前言
- 深度学习是最近比较热的词语。说到深度学习的应用,第一个想到的就是Prisma App的图像风格转换。既然感兴趣就直接开始干,读了论文,一知半解;看了别人的源码,才算大概了解的具体的实现,也惊叹别人的奇思妙想。
声明
- 代码主要学习了【titu1994/Neural-Style-Transfer】
的代码,算是该项目部分的简化版或者删减版。这里做代码的注解和解释,也作为一个小玩具。 - 论文可以参考【A Neural Algorithm of Artistic Style】,网上也有中文的版本。
- 使用的工具:py34、keras1.1.2、theano0.8.2、GeForce GT 740M (CNMeM is disabled, cuDNN not available)。
实现原理
1. 总流程
-
实现流程如下,可以看到这里总共分为5层,本次实验使用vgg16模型实现的。

-
如上,a有个别名是
conv1_1,b是conv2_1,依次类推,c,d,e对应conv3_1,conv4_1,conv5_1;输入图片有风格图片style image和内容图片content image,输出的是就是合成图片,然后用合成图片为指导训练,但是训练的对象不像是普通的神经网络那样训练权值w和偏置项b,而是训练合成图片上的像素点,以达到损失函数不断减少的效果。论文使用的是随机的噪声像素图为初始合成图,但是使用原始图片会快一点。
2. 内容损失函数 - Content Loss
-
下面是content loss函数的定义。
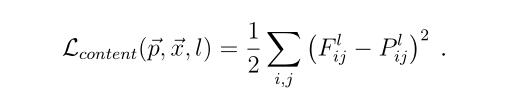
-
l代表第l层的特征表示,p是原始图片,x是生成图片。公式的含义就是对于每一层,原始图片生成特征图和生成图片的特征图的一一对应做平方差。
3. 风格损失函数 - style loss
-
在定义风格损失函数之前首先定义一个Gram矩阵。

-
F是生成图片的特征图。上面式子的含义:Gram第i行,第j列的数值等于把生成图在第l层的第i个特征图与第j个特征图分别拉成一维后相乘求和。
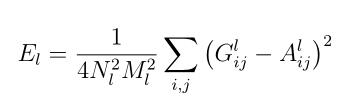
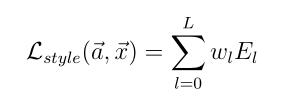
- 上面是风格损失函数,
Nl是指生成图的特征图数量,Ml是图片宽乘高。a是指风格图片,x是指生成图片。G是生成图的Gram矩阵,A是风格图的Gram矩阵,wl是权重。
4. 总损失
- 总损失函数如下,
alpha与beta比例为1*10^-3或更小。

代码讲解
1. 图片预处理和还原
def preprocess_image(image_path):
img = imread(image_path)
// GPU显存有限,这里使用400*400大小的图片
img = imresize(img, (400, 400)).astype('float32')
// 这里要对RGB通道做预处理
// 这里貌似是RGB的平均值,具体不清楚
img = img[:, :, ::-1]
img[:, :, 0] -= 103.939
img[:, :, 1] -= 116.779
img[:, :, 2] -= 123.68
img = img.transpose((2, 0, 1)).astype("float32")
img = np.expand_dims(img, axis=0)
return img
def deprocess_image(x):
x = x.reshape((3, 400, 400))
x = x.transpose((1, 2, 0))
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
2. content loss
def content_loss(base, combination):
channel_dim = 0 if K.image_dim_ordering() == "th" else -1
channels = K.shape(base)[channel_dim]
size = 400 * 400
multiplier = 1 / (2. * channels ** 0.5 * size ** 0.5)
return multiplier * K.sum(K.square(combination - base))
3. style loss
def gram_matrix(x):
assert K.ndim(x) == 3
features = K.batch_flatten(x)
gram = K.dot(features, K.transpose(features))
return gram
def style_loss(style, combination):
assert K.ndim(style) == 3
assert K.ndim(combination) == 3
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = 400 * 400
return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
结果
输入:


输出:


分析
- 可以看出效果每一代都有进步,因为自己的显卡渣,跑一代估计要1.5个小时,自己测试的时候总共跑了14个小时,不过这里有个技巧,就是可以把上一代的图片继续做输入,这样中途有什么事就可以停止。下次只要把上次输出的图片当输入就可以。
- 因为是个小玩具,所以图片的切割都是用ps切出来的。其他的什么mask都没有实现。
- vgg16模型加载原项目的权值。
- 具体项目代码可见【自己的github项目】上的代码、权值文件和测试图片,因为中途修改过,可能有些地方需要改过来,不过代码比较简单,估计很快就可以找到问题了。