Apache Kudu的基本思想、架构和与Impala实践
Apache Kudu是一个为了Hadoop系统环境而打造的列存储管理器,与一般的Hadoop生态环境中的其他应用一样,具有能在通用硬件上运行、水平扩展性佳和支持高可用性操作等功能。
在Kudu出现之前,Hadoop生态环境中的储存主要依赖HDFS和HBase,追求高吞吐批处理的用例中使用HDFS,追求低延时随机读取用例下用HBase,而Kudu正好能兼顾这两者。
Kudu的主要优点:
- 快速处理OLAP(Online Analytical Processing)任务
- 集成MapReduce、Spark和其他Hadoop环境组件
- 与Impala高度集成,使得这成为一种高效访问交互HDFS的方法
- 强大而灵活的统一性模型
- 在执行同时连续随机访问时表现优异
- 通过Cloudera Manager可以轻松管理控制
- 高可用性,tablet server和master利用Raft Consensus算法保证节点的可用
- 结构数据模型
常见的应用场景:
- 刚刚到达的数据就马上要被终端用户使用访问到
- 同时支持在大量历史数据中做访问查询和某些特定实体中需要非常快响应的颗粒查询
- 基于历史数据使用预测模型来做实时的决定和刷新
- 要求几乎实时的流输入处理
基本概念
列数据存储 Columnar Data Store
Kudu是一种列数据储存结构,以强类型的列(strong-type column)储存数据。
高效读取
可选择单个列或者某个列的一部分来访问,可以在满足本身查询需要的状态下,选择最少的磁盘或者存储块来访问,相对于基于行的存储,更节省访问资源,更高效。
数据比较
由于给定的某一个列当中都是同样类型的数据,所以对于同一个量级的数据比较时,这种存储方式比混合类型存储的更具优势。
表Table
同理,一种数据设计模式schema,根据primary key来排序组织。一个表可以被分到若干个分片中,称为tablet。
分片Tablet
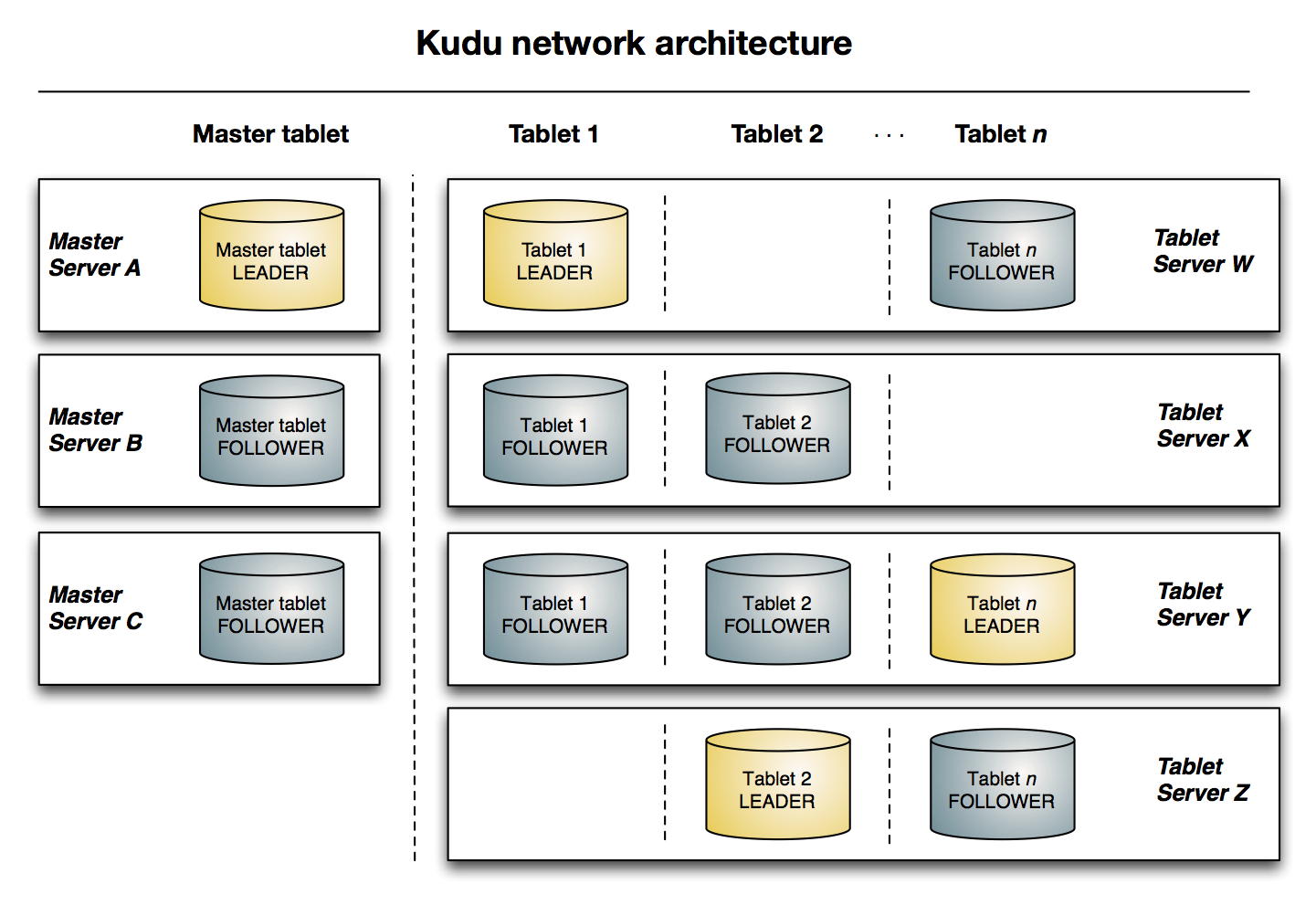
一个tablet是指表上一段连续的segment。一个特定的tablet会被复制到多个tablet服务器上,其中一个会被认为是leader tablet。每一个备份tablet都可以支持读取、写入请求。
分片服务器 Tablet Server
负责为客户端储存和提供tablets。只有Leader Tablet可以写入请求,其他的tablets只能执行请求。
Master
Master负责追踪tablets、tablet severs、catalog table和其他与集群相关的metadata。另外也为客户端协调metadata的操作。
Raft Consensus算法
前文介绍过了
Catalog Table
Kudu的metadata的中心位置,存储表和tablet的信息,客户端可以通过master用客户端api来访问。
逻辑复制 Logical Replication
Kudu并是不是在硬盘数据上做复制的,而是采取了逻辑复制的办法,这有以下一些好处:
- 尽管insert和update需要通过网络对数据做transmit,但是delete操作不需要移动任何数据。Delete操作的请求会发送到每一个tablet server上,在本地做删除操作。
- 普通的物理操作,比如数据压缩,并不需要通过网络做数据transmit,但不同于HDFS,每个请求都需要通过网络把请求传送到各个备份节点上来满足操作需要。
- 每个备份不需要同时进行操作,降低写入压力,避免高延时。
随机写入效率
在内存中每个tablet分区维护一个MemRowSet来管理最新更新的数据,当尺寸大于一定大小之后会flush到磁盘上行成DiskRowSet,多个DiskRowSet会在适当的时候做归并操作。 这些被flush到磁盘的DiskRowSet数据分为两种,一种是Base数据,按列式存储格式存在,一旦生成不再修改,另一种是Delta文件,储存Base中有更新的数据,一个Base文件可以对应多个Delta文件。

Delta文件的存在使得检索过程需要额外的开销,这些Delta文件是根据被更新的行在Base文件中的位移来检索的,而且做合并时也是有选择的进行。
此外DRS(Distributed Resource Scheduler)自身也会合并,为了保障检索延迟的可预测性。Kudu的DRS默认以32MB为单位进行拆分,Compaction过程是为了对内容进行排序重组,减少不同DRS之间key的overlap,进而在检索的时候减少需要参与检索的DRS的数量。

Kudu整体框架
与Impala的简单实践
安装部分不写了,自己都装出屎了。
通过Impala使用Kudu可以新建内部表和外部表两种。
- 内部表(Internal Table):事实上是属于Impala管理的表,当删除时会确确实实地删除表结构和数据。在Impala中建表时,默认建的是内部表。
- 外部表(External Table):不由Impala管理,当删除这个表时,并不能从源位置将其删除,只是接触了Kudu到Impala之间对于这个表的关联关系
创建一个简单的Kudu表:
CREATE TABLE kaka_first
(
id BIGINT,
name STRING
)
DISTRIBUTE BY HASH INTO 16 BUCKETS
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'kaka_first',
'kudu.master_addresses' = '10.10.245.129:7051',
'kudu.key_columns' = 'id'
);
建表语句中,默认第一个就是Primary Key,是个not null列,在后面的kudu.key_columns中列出,这边至少写一个。
- storage_handler:选择通过Impala访问kudu的机制,必须填成
com.cloudera.kudu.hive.KuduStorageHandler - kudu.table_name:Impala为Kudu建(或者关联的)的表名
- kudu.master_addresses:Impala需要访问的Kudu master列表
- kudu.key_columns:Primary key列表
插入数据
INSERT INTO kaka_first VALUES (1, "john"), (2, "jane"), (3, "jim");
Impala默认一次同时最多插入1024条记录,作为一个batch
更新数据
UPDATE kaka_first SET name="bob" where id = 3;
删除数据
DELETE FROM kaka_first WHERE id < 3;
修改表属性
ALTER TABLE kaka_first RENAME TO employee;
//重命名
ALTER TABLE employee
SET TBLPROPERTIES('kudu.master_addresses' = '10.10.245.135:7051');
//更改kudu master address
ALTER TABLE employee SET TBLPROPERTIES('EXTERNAL' = 'TRUE');
//将内部表变为外部表
一个应用
从MySql导出数据到本地txt
select * from DAYCACHETBL into outfile '/tmp/DAYCACHETBL.txt'
fields terminated by ' '
lines terminated by '
';
保存到hdfs中/data目录下
hdfs dfs -mkdir /data
hdfs dfs -put /tmp/DAYCACHETBL.txt /data
在hive shell中创建hive表
create table DAYCACHETBL (
METERID string,
SOURCEID int,
VB double,
DELTA double,
DTIME string,
UPGUID string,
UPBATCH string,
level string,
YEAR string,
MONTH string,
QUARTER string,
WEEK string,
D_DELTA double
)
ROW FORMAT DELIMITED
fields terminated by ' '
lines terminated by '
'
stored as textfile
location '/data';
在impala-shell下创建kudu表
create table DAYCACHETBL2 (
METERID string,
SOURCEID int,
VB double,
DELTA double,
DTIME string,
UPGUID string,
UPBATCH string,
level string,
YEAR string,
MONTH string,
QUARTER string,
WEEK string,
D_DELTA double
)
DISTRIBUTE BY HASH INTO 16 BUCKETS
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'DAYCACHETBL2',
'kudu.master_addresses' = 'kudu1:7051,kudu2:7051,kudu3:7051',
'kudu.key_columns' = 'METERID'
);
将hive表中的内容插入kudu表
insert into DAYCACHETBL2 select * from DAYCACHETBL;