一. Django路由层
路由层即对应项目文件下的urls.py文件。实际上每个APP中也可以有自己的urls.py路由层、templates文件夹及static文件夹。Django支持这么做,也为实际工作中一个项目多人协作完成提供了便利:即每个人单独建一个Django项目写一个APP,最后新建一个Django项目将所有APP汇总,然后settings中注册各个APP,再修改一下其他配置即可。
路由层大致内容如下:
from django.conf.urls import url from django.contrib import admin from app01 import views # 导入应用app01中的视图层 urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^$',views.home), url(r'^test/$',views.test), url(r'^testadd/$',views.testadd), url(r'',views.error) ]
url第一个参数是正则表达式,第二个参数是视图函数的函数名。当浏览器中输入URL回车时,会按从上往下往下的顺序依次去匹配URL,如果匹配上了,则自动调用执行相应的视图函数(函数名加括号,并且会默认传一个参数,我们视图函数中用名为request的形参接收)。如果所有正则都匹配不上该URL,则报错。我们通常会设置两个固定的路由:
1. 网站首页路由(固定写法)
url(r'^$',views.home)
2. 网站不存在路由(注意:该路由需放在所有路由中的最下面,因为正则空‘’能匹配所有字符串)
url(r'',views.error)
1. 无名分组
正则中有分组的语法,当我们给正则表达式加上分组时,他只会返回匹配结果中分组的内容,而且还能给分组取名。无名分组就是没有取名的分组,有名分组反之。
1.1 现在假设有一个路由及相应视图函数如下(加了分组,即用()包着的d+):
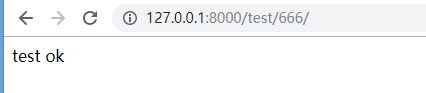
url(r'^test/d+/',views.test), # d+匹配一个或多个数字 def test(request): return HttpResponse('test ok')
在浏览器访问URL:http://127.0.0.1:8000/test/666/ 的结果如下,一切正常
1.2 接下来给路由中的正则表达式加上分组(未取名,称为无名分组)
url(r'^test/(d+)/',views.test), # d+匹配一个或多个数字,用()将d+作为一个分组 def test(request): return HttpResponse('test ok')
