Dubbo集群模块的目的是将集群Invokers构造一个透明的Invoker对象,其中包含了容错机制、负载均衡、目录服务(服务地址集合)、路由机制等,为RPC层提供高可用、高并发、自动发现、可治理的SOA特性。
本文我们主要讨论以下八个问题:
一、集群模块的需求功能点有哪些?
二、集群模块的总体设计框架是什么样的?
三、Dubbo提供了哪些容错机制?如何实现的?
四、Dubbo提供了哪些负载均衡机制?如何实现的?
五、Dubbo目录服务是干什么的?提供了哪几种类型的目录服务?
六、Dubbo提供了哪些路由机制?如何实现的?
七、总结集群模块如何带来高可用、自动发现、可治理的特性?
一、集群模块的需求功能点有哪些?
基于文章开头讨论的目标内容,我认为集群模块的需求功能点主要有以下几点:
1、将集群Invokers构造一个透明的Invoker对象提供给Rpc模块调用;
2、提供容错机制,包括Failover(失败自动切换,尝试其他服务器)、Failfast(失败立即返回并抛出异常)、Failsafe(失败忽略异常)、Failback(失败自动恢复,记录日志并定时重试)、Forking(并行调用多个服务,一个成功立即返回)、Broadcast(广播调用所有提供者,任意一个报错则报错);
3、提供负载均衡机制,包括Random(带权重的随机访问)、RoundRobin(带权重的轮训访问)、LeastActive(选择最少活跃者)、ConsistentHash(一致性哈希,相同参数的请求总是发到同一提供者);
4、提供目录服务,包括静态目录服务(将调用地址存到本地)、注册中心注册目录服务两种方式;
5、提供路由机制,包括条件路由(在URL配置条件表达式)和脚本路由(使用脚本语言编写脚本,返回路由结果);
二、集群模块的总体设计框架是什么样的?
调用关系如下图所示:
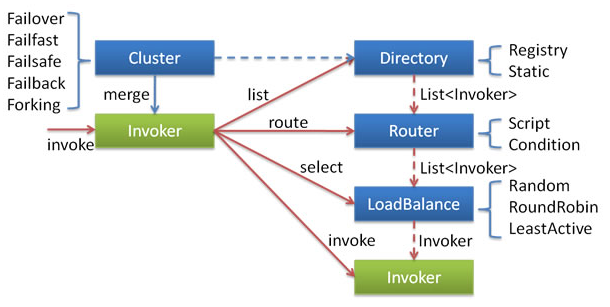
接口声明如下图所示:

Cluster接口:声明join()方法,从Directory实例中的Invoker列表中返回一个Invoker;
Directory接口:list()方法,可查询Invoker列表;
LoadBalance接口:select()方法,可从一个Invoker集合中结合负载均衡策略选择一个Invoker返回;
Router接口:route()方法,从给定的Invoker集合路由选择一个Invoker返回;
Merger接口:merge(T)方法,将多个调用返回的结果合并起来返回;
Configurator接口:configure(URL)方法,配置加工URL参数并返回;
三、Dubbo提供了哪些集群容错机制?如何实现的?
由于篇幅过程,我将其内容单独写了一篇博客,详见 《集群容错机制》。
四、Dubbo提供了哪些负载均衡机制?如何实现的?
由于篇幅过长,我又将内容拆分到另一片博客,见《集群负载均衡》。
五、Dubbo目录服务是干什么的?提供了哪几种类型的目录服务?
dubbo目录服务提供了获取提供者服务地址列表的功能,目录服务的调用者是com.alibaba.dubbo.rpc.cluster.Cluster的join()方法。目前dubbo提供了静态目录服务和注册中心目录服务。静态目录服务实现了一个静态的地址列表本地内存缓存。注册中心目录服务提供了分布式注册检索服务地址的功能。在提供目录服务返回服务地址的时候,调用dubbo的路由服务,实现了请求服务的路由功能。接下来,我们来讨论目录服务的实现细节。
1、Directory接口

Directory接口中,
Class<T> getInterface()方法返回服务的接口类;
list(Invocation invocation)就是获取服务地址列表的方法;
父接口Node中,
getUrl()方法返回了服务声明的URL信息,
isAvailable()方法判断目录服务是否可用,或者是否存在可用的服务提供者;
destroy()销毁目录服务及所有提供者服务。
2、AbstractDirectory,目录服务的默认实现抽象类;
(1)将路由对象引入目录服务,方法setRouters()设置了路由对象,实现见如下代码:
1 protected void setRouters(List<Router> routers) { 2 // copy list 3 routers = routers == null ? new ArrayList<Router>() : new ArrayList<Router>(routers); 4 // append url router 5 String routerkey = url.getParameter(Constants.ROUTER_KEY); 6 if (routerkey != null && routerkey.length() > 0) {
//通过SPI实例化配置的路由对象工厂对象 7 RouterFactory routerFactory = ExtensionLoader.getExtensionLoader(RouterFactory.class).getExtension(routerkey); 8 routers.add(routerFactory.getRouter(url)); 9 } 10 // append mock invoker selector 11 routers.add(new MockInvokersSelector()); 12 Collections.sort(routers); 13 this.routers = routers; 14 }
(2)得到服务对象列表,主要通过doList()实现得到服务列表,此方法由子类实现,然后依次调用router列表做路由筛选,实现如下:
1 public List<Invoker<T>> list(Invocation invocation) throws RpcException { 2 if (destroyed) { 3 throw new RpcException("Directory already destroyed .url: " + getUrl()); 4 } 5 List<Invoker<T>> invokers = doList(invocation); 6 List<Router> localRouters = this.routers; // local reference 7 if (localRouters != null && localRouters.size() > 0) { 8 for (Router router : localRouters) { 9 try { 10 if (router.getUrl() == null || router.getUrl().getParameter(Constants.RUNTIME_KEY, false)) { 11 invokers = router.route(invokers, getConsumerUrl(), invocation); 12 } 13 } catch (Throwable t) { 14 logger.error("Failed to execute router: " + getUrl() + ", cause: " + t.getMessage(), t); 15 } 16 } 17 } 18 return invokers; 19 }
3、StaticDirectory静态目录服务,doList()将构造方法中传入的invoker列表原样返回。
4、RegistryDirectory 类整合了注册中心和目录服务,具体实现实在dubbo-register模块,我将另外写一篇博客讨论。
六、Dubbo提供了哪些路由机制?如何实现的?
路由机制为用户提供了灵活可配置的服务筛选功能,通过用户自定义配置路由规则,决定一次 dubbo 服务调用的目标服务器。使用场景例如:提供差异化服务,给重要的请求提供性能好的服务器,反之给次要的服务提供性能差的服务器;读写分离,根据方法名字add,update,delete等分为一组,查询方法分为一组,分别映射到不同的服务器上;对客户端设置白名单、黑名单;更多场景及具体的应用说明详见dubbo用户手册路由规则篇。
dubbo提供了两种路由机制:条件路由和脚本路由。
1、向注册中心写入路由规则,通常由监控中心或服务治理页面完成,代码实现主要在dubb-register模块:
1 RegistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension(); 2 Registry registry = registryFactory.getRegistry(URL.valueOf("zookeeper://10.20.153.10:2181")); 3 registry.register(URL.valueOf("condition://0.0.0.0/com.foo.BarService?category=routers&dynamic=false&rule=" + URL.encode("host = 10.20.153.10 => host = 10.20.153.11") + "));
其中:
condition://表示路由规则的类型,支持条件路由规则和脚本路由规则,可扩展,必填。0.0.0.0表示对所有 IP 地址生效,如果只想对某个 IP 的生效,请填入具体 IP,必填。com.foo.BarService表示只对指定服务生效,必填。category=routers表示该数据为动态配置类型,必填。dynamic=false表示该数据为持久数据,当注册方退出时,数据依然保存在注册中心,必填。enabled=true覆盖规则是否生效,可不填,缺省生效。force=false当路由结果为空时,是否强制执行,如果不强制执行,路由结果为空的路由规则将自动失效,可不填,缺省为flase。runtime=false是否在每次调用时执行路由规则,否则只在提供者地址列表变更时预先执行并缓存结果,调用时直接从缓存中获取路由结果。如果用了参数路由,必须设为true,需要注意设置会影响调用的性能,可不填,缺省为flase。priority=1路由规则的优先级,用于排序,优先级越大越靠前执行,可不填,缺省为0。rule=URL.encode("host = 10.20.153.10 => host = 10.20.153.11")表示路由规则的内容,必填。
2、条件路由
