学习适应结构化输出空间进行语义分割
|
在语义分割场景中,虽然物体在外表上不同,但是他们的输出是结构化且共享很多例如空间分布, 局部内容等信息。所以作者提出了multi-level的输出空间adaptation。 本文提出一种在未知领域强化source领域知识的finetune,作者观察到分割效果不好的痛点 (例如源领域是天气好的图片,目标领域是下雨天气,预测下雨天气分割时,对于车子这些原有领域 已知的目标,我们要强化它的分割效果)。 作者主要做了两组实验,在虚拟数据集如GTA5等训练,然后在真实数据测试。在一个城市的数据 训练,然后在另一个城市测试。 |
Overview of the Proposed Model
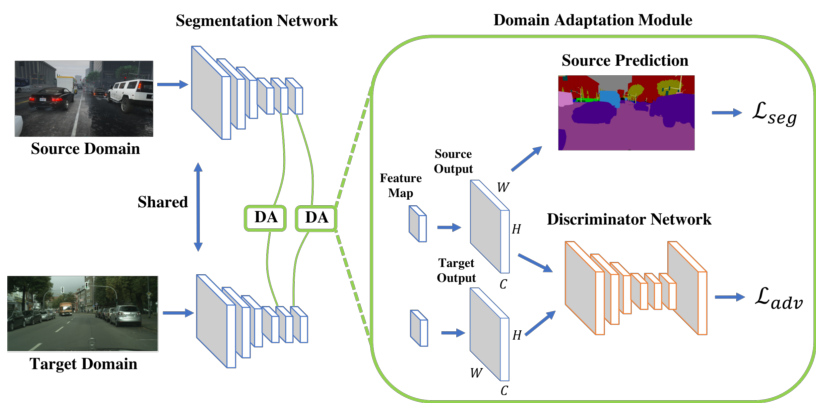
算法主要流程:
为了解决分割网络在一个领域往另一个领域迁移,首先在source数据集训练一个backbone。然后对于source和target数据集抽样,通过对样本的feature map做输入,训练一个判别网络来判断target图有哪些知识是来源于source。然后用判别器得到的Ladv和Lseg同时对网络进行finetune。
Network Architecture and Training
Discriminator
判别器由{64, 128, 256, 512, 1}x4x4, stride=2的卷积层组合而成,除了最后一层都用0.2的leaky ReLU激活。最后一层加入upsample恢复大小,不使用BN。
Segmentation Network
在deeplab-v2上做改动,改部分层的stride、加入ASPP,实验说在Cityspaces上有65.1% mIoU。
NetworkTraining
输入源图片得到分割输出Ps,求Lseg训练分割网络。然后对于目标输入,得到分割输出后Pt,和Ps一起优化Ld。另外还要优化对抗损失Ladv。
Objective Function for Domain Adaptation
总损失函数为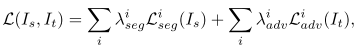 ,i 是multi-level的不同卷积层特征图进行处理得到的结果,分为前后两部分交叉熵。
,i 是multi-level的不同卷积层特征图进行处理得到的结果,分为前后两部分交叉熵。
第一部分是分割效果的交叉熵: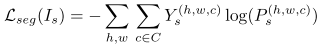 ,第二部分则是
,第二部分则是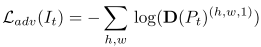 ,在部分的设计在于最大化特征图target中属于source的像素点,目的在于让网络识别哪些是之前source领域有的知识。
,在部分的设计在于最大化特征图target中属于source的像素点,目的在于让网络识别哪些是之前source领域有的知识。
至于怎么训练网络判断,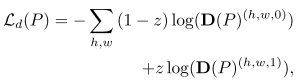 ,z=0表示点输入目标领域,不在我们知道的知识范围内。训练则通过在两个领域分别采样即可。
,z=0表示点输入目标领域,不在我们知道的知识范围内。训练则通过在两个领域分别采样即可。
优化目标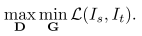 ,在最小化source image的分割损失的情况下,最大化目标预测值被认为是源预测值的可能,即最大化运用会原先的知识。
,在最小化source image的分割损失的情况下,最大化目标预测值被认为是源预测值的可能,即最大化运用会原先的知识。
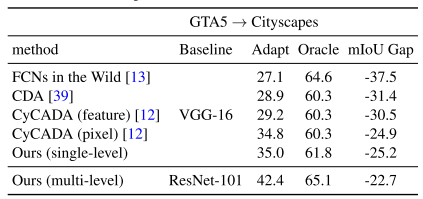
Experimental Results