再次浏览器访问URL:http://127.0.0.1:8000/test/666/ 的结果如下:
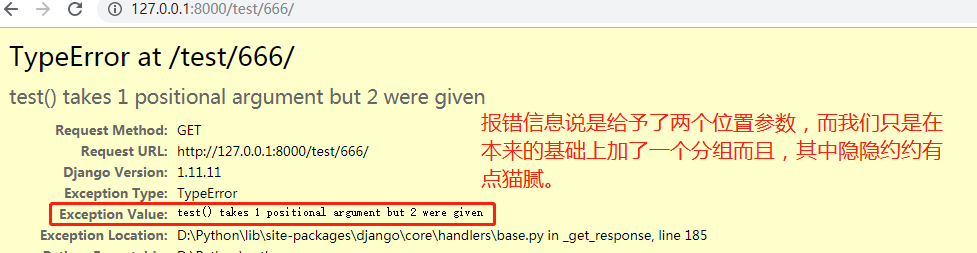
既然说给了两个位置实参,那么我们就用两个形参接收打印看看给了啥,修改代码:
url(r'^test/(d+)/',views.test), # d+匹配一个或多个数字,用()将d+作为一个分组 def test(request, temp): print(temp) return HttpResponse('test ok')
输入同样的URL发现没有问题,然后服务端结果如下:
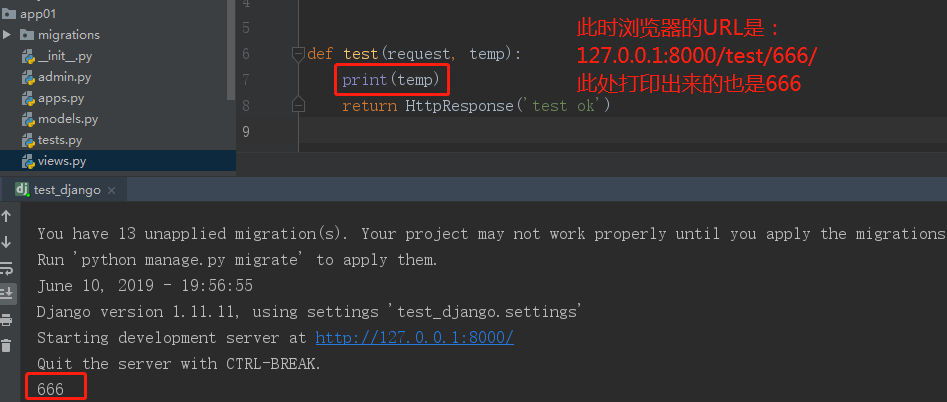
在多次修改URL后,得出了一个结论:我们将d+作为一个分组,视图函数中也会接收到一个实参,该实参就是分组中的内容。这就意味着我们将url的正则表达式进行分组时,当路由匹配成功而自动调用视图函数时会把分组中的内容也传过去,所以分组时视图函数要定义额外的形参接收。
2. 有名分组
经过无名分组的推导,后面发现有名分组跟无名分组的区别只有一点,那就是无名分组传给视图函数的是位置实参,而有名分组传过去的是关键字实参(所以视图函数也要定义一个同分组名字一样的形参)。
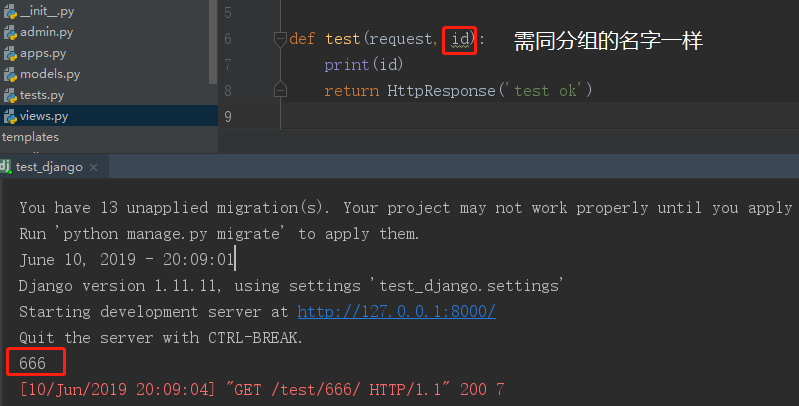
2.1 url正则表达式分组名为id
url(r'^test/(?P<id>d+)/',views.test), # d+匹配一个或多个数字,用()将d+作为一个分组 def test(request, temp): print(temp) return HttpResponse('test ok')
浏览器访问URL:http://127.0.0.1:8000/test/666/ 的结果如下:
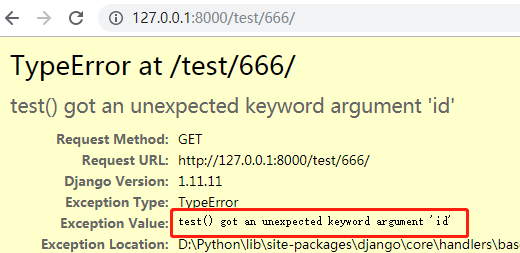
2.2 报错信息提到了关键字参数,那么我们修改视图函数的形参:
url(r'^test/(?P<id>d+)/',views.test), # d+匹配一个或多个数字,用()将d+作为一个分组 def test(request, id): print(id) return HttpResponse('test ok')
输入同样的URL,运行正常,最终结果如下:
结论:
- 无名分组和有名分组不能结果使用,即一个url的正则中不能同时出现有名分组和无名分组。
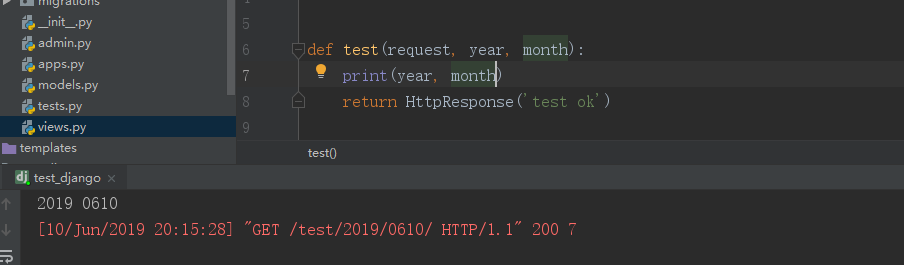
- 一个url中可以使用多个同一类型的分组(均是有名或者无名分组)。例子如下:
url(r'^test/(?P<year>d+)/(?P<month>d+)/',views.test) def test(request,year, month): print(year, month) return HttpResponse('test')
运行结果如下(这里以有名分组为例):
3. 反向解析(根据名字动态获取到对应路径)
如果我们写了超多个视图函数和HTML页面,他们都引用了同一个路由,如果这个时候路由的名字突然改了,我们就要一个个的修改视图函数和HTML页面中的对应的路由名字了。。。
别怕,Django中提供了反向解析,帮我们实现无论你路由名字怎么改,我们都不需要修改其他的东西!!!
反向解析的方法是给一个路由与视图函数的对应关系取别名,然后视图函数与HTML都使用该别名来得到对应的路由,由此实现动态获取路由。
注意事项:
- 可以给每一个路由与视图函数对应关系起一个名字
- 这个名字可以唯一标识出对应的路径
- 这个名字不能重复!!!
3.1 使用反向解析的必备步骤
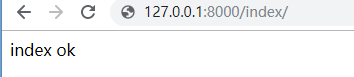
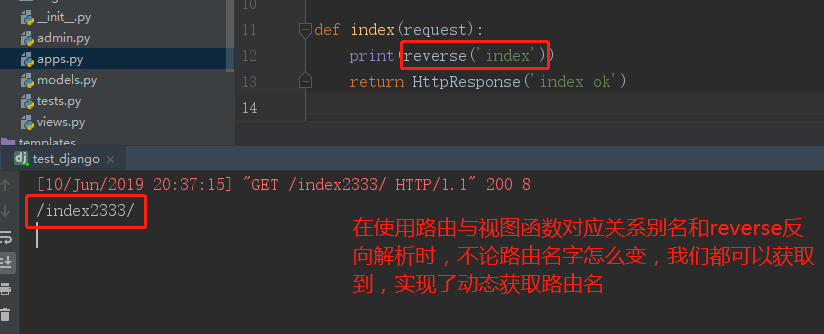
from django.shortcuts import reverse # 除了三剑客之外,再导入reverse # url中用name属性给路由与视图函数对应关系取别名 url(r'index/', views.index, name='index') # 视图函数中用reverse('别名')反向解析url路由 def index(request): print(reverse('index')) return HttpResponse('index ok')
试验一:浏览器输入URL:http://127.0.0.1:8000/index/ 结果如下:
实验二:修改url路由名字,视图函数不变
3.2 接下来我们修改一下url,让url本身就是不固定的(运用正则)
url(r'index/d+/', views.index, name='index') def index(request): print(reverse('index')) return HttpResponse('index ok')
浏览器输入URL:http://127.0.0.1:8000/index/233/结果如下:
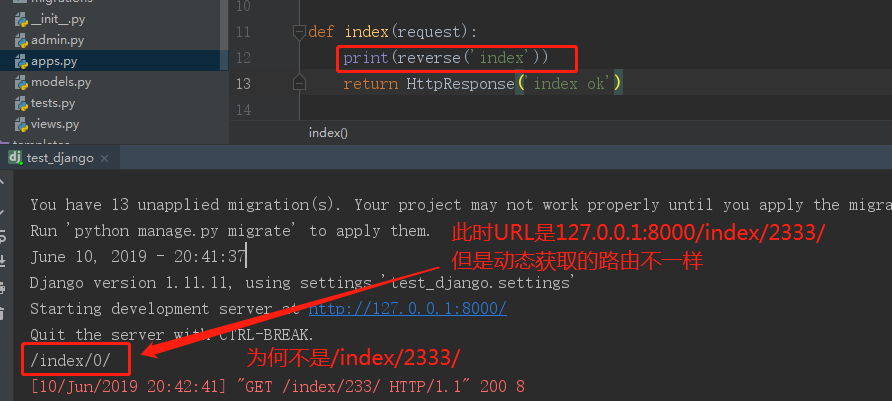
原来这个因为我们url正则中用的d+,反向解析时根本不知道d+是啥,不知道该用什么替换。为了能够反向解析的路由一致,我们必须在反向解析时告诉reverse d+是什么。
修改路由(加上分组)及视图函数:
url(r'index/(d+)/', views.index, name='index') def index(request, id): # reverse可以用args接收参数,但是要是元组,注意,单个元素的元组必须加个逗号!!! print(reverse('index', args=(id, ))) return HttpResponse('index ok')
接下来输入同样的URL再看结果:
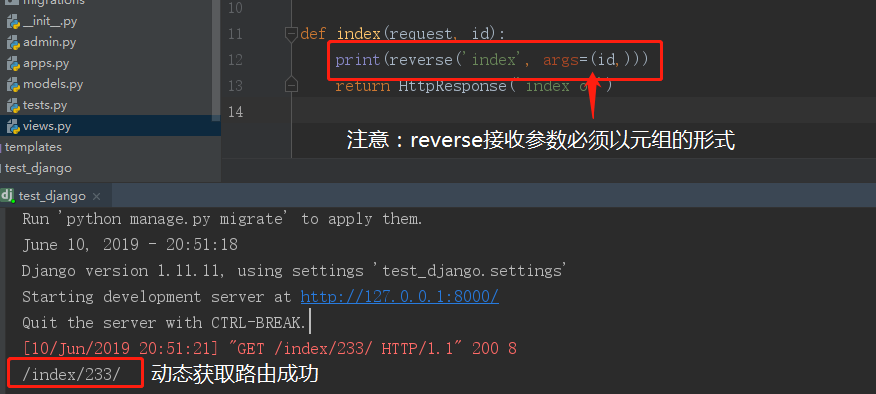
上述是运用分组来把d+的内容通过参数的形式传给视图函数,然后通过reverse的args传参把d+的内容告诉reverse。
3.3 无名分组使用反向解析
# 路由 url(r'index/(d+)/', views.index, name='index') # 视图函数 def index(request, id): if request.method == 'POST': return HttpResponse('index ok') return render(request, 'index.html', locals()) #HTML代码(body标签内) <form action="{% url 'index' id %}" method="post"> <h1>come on</h1> <input type="submit"> </form>
对应结论如下:
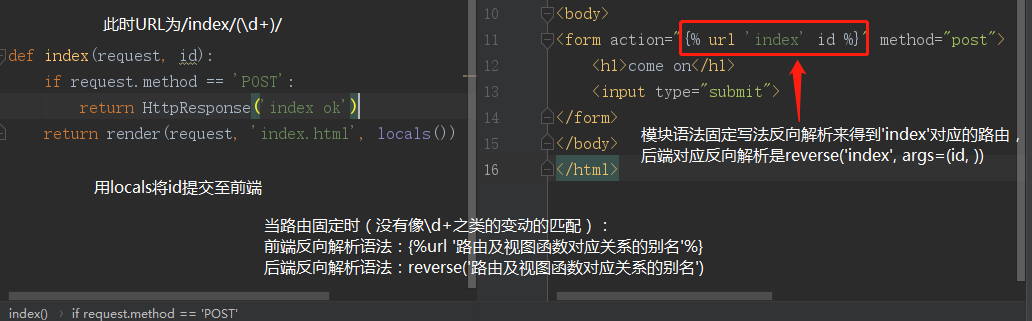
3.4 有名分组反向解析
同无名分组的反向解析的区别在于:
- 视图函数request后的形参名需要同分组名一致
- reverse('index', kwargs={'id': 10})
- 前端{% url 'index' id=10%}
不过有名分组的反向解析也支持无名分组解析的方式,这就意味无论有名分组还是无名分组,我们都可以统一用无名分组反向解析的方式。
4. 路由分发
项目名下的url.py(总路由)不再做路由与视图函数对应关系的匹配关系,而是做路由的分发。注意路由分发的总路由正则千万不要加$。
首先在各APP文件夹下新建urls.py文件,然后在里面写各自的路由与其视图函数对应关系:

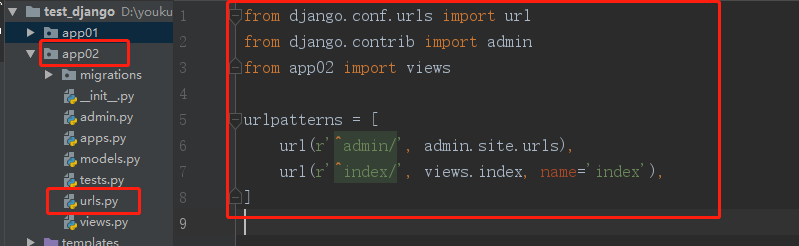
随后在总路由中进行分发:
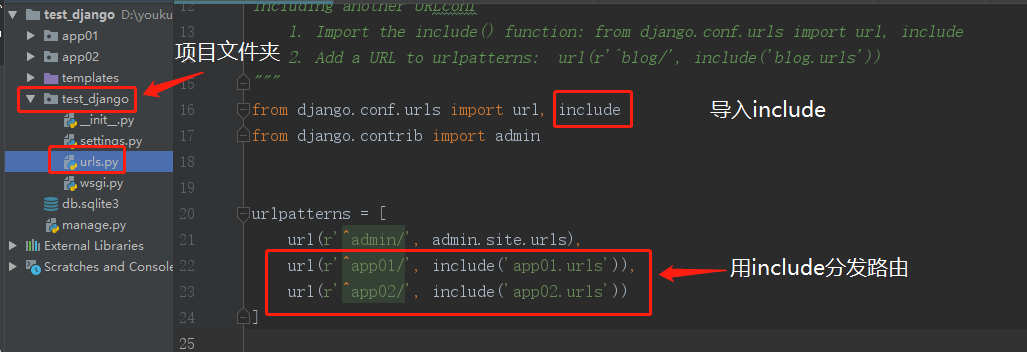
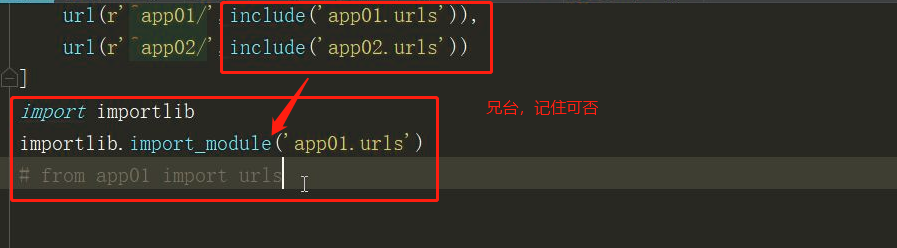
include('app01.urls')内部走的实际是:
5. 名称空间(用上述方法足以,名称空间不需要掌握)


