一、简介
1、Set概念
Set可以理解为集合,非常类似数据概念中的集合,集合三大特征:1、确定性;2、互异性;3、无序性,因此Set实现类也有类似的特征。
2、HashSet
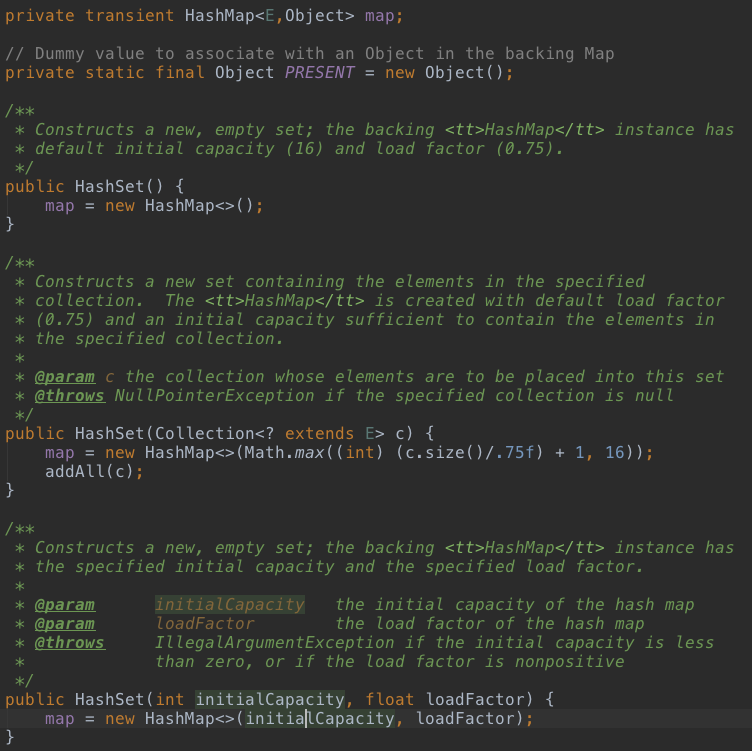
HashSet继承自AbstractSet,实现了Set接口,但是其源码非常少,也非常简单。内部使用HashMap来存储数据,数据存储在HashMap的key中,value都是同一个默认值:
二、HashSet几个重要的方法
1、add(E e)
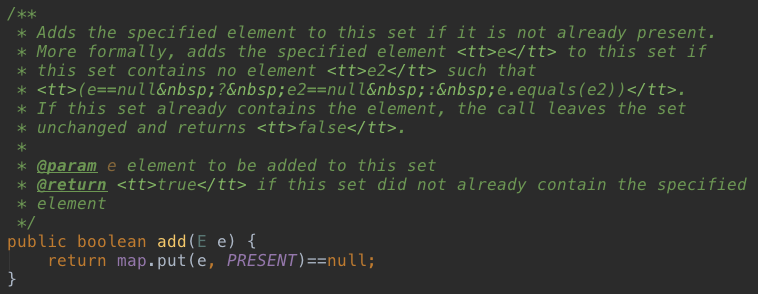
HashSet的确定性,也可以理解为唯一性,是通过HashMap的put方法来保证的,往HashMap中put数据时,如果key是一样的,只会替换key对应的value,不会新插入一条数据。所以往HashSet中add相同的元素没有什么用,这里的相同是通过equals方法保证的,具体的在HashMap中细说。