基于条件表达式的路由规则,如:host = 10.20.153.10 => host = 10.20.153.11。=>左边的表达式表示消费端信息(matchWhen),右边的表达式表示服务提供者的服务信息(matchThen)。
代码实现中,解析=>左右的条件表达式,左侧消费端条件表达式解析成when,右侧服务端条件表达式解析成then,封装matchWhen()和matchThen()分别匹配消费端和服务端表达式。
我们看看源码如何实现路由逻辑的。
条件路由实现主要靠两个类,ConditionRouterFactory,实现了ConditionRouter实例化的过程;ConditionRouter,实现了具体的路由机制,其中route方法实现如下,实现主要靠解析和匹配条件表达式。
1 public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) 2 throws RpcException { 3 if (invokers == null || invokers.size() == 0) { 4 return invokers; 5 } 6 try {
//消费端条件不匹配规则,就全部返回 7 if (!matchWhen(url, invocation)) { 8 return invokers; 9 } 10 List<Invoker<T>> result = new ArrayList<Invoker<T>>(); 11 if (thenCondition == null) { 12 logger.warn("The current consumer in the service blacklist. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey()); 13 return result; 14 } 15 for (Invoker<T> invoker : invokers) {
//遍历invokers,找到匹配规则的invoker(服务端)加入result 16 if (matchThen(invoker.getUrl(), url)) { 17 result.add(invoker); 18 } 19 } 20 if (result.size() > 0) { 21 return result; 22 } else if (force) { //如果结果为空,force=true,则返回空的列表,否则返回所有的invokers(不执行route规则) 23 logger.warn("The route result is empty and force execute. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey() + ", router: " + url.getParameterAndDecoded(Constants.RULE_KEY)); 24 return result; 25 } 26 } catch (Throwable t) { 27 logger.error("Failed to execute condition router rule: " + getUrl() + ", invokers: " + invokers + ", cause: " + t.getMessage(), t); 28 } 29 return invokers; 30 }
3、脚本路由
通过配置脚本或脚本文件设置路由规则rule,程序编译执行脚本函数,得到脚本筛选后的invokers数组。具体逻辑很简单,就是加载脚本,加载对应脚本引擎,执行脚本,得到结果后转换输出的过程。
1 public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException { 2 try { 3 List<Invoker<T>> invokersCopy = new ArrayList<Invoker<T>>(invokers); 4 Compilable compilable = (Compilable) engine; 5 Bindings bindings = engine.createBindings(); 6 bindings.put("invokers", invokersCopy); 7 bindings.put("invocation", invocation); 8 bindings.put("context", RpcContext.getContext()); 9 CompiledScript function = compilable.compile(rule); 10 Object obj = function.eval(bindings); 11 if (obj instanceof Invoker[]) { 12 invokersCopy = Arrays.asList((Invoker<T>[]) obj); 13 } else if (obj instanceof Object[]) { 14 invokersCopy = new ArrayList<Invoker<T>>(); 15 for (Object inv : (Object[]) obj) { 16 invokersCopy.add((Invoker<T>) inv); 17 } 18 } else { 19 invokersCopy = (List<Invoker<T>>) obj; 20 } 21 return invokersCopy; 22 } catch (ScriptException e) { 23 //fail then ignore rule .invokers. 24 logger.error("route error , rule has been ignored. rule: " + rule + ", method:" + invocation.getMethodName() + ", url: " + RpcContext.getContext().getUrl(), e); 25 return invokers; 26 } 27 }
七、总结集群模块如何带来高可用、自动发现、可治理的特性?
集群模块在dubbo中非常重要,提供了基于RPC功能的高可用特性,此特性主要是通过集群容错和负载均衡策略支持的,在服务提供者出现异常时,可配置的容错特性确保服务能按照配置的策略返回,或切换到其他服务并重试,或立即抛出异常,满足了不同服务不同场景的异常后处理需要。可配置的负载均衡策略满足了不同场景、需求的服务实现负载均衡,在不同场景下均匀的分摊负载,在负载不够用的情况下灵活的增加机器节点承担多余的负载,保证了集群的高可用特性。并且可以灵活配置节点的权重,实现针对不同配置的服务节点承担的请求不同。
可配置的路由功能满足了很多场景下的灵活路由需求,如读写分离,消费端请求的白名单、黑名单,针对不同配置的服务提供给不同的消费者等等。由于可配置性强,可以针对不同的需求做不同的配置,可提供很灵活的功能特性。通过配置规则,实现服务降级,可以屏蔽有问题的服务,并定义服务响应。这些都体现了Dubbo可治理的特性。
目录服务简单的定义了对服务地址列表的查询功能,配合dubb-register注册中心模块功能可以实现服务注册、自动发现功能。详见注册中心模块的源码分析章节。
集群模块就讨论到这里了,如有不当之处,欢迎大家提出异议和宝贵的意见,这样有助于我技术上的提升。