名称空间(了解) url(r'^app01/',include(app01_urls,namespace='app01')), url(r'^app02/',include(app02_urls,namespace='app02')) app01.urls.py from django.conf.urls import url from app01 import views urlpatterns = [ url(r'^index/',views.index,name='index') ] app02.urls.py from django.conf.urls import url from app02 import views urlpatterns = [ url(r'^index/',views.index,name='index') ] app01.views.py reverse('app01:index') app02.views.py reverse('app02:index')
名称空间一般不用,因为取名字时可以通过给路由与视图函数对应关系的别名加上有区别性的前缀(比如应用名:app01_index)来避免因为不同app别名重复而导致reverse反向解析结果异常的问题(比如解析到其他app的路由)。
6. 仿静态网页
百度这个大爬虫具有搜索优化seo,会优先加载静态的网页,所以静态网页优先级比较高,我们可以仿静态网页来增加优先级。
其实原理很简单,就是把路由名字改一下,后面加个.html
url(r'^index.html',views.index,name='app01_index')
7. 虚拟环境
每创建一个虚拟环境就相当于重新下载了一个Python解释器,可以为不同的项目配置不同的环境(安装各自的模块,互不干扰,让每个项目都有属于自己的python环境,避免导入过多模块造成资源浪费),而且删除该虚拟环境时其安装的所有模块也会被删除。

8. Django2.0与Django1.0的区别
django1.0与django2.0之间的区别 django2.0里面的path第一个参数不支持正则,你写什么就匹配,100%精准匹配 django2.0里面的re_path对应着django1.0里面的url 虽然django2.0里面的path不支持正则表达式,但是它提供五个默认的转换器 str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式 int,匹配正整数,包含0。 slug,匹配字母、数字以及横杠、下划线组成的字符串。 uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。 path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?) 自定义转换器 1.正则表达式 2.类 3.注册 # 自定义转换器 class FourDigitYearConverter: regex = '[0-9]{4}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value # 占四位,不够用0填满,超了则就按超了的位数来! register_converter(FourDigitYearConverter, 'yyyy')