2、remove(Object o)
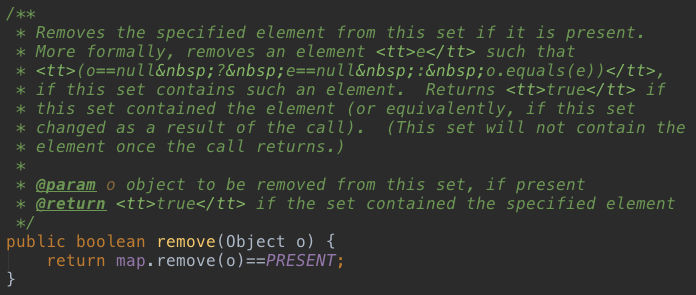
简单粗暴,从HashMap中移除一条数据。
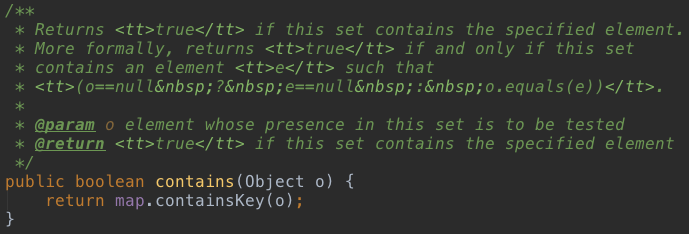
3、contains(Object o)
4、iterator()

5、其他
其他的方法诸如:size()、isEmpty()、contains()、clear()等都完全委托给了HashMap。需要注意的是:HashSet没有提供set、get等方法。
源码如下:
 View Code
View Code三、LinkedHashSet
1、LinekdHashSet简介
