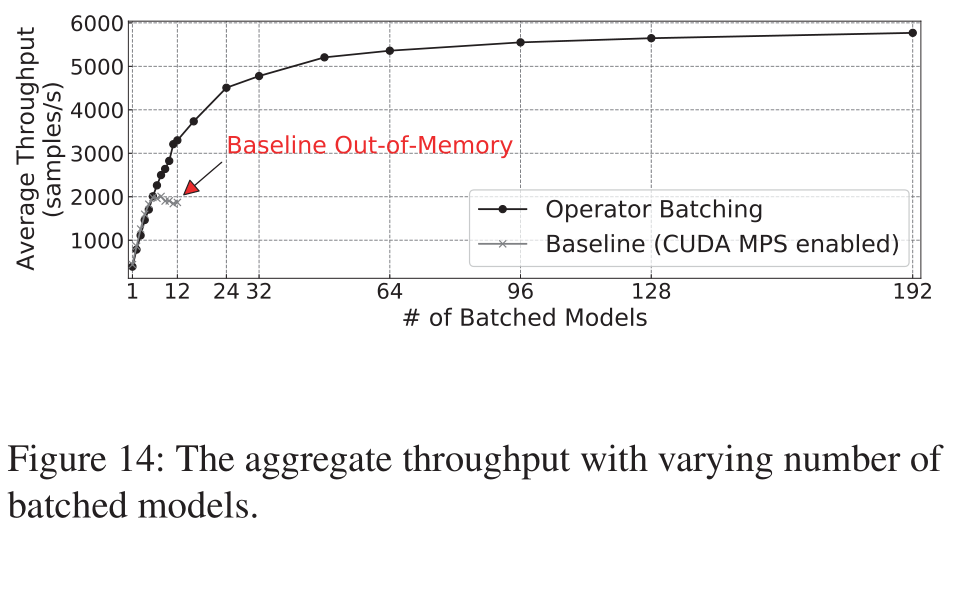
说实话下面这个结果震惊到我了,这个实验采用的是预训练好的MobileNet,设备是单个16GB的V100。
Baseline是开启CUDA MPS后计算多个模型;Retiarii和baseline的差别在于它对这些子模型执行了Operator Batching操作。二者采样模型的顺序是一样的。可以看到Baseline在采样到12个模型后就OOM了,而Retiarii能扩展到192个模型,NB!而且同样扩展到12个模型时,Retiarii的Throughput是baseline的1.76倍。
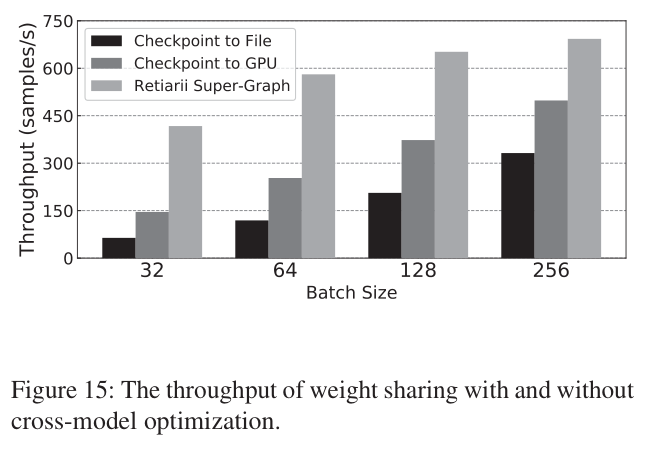
6.3 Optimization for Weight Sharing
这个实验使用的是SPOS算法,模型搜索空间基于ShuffleNetV2 block,每个batch会采样生成一个新的模型实例。两个baseline分别是:
- baseline1:supernet模型的checkpoint存到文件里,即每次从这个文件里load子模型的权重,训练一个batch后,又把权重保存到文件里
- baseline2:Supernet的权重保存到GPU里,以
dict对象的形式储存 - Retiarii的做法则是会收集所有已采样的模型结构,并且会把这些结构merge成一个supernet,注意这和传统的方式不一样,传统的方法是预先手动定义好Supernet的结构,而Retiarii是在搜索过程中不断更新Supernet的结构和权重。
6.4 搜索速度
这个实验设置了两个baseline来比较搜索速度,简单来说就是采样1000个模型花了多少时间。
实验设置如下:
- 选择了Mnasnet,NASNet和AmoebaNet三个NAS算法,因为前面两个都是采样了强化学习的搜索策略,后面两个的搜索空间一直,俗称变量控制法,非常合理。
- baseline 1: 还是像前面的实验一样,每个被采样得到的模型都是像常规的DNN模型一样在不同的GPU上独立训练
- baseline 2: 开启CUDA MPS,如果一个GPU上有多个模型时可以起到加速作用,只不过他们的graph不会merge
- Retiarii:就是在baseline2的基础上把模型的graph merge起来
实验结果如下面两个图所示,第一个使用了NVIDIA的大力出奇迹的DALI数据读取包,第二个是使用Pytorch自带的数据读取包,可以看到Retiarii的加速效果还是非常明显的
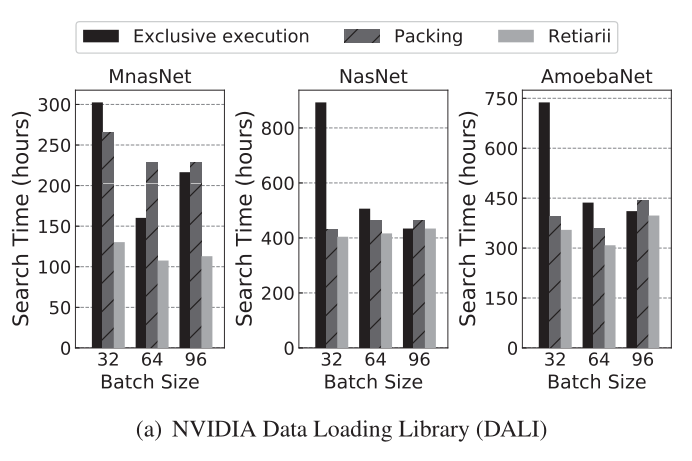
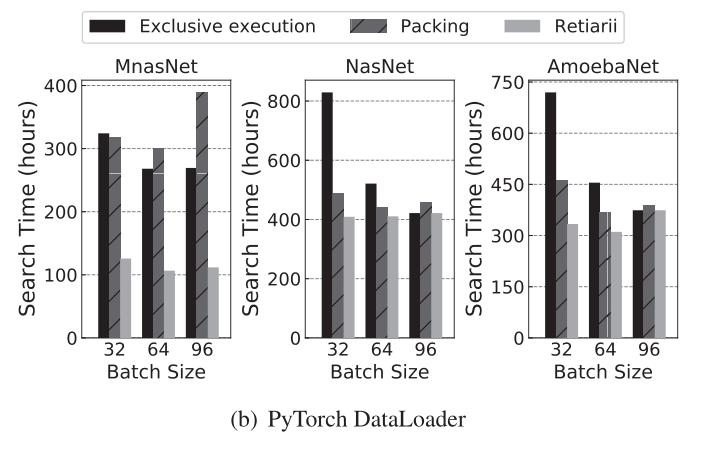
6.5 Scaling Weight-Shared Training
前面介绍过mixed-parallelism策略,这个实验就是为了检测这个策略的有效性。实验设置如下:
- 实验使用SPOS算法基于ShuffleNet搜索,每个batch会搜索一个新的模型。
- 数据集使用的是ImageNet,总共跑了60个epoch,图片数量是1,281,167,batch size是256。所以总共采样训练了1281167/256*60=300240个模型。
- 实验是在两个节点上运行,每个节点4个V100。
- 评估方法是随机采样196个模型,并使用256个验证图像来评估这些模型的性能。196个模型的平均验证准确率视为算法的性能,越高越好。
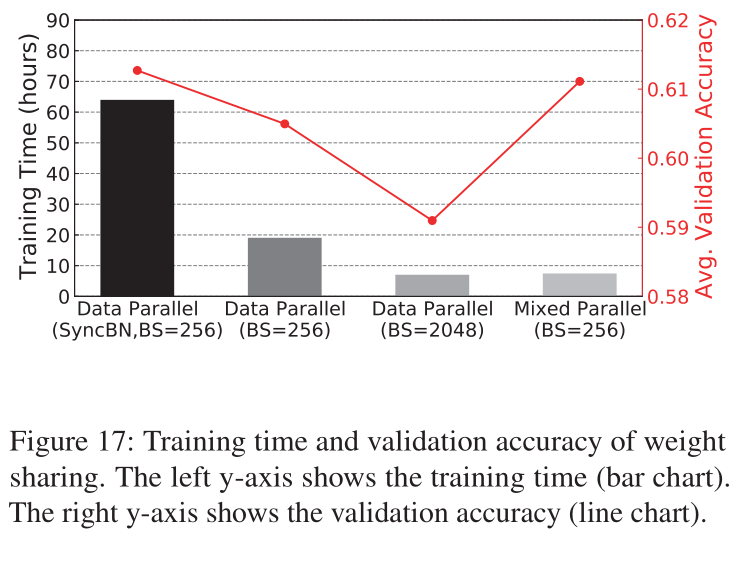
下图给出了不同策略下的性能比较,柱状图表示训练的时间,折线表示对应的平均accuracy。前三个使用的都是基于常见的预先定义好的Supernet训练,最后的Mixed Parallel则是Retiarii框架的方法。
可以看到通过混合并行的策略不仅加快了训练时间,而且也保证了和SyncBN Data Parallel差不多的性能。
虽然Data Parallel增加batch size到2048的时候将时间减少地比Mixed模式还小,但是准确率却大幅下降,这是因为大batch size会损害模型性能。
SyncBN 是指在多个GPU之间同步计算batch normalization的操作,这个可以增加模型质量,只不过以训练时长增加作为代价。