PS:路由匹配到的数据默认都是字符串形式
二. 视图层
1. FBV与CBV
FBV是基于函数的视图,CBV是基于类的视图。目前上面写的都是FBV,接下来我们重点来看一下CBV。
1.1 首先我们在视图层views.py中写了一个类
from django.views import View # 需要导入View class Index(View): def get(self, request): return render(request, 'index.html') def post(self, request): return HttpResponse('23333')
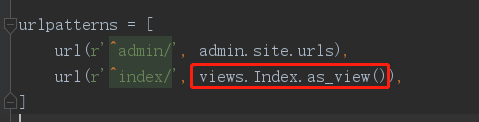
1.2 url中写路由与该类的对应关系
1.3 index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>index</title> <script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script> <script src="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script> <link href="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/css/bootstrap.min.css" rel="stylesheet"> </head> <body> <form action="" method="post"> <h1>come on</h1> <input type="submit"> </form> </body> </html>
运行,通过路由分发找到该app01的index: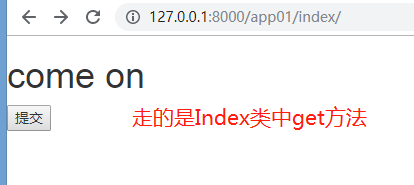
点提交:
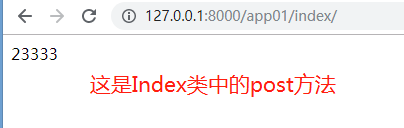
是不是很疑惑为什么定义一个继承Views的类,可以根据请求方式自动走get或者post方法?接下来我们一起来探究一下。
首先来看一下路由:url(r'^index/', views.Index.as_view()),Index是我们自己定义的视图类,那么as_view很大概率是类方法。as_view()就是执行该方法,查看一下该方法(根据类中属性与方法的查找顺序,as_view方法Index类本身没有,所以会找父类View的as_view方法):


通过查看View类中的as_view方法,我们发现它返回的是一个view函数名,也就是view函数的内存地址,而当我们一个路由成功被匹配时,会自动调用执行后面的视图函数。所以当我们url(r'^index/', views.Index.as_view())被匹配成功时,就相当于直接执行view()方法。接下来我们再看看view方法里面有啥。

趁热打铁,我们马上瞧瞧dispath函数是啥(因为该对象及其父类Index没有改方法,所以最后会去Index的父类View中找)。

顺便看一下刚刚不知道的属性或方法是啥:
这是Django所支持的八种request.method方法:
![]()
所以总结一下:
- url中路由url(r'^index/', views.Index.as_view())成功匹配时,会执行views.Index.as_view()(),as_views()返回的是view函数。所以相当于执行views.view()。
- view函数执行返回的是一个对象方法——dispatch执行的结果。
- dispatch方法执行返回的handler函数的执行结果,而handler函数是用反射从self对象名称空间里取出来的(再次涉及到属性查找顺序),反射取的方法是根据小写的request.method。
- 我们自定义类中写了get和post函数,可以被反射取到并将该函数的内存地址赋值给handler。
- handler执行的结果实际上就是我们定义的get或者post执行的结果,然后通过dispatch继续return给view。所以view函数执行时就相当于执行get或者post。
- 以上注意属性和方法(as_view及getattr反射)的查找顺序。
最后附一张关于request.method的图: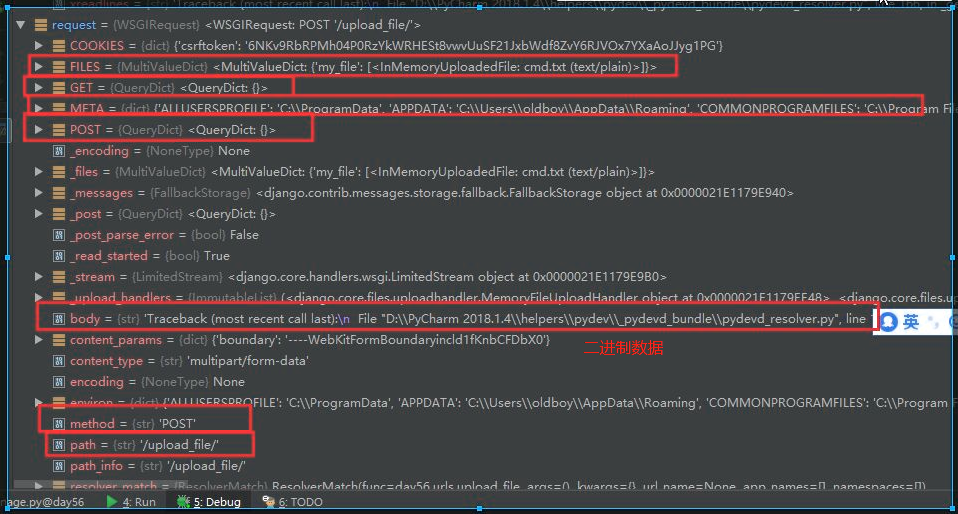
其中request.path和get_full_path的区别:
print('path:',request.path) print('full_path:',request.get_full_path()) path: /upload_file/ full_path: /upload_file/?name=jason
request.body中存放的是二进制原生数据,request.path可以获取URL的后缀,但是get请求后面携带的?xxx=yyy这些信息时获取不到的(request.get_full_path()能够获取)。
2. 大文件上传
注意事项:
- form表单的method需要指定为post
- form表单的enctype需要改为multipart/form-data
- 后端配置文件注释掉中间件'django.middleware.csrf.CsrfViewMiddleware
- 通过request.FILES获取用户上传的post文件数据
file_obj = request.FILES.get('my_file') print(file_obj.name) with open(file_obj.name,'wb') as f: for line in file_obj.chunks(): f.write(line)
3. JsonResponse
JsonResponse是Django内部自带的序列化数据,以便于前后端数据交互,就跟各编程语言之间和前后端使用json模块进行数据的交互。
首先需要导入一个模块中的JsonResponse类:
from django.http import JsonResponse
我们看一下JsonResponse的源码:
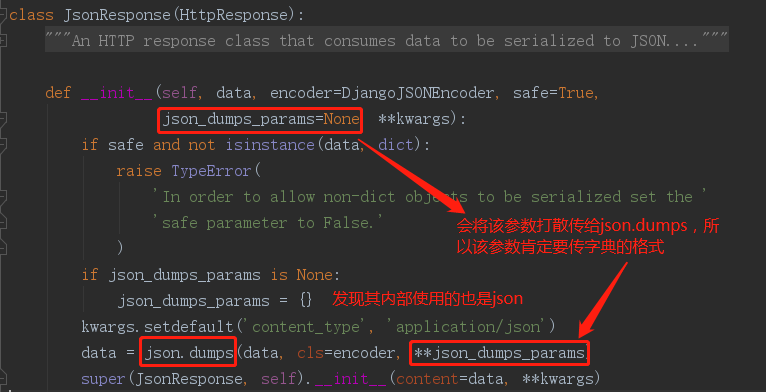
接下来我们再看看json.dumps的源码:

所以当我们序列化的字符串中有中文,想让它正常显示而不是被自动编码为二进制时,可以通过给JsonResponse传参来实现:
JsonResponse(
{'name':'Jason大帅比','password':'1888888'},
json_dumps_params = {'ensure_ascii':False}
)
再额外提一下,因为json.dumps能序列化的对象是固定的,当我们想要序列化的对象json.dumps不支持时(比如说时间对象datetime),我们可以通过重写其中的方法来实现支持序列化时间对象。
首先我们先看一下json.dumps的源码:

继续往下看一下JSONEncoder的源码:
首先一进去就能看到json.dumps支持的python对象:

仔细一看,其中的defaultf方法有点东西,我们可以对它下手了。
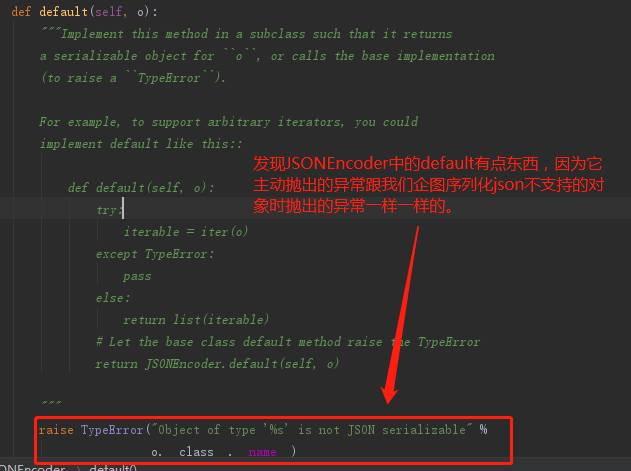

接下来我们对default下手,首先要重写一个类中的方法必须继承该类,default方法输入JSONEncoder类,所以:
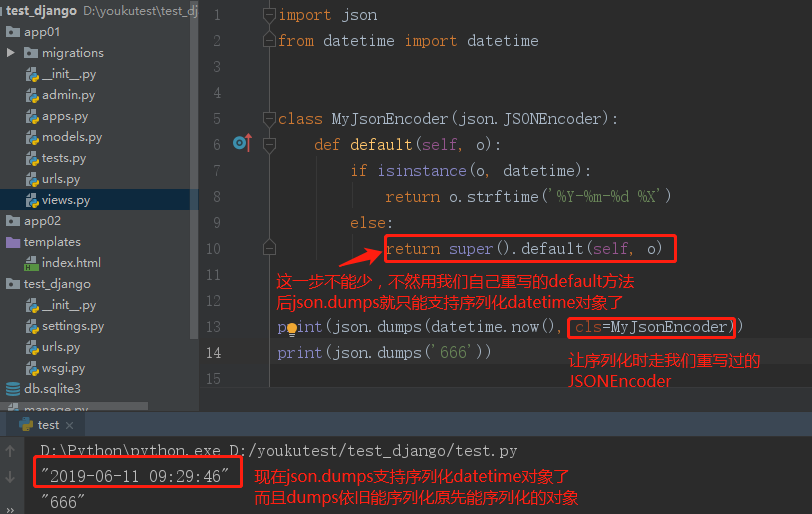
import json from datetime import datetime class MyJsonEncoder(json.JSONEncoder): def default(self, o): if isinstance(o, datetime): return o.strftime('%Y-%m-%d %X') else: return super().default(self, o) print(json.dumps(datetime.now(), cls=MyJsonEncoder)) print(json.dumps('666'))