LinkedHashSet继承自HashSet,源码更少、更简单,唯一的区别是LinkedHashSet内部使用的是LinkHashMap。这样做的意义或者好处就是LinkedHashSet中的元素顺序是可以保证的,也就是说遍历序和插入序是一致的。
2、Demo使用

打印日志如上,HashSet和HashMap都不保证顺序,Link**能保证顺序。
源码如下:
View Code3、debug中奇异现象
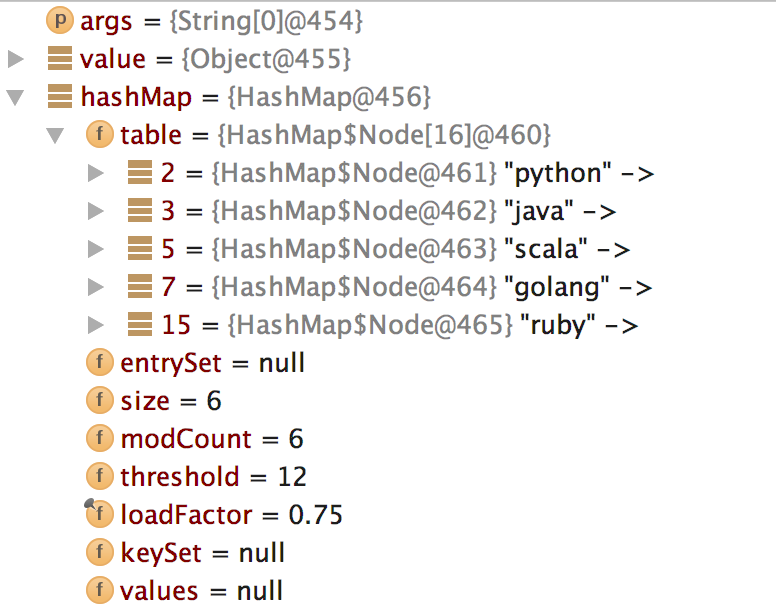
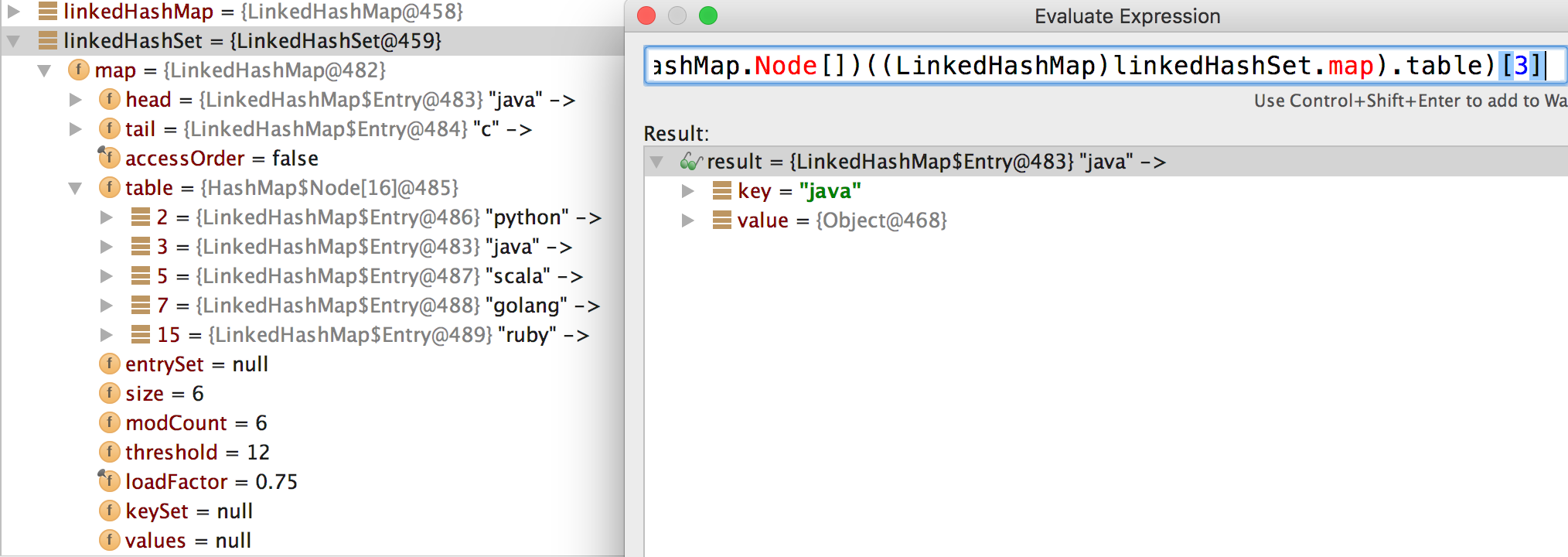
如上,我们明明添加了6个元素,但是table中只有5个,怎么回事呢?初步猜测应该是“c”元素和其中某一个元素位于同一个bucket,验证如下:

我们发现,“java”竟然和“c”位于同一个bucket,他俩在同一个链表中。唯一的疑惑是:“c”是后加入的元素,按理说应该在链表的表头才对啊,这个问题还需要探究。
