一:Python中的正则表达式。
1.字符集合
[abc]指定包含字符、[a-zA-Z]来指定所有的英文字母的大小写
pattern = re.complie(r,'[a-zA-Z]');
re.findall(pattern,input)
2.正则表达式需要去记一些符号。可以去网上查找现成的,再去进行修改。
3.match和search,match从开头开始匹配,如果开头失败,就算失败了。
search会跳过开头,继续查找合适的。
4.字符串的替换和修改
sub(rule,replace,target[,count])
subn(rule,replace,target[,count])
第一个参数是正则规则,第二个参数是指定的用来替换的字符串,第三个参数是目标字符串,第四个参数是最多替换次数。
5.split切片函数,使用指定的正则规则在目标字符串中查找匹配的字符串。
未完待续,可以等有时间在实际操作一下这些函数。
二:Python中的NLTK工具包
1.安装,pip install NLTK 之后,很多包其实并未下载,需要在敲入命令行进行相应包的下载。
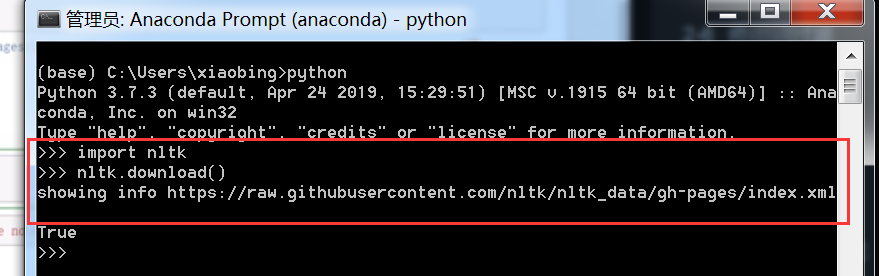
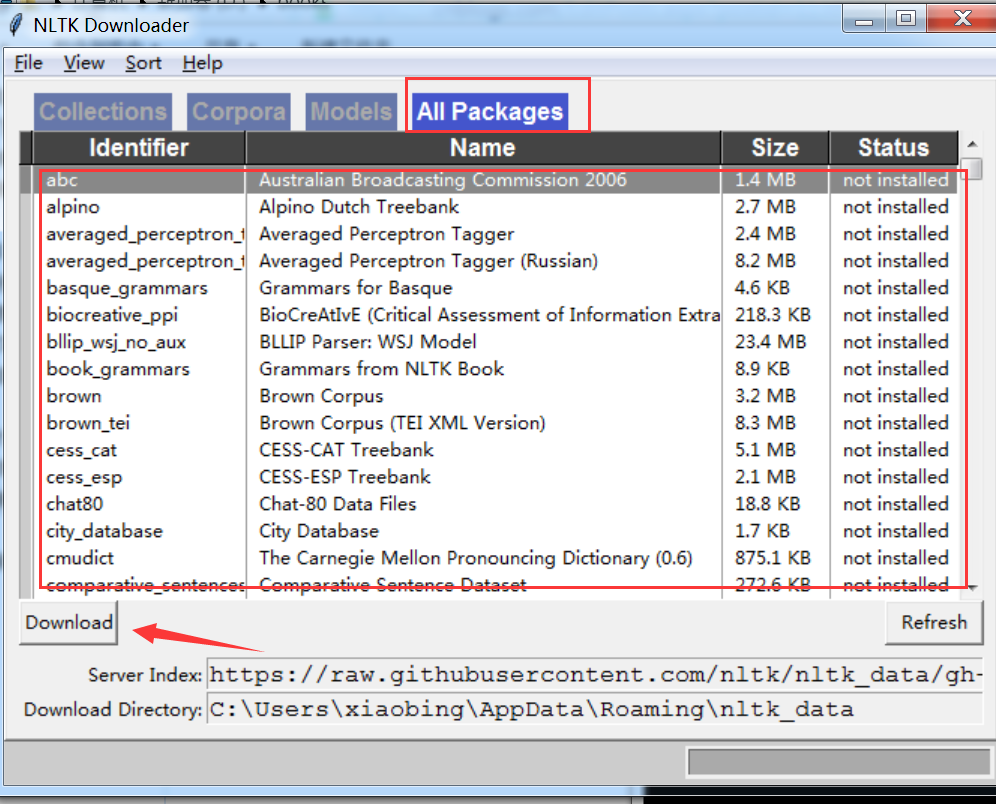
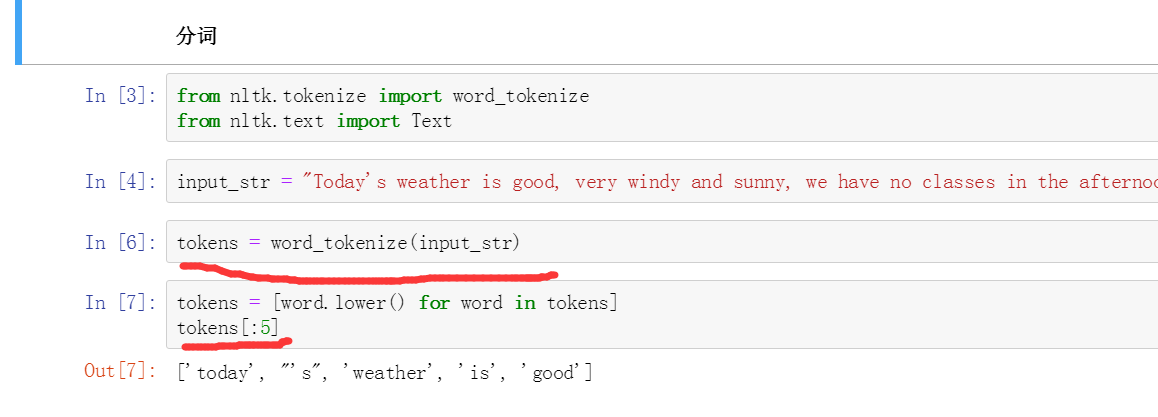
插入NLTK是为了做分词,但是总是没法成功。
熟悉下常用的几个操作就行。
以及创建一个text对象。
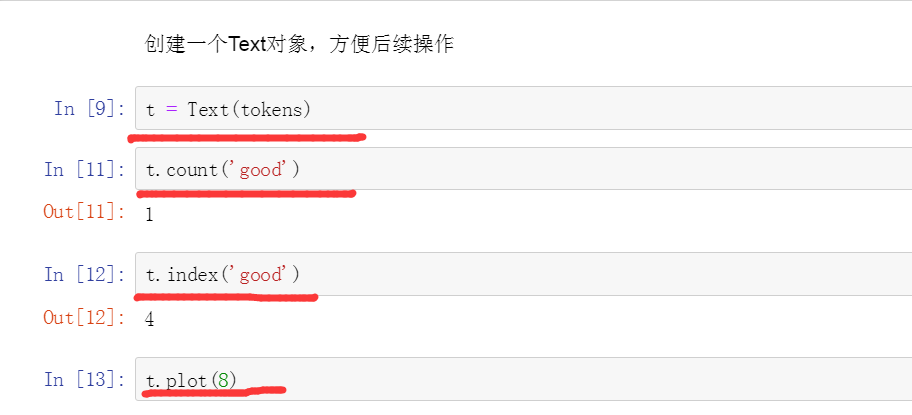
三、停用词过滤。
1.from nltk.corpus import stopwords
stopwords.readme().replace(' ',' ')
stopwords.fileids()
两个list取交集函数。test_words_set.intersection(set(stopwords.words('english')))
过滤停用词:
filtered = []