Python
预先配置好Python环境和requests, beautifulsoup4, lxml包.
Step 1 模拟登录
打开开发者工具, 手动登录, 然后在Network中找到登录网址(Request Method为POST)及登录表. 为防止页面刷新过快, 可勾选Preserve log.
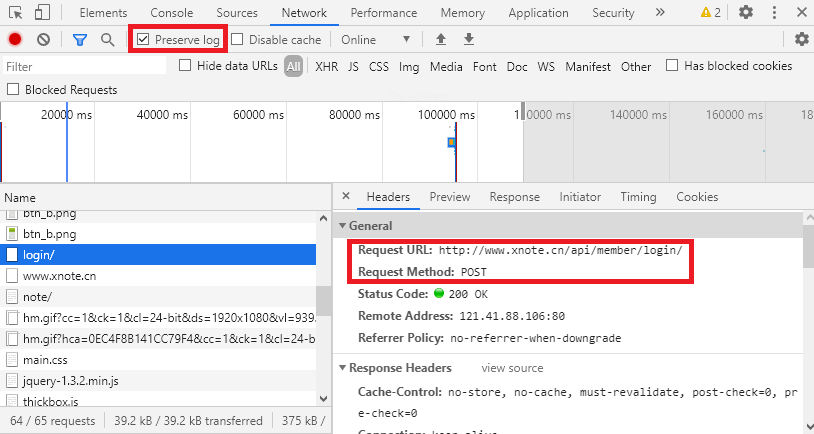
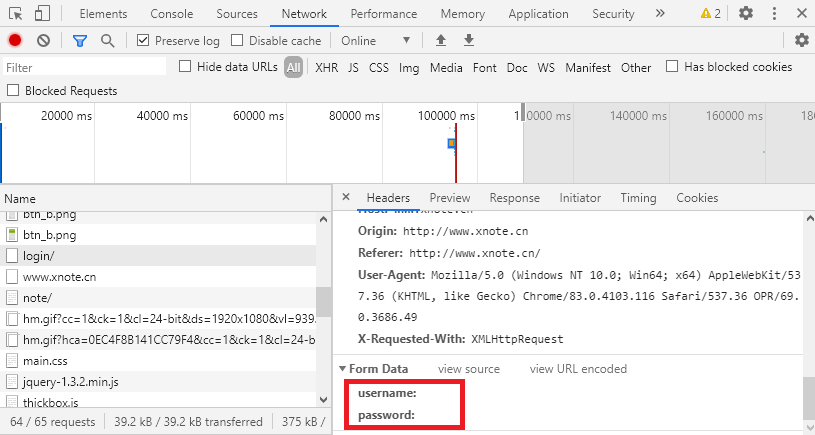
使用下述Python代码模拟登录.
import requests
s = requests.Session()
form = {
'username': '',
'password': '',
}
s.post(loginUrl, form)
Step 2 查找结点
from bs4 import BeautifulSoup
r = s.get(url) # 待爬网页
r.encoding = 'gbk' # 网页编码
soup = BeautifulSoup(r.text, 'lxml')
# find示例
title = soup.find('h1').text
# find_all示例, 其中目标结点结构为<dl class='attachlist'><dt><a href=fileUrl>filename</a></dt></dl>
dls = soup.find_all('dl', class_ = 'attachlist')
for dl in dls:
filename = dl.dt.a.text
fileUrl = baseUrl + dl.dt.a.get('href')
Step 3 下载
# Modified from https://www.jianshu.com/p/e3444c52c043
def download(url, s, filename):
import urllib, os
# filename = urllib.parse.unquote(url)
# filename = filename[filename.rfind('/') + 1:]
try:
r = s.get(url, stream=True, timeout = 2)
chunk_size = 1000
timer = 0
length = int(r.headers['Content-Length'])
print('Downloading {}'.format(filename))
if os.path.isfile('./' + filename):
print(' File already exist, skipped')
return False
with open('./' + filename, 'wb') as f:
for chunk in r.iter_content(chunk_size):
timer += chunk_size
percent = round(timer/length, 4) * 100
print('
{:4f}'.format((percent)), end = '')
f.write(chunk)
print('
Finished ')
return True
except requests.exceptions.ReadTimeout:
print('Read time out, this file failed to download')
return False
except requests.exceptions.ConnectionError:
print('ConnectionError, this file failed to download')
return False
Javascript
-
用Javascript比Python更灵活方便. 不需要配置编程环境, 也不需要模拟登录, 在浏览器上手动登录后就地运行脚本即可, 并且可以在开发者工具 - Console里实时测试脚本.
-
需要会一点jQuery的知识(很简单, 30分钟入门).
-
可以将脚本保存在油猴插件中以便重复使用. 注意如果待爬网站不自带jQuery, 需要在油猴插件的脚本中手动导入, 例如
// @require https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js
这里帖出一个知轩藏书的爬虫
// ==UserScript==
// @name 知轩藏书爬虫
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @include *zxcs.me*
// @grant none
// @require https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js
// ==/UserScript==
$(function() {
console.log('知轩藏书爬虫正在运行')
var spiderShits = []
var busyCount = 0
var failureId = []
function searchString(str, re, defau) {
var matches = str.match(re)
return matches === null ? defau : matches[0]
}
function getInfo(bookId) {
busyCount++
var postUrl = 'http://www.zxcs.me/post/' + bookId
$.ajax({
url: postUrl,
dataType: 'text',
success: function (result) {
var output = {}
output.id = bookId
output.title = $(result).find('div#content h1').text()
var ps = $(result).find('div#content p')
var tmpArr = ps.eq(0).text().trim().split(/s+/)
var tmp = tmpArr.pop()
output.catogroy1 = tmpArr.pop()
output.catogroy2 = tmp
var detail = ps.eq(2).text().replace(/s/g, '')
output.size = searchString(detail, /[d.]+[MK]B/, '0')
output.intro = detail.replace(/^.*【内容简介】:/, '')
getVotes(output, bookId)
},
error: function () {
console.error('%s 无法读取书籍信息', bookId)
busyCount--
failureId.push(bookId)
}
})
}
function getVotes(output, bookId) {
var votesUrl = "http://www.zxcs.me/content/plugins/cgz_xinqing/"
+ "cgz_xinqing_action.php?action=show&id="
+ bookId + "&m=" + Math.random()
$.ajax({
url: votesUrl,
dataType: 'text',
success: function (data, status) {
var votesArr = data.split(',')
output.xian = votesArr[0]
output.liang = votesArr[1]
output.gan = votesArr[2]
output.ku = votesArr[3]
output.du = votesArr[4]
getDownloadUrl(output, bookId)
},
error: function () {
console.error('%s 无法获取投票', bookId)
busyCount--
failureId.push(bookId)
}
})
}
function getDownloadUrl(output, bookId) {
var downUrl = 'http://www.zxcs.me/download.php?id=' + bookId
$.ajax({
url: downUrl,
dataType: 'text',
success: function (data, status) {
output.fileUrl = $(data).find('.downfile a').first().attr('href')
spiderShits.push(output)
busyCount--
},
error: function() {
console.error('%s 无法获取下载链接', bookId)
busyCount--
failureId.push(bookId)
}
})
}
var baseUrl = $('div#pagenavi a').last().attr('href')
var pagesCount, title
var startTime, endTime
var booksCount = 0
function intervalString(interval) {
interval = Math.floor(interval / 1000)
var ret = (interval % 60) + '秒'
interval = Math.floor(interval / 60)
if (interval) {
ret = (interval % 60) + '分' + ret
interval = Math.floor(interval / 60)
if (interval) {
ret = interval + '时' + ret
}
}
return ret
}
function download() {
endTime = new Date().getTime()
var msg = '已完成。累计用时'+intervalString(endTime - startTime)
+'。尝试抓取书籍'+booksCount+'本,失败'+failureId.length+'本。
'
if (failureId.length) {
msg += '失败书籍ID:'+failureId.toString()
}
alert(msg)
var a = document.createElement('a')
var e = document.createEvent('MouseEvents')
e.initEvent('click', false, false)
a.download = title + '.json'
var blob = new Blob([JSON.stringify(spiderShits)])
a.href = URL.createObjectURL(blob)
a.dispatchEvent(e)
}
function checkBusyCount(index, maxIndex) {
if (busyCount) {
setTimeout(checkBusyCount, 1000, index, maxIndex)
} else {
requestPage(index + 1, maxIndex)
}
}
function parsePage(index, maxIndex, bookIdArr) {
console.log('正在解析第%d页...', index)
var len = bookIdArr.length
booksCount += len
for (let i = 0; i < len; ++i) {
getInfo(bookIdArr[i])
}
setTimeout(checkBusyCount, 1000, index, maxIndex)
}
function requestPage(index, maxIndex) {
if (index > maxIndex) {
console.log('完成')
download()
return
}
var pageUrl = baseUrl + index
$.ajax({
url: pageUrl,
dataType: 'text',
success: function(result) {
var bookIdArr = []
var as = $(result).find('dl#plist dt a')
for (var i = 0; i < as.length; ++i) {
bookIdArr.push(as.eq(i).attr('href').replace(/^.*//, ''))
}
parsePage(index, maxIndex, bookIdArr)
},
error: function() {
console.log('%s不存在或加载失败, 退出', pageUrl)
download()
}
})
}
if (baseUrl) {
pagesCount = searchString(baseUrl, /d+$/, null)
if (pagesCount === null) {
return
}
baseUrl = baseUrl.replace(/d+$/, '')
title = $('div#ptop').text().trim().split(/s+/).pop()
if (confirm('找到'+pagesCount+'个页面,是否爬取【'+title+'】板块下的书籍信息?')) {
var input = prompt('输入待爬取页码,格式为"起始页码 终止页码"'
+ '
完成前不要进行任何操作,完成后数据将自动保存。', '1 '+pagesCount)
if (input == null) {
return
}
var inputInts = input.trim().split(/s+/).map(str => parseInt(str))
if (inputInts.length !== 2
|| inputInts[0] < 1 || inputInts[1] > pagesCount
|| inputInts[0] > inputInts[1]) {
alert('页码格式不合法!')
return
}
startTime = new Date().getTime()
requestPage(inputInts[0], inputInts[1])
}
}
})
爬取结果会自动保存为一个json文件. 之后可以随便找一个在线json转Excel的网站将之转化为Excel表格(例如JSON 转换 Excel - 在线小工具). 效果如下