同时这里也介绍了一种能debug到HashMap内部数据结构的方法,但是需要注意2个问题:
1、需要在AS中设置一下,否则debug看到的信息不是这样的,如下图:
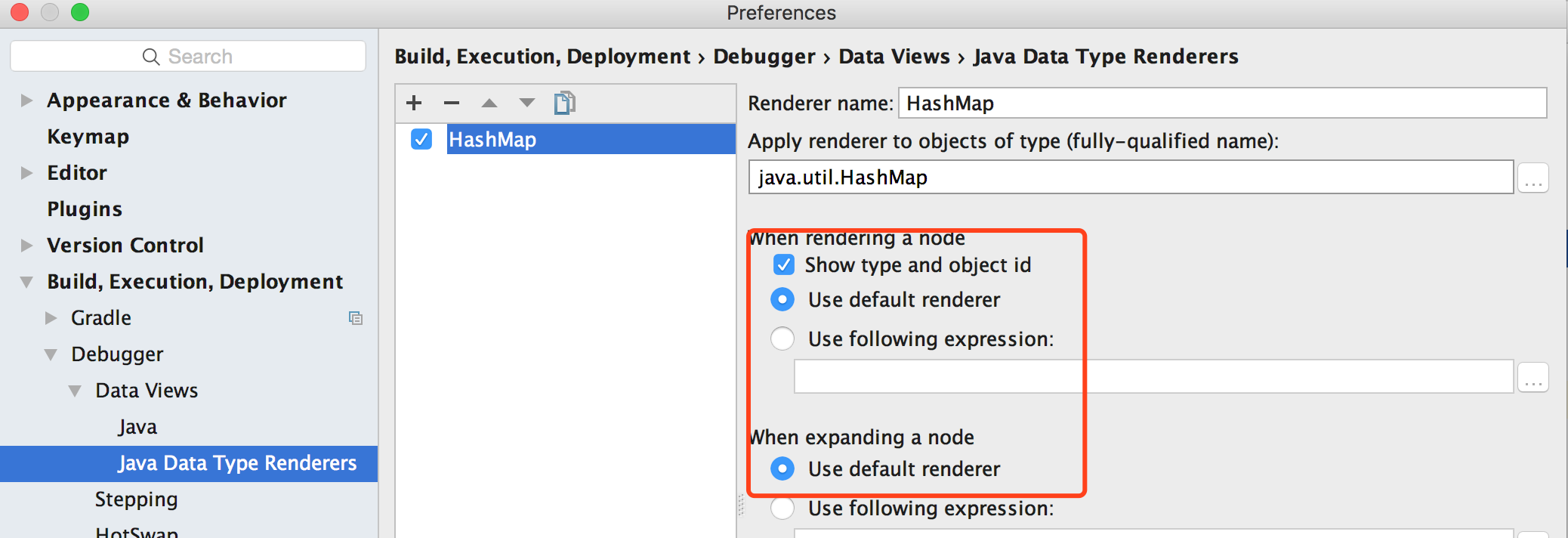
2、直接使用table[3].next是不行的, 需要像图上那样,些完整的包名才行。
4、继续debug
如上所示,设置HashSet之后,同样能看到如下信息:
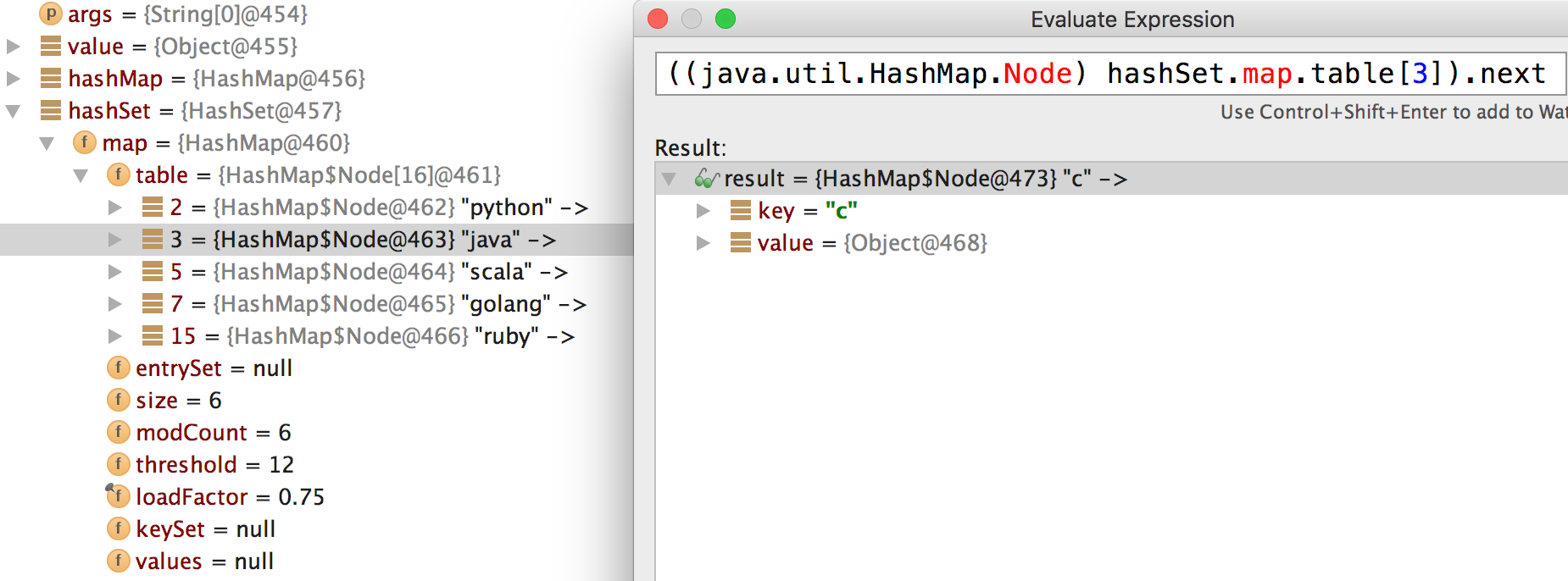
看看LinkedHashMap,如下图,LinkedHashMap中多了head和tail,这是指向表头、表尾的指针,head指向“java”,tail指向“c”,这和我们的插入序保持一致,但是实际存储和之前是一样的。

LinkedHashSet如下图: