今日进度:
python爬取
| 第一天 | 第二天 | 第三天 | 第四天 | 第五天 | |
| 所花时间(小时) | 4.5 | ||||
| 代码量(行) | 1000 | ||||
| 博客量(篇) | 1 | ||||
| 了解到的知识点 |
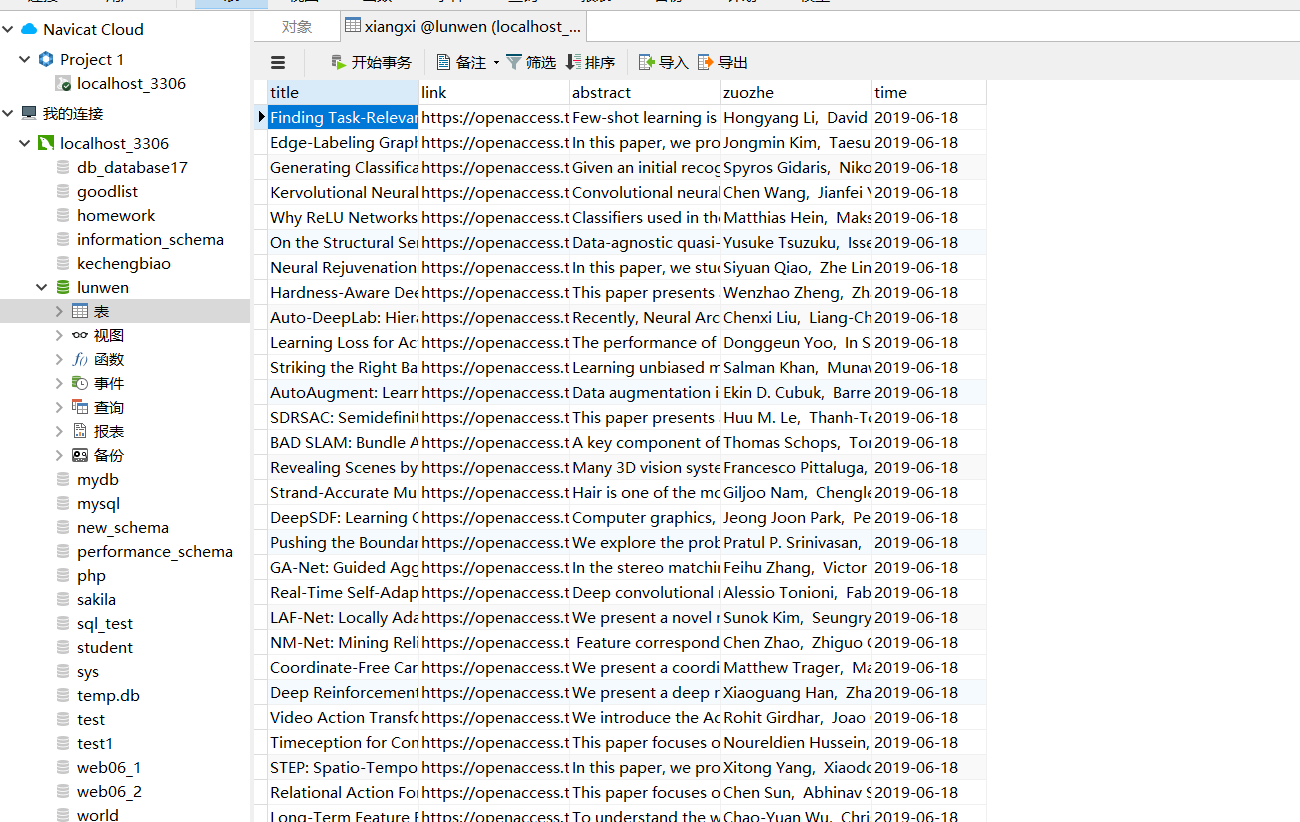
python爬取热词分析 |
import requests import pymysql from lxml import etree # 导入库 from bs4 import BeautifulSoup import re import time db = pymysql.connect(host="localhost", user="root", passwd="root", database="lunwen", charset='utf8') cursor = db.cursor() # 定义爬虫类 class Spider(): def __init__(self): self.url = 'https://openaccess.thecvf.com/CVPR2018?day=2018-06-21' self.headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } r = requests.get(self.url,headers=self.headers) r.encoding = r.apparent_encoding self.html = r.text def lxml_find(self): '''用lxml解析''' tonum =200 start = time.time() # 三种方式速度对比 selector = etree.HTML(self.html) # 转换为lxml解析的对象 titles = selector.xpath('//dt[@class="ptitle"]/a/@href') # 这里返回的是一个列表 for each in titles[200:]: title0 = each.strip() # 去掉字符左右的空格 #print("https://openaccess.thecvf.com/content_CVPR_2019"+title[17:]) chaolianjie="https://openaccess.thecvf.com/content_cvpr_2018"+title0[17:] req=requests.get(chaolianjie,headers=self.headers) req.encoding=req.apparent_encoding onehtml=req.text selector1=etree.HTML(req.text) title=selector1.xpath('//div[@id="papertitle"]/text()') #print(title[0][1:]) abst=selector1.xpath('//div[@id="abstract"]/text()') hre0=selector1.xpath('//a/@href') hre="https://openaccess.thecvf.com"+hre0[5][5:] #print(hre) zuozhe=selector1.xpath('//dd/div[@id="authors"]/b/i/text()') va = [] va.append(title) va.append(hre) va.append(abst) va.append(zuozhe) va.append("2018-06-21") sql = "insert into xiangxi (title,link,abstract,zuozhe,time) values (%s,%s,%s,%s,%s)" cursor.execute(sql, va) db.commit() print("已爬取" + str(tonum) + "条数据") tonum=tonum+1 end = time.time() print('共耗时:',end-start) if __name__ == '__main__': spider = Spider() spider.lxml_find() cursor.close() db.close()
爬取到mysql数据库中: