BING
论文《BING: Binarized Normed Gradients for Objectness Estimation at 300fps》
南开大学媒体计算实验室,CVPR2014 http://mmcheng.net/bing/comment-page-9/
论文翻译:http://www.cnblogs.com/larch18/p/4569543.html
与edge boxes有异曲同工之妙,也是考虑了我们人类观察事物的习惯:先粗看,再细看。BING就是提供一种”粗略检测“的方法,先将目标大概的位置提取出来,主要目的是为了提速,与edge boxes不同的地方在于,BING是基于学习的,可以通过训练使得检测器更专注.
具体的操作:

-
(a)输入一张图象,其中红框是物体,绿框不是物体
-
(b)首先将输入图像重置为不同尺度的,在不同的尺度下计算梯度。然后再隔点取8*8大小的框,作为一个对应图像的64维的NG特征(该特征优势:[1].归一化了支持域,所以无论对象窗口如何改变位置,尺度以及纵横比,它对应的NG特征基本不会改变。也就是说,NG特征是对于位置,尺度,纵横比是不敏感的;[2]. NG特征的紧凑性,使得计算和核实更加有效率,而且能够很好的应用在实时应用程序中)
-
(cd)使用线性SVM分类器,在NG特征上训练一个64维的分类器
而在训练的过程当中,最最核心的就是 这个64位的特征就直接用一个64位的数表示,那对特征的操作表示为对位的操作。大大的降低了时间复杂度。
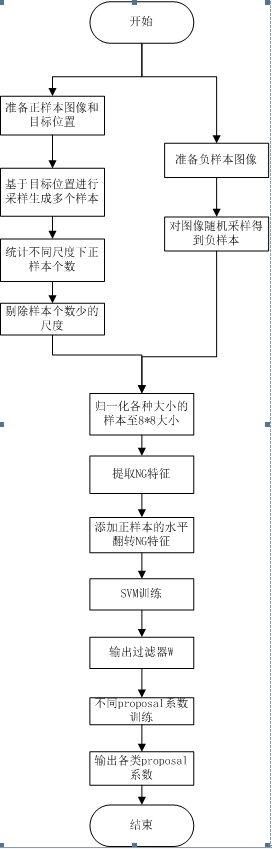
算法流程
根据BING代码,给出训练阶段算法流程图,如下所示:
下载代码: https://github.com/MingMingCheng/CmCode
该代码中除了bing还有显著性分割之类的,bing的代码仅为LibLinear和Objectness两部分.
对系统的要求:在图片较多的情况下(默认使用的VOC2007数据集),需要约4G内存.因此为了训练模型,程序不能够编译为32位(通常只能使用2G内存左右,即使在VS中开启大地址访问也不行).程序中对窗口的打分操作计算很容易通过位运算和SSE指令(支持8x8=64bit)来完成快速运算.因此如果要编译为32位程序,可以加入SSE2的编译选项来加快速度,通过对比可以发现不使用SSE,CPU占用率10%左右,而开启后到达90%以上.若编译为64位程序,则无需手动开启该选项,因为几乎所有的64位处理器都有SSE2,而编译器默认对64位程序开启该选项,因此我们在开启该选项后编译时会提示:忽略未知选项“/arch:SSE2”.
From Wikipedia:
SSE instructions: The original AMD64 architecture adopted Intel's SSE and SSE2 as core instructions. SSE3 instructions were added in April 2005. SSE2 replaces the x87 instruction set's IEEE 80-bit precision with the choice of either IEEE 32-bit or 64-bit floating-point mathematics. This provides floating-point operations compatible with many other modern CPUs. The SSE and SSE2 instructions have also been extended to operate on the eight new XMM registers. SSE and SSE2 are available in 32-bit mode in modern x86 processors; however, if they're used in 32-bit programs, those programs will only work on systems with processors that have the feature. This is not an issue in 64-bit programs, as all AMD64 processors have SSE and SSE2, so using SSE and SSE2 instructions instead of x87 instructions does not reduce the set of machines on which x64 programs can be run. SSE and SSE2 are generally faster than, and duplicate most of the features of the traditional x87 instructions, MMX, and 3DNow!.
在LibLinear工程中编译生成LibLinear.lib文件
LibLinear是个SVM库,Bing中使用SVM进行训练,生成LibLinear.lib后作为Objectness工程的附加依赖库.
加速
开启OpenMP多处理器支持:C/C++ ->语言->OpenMP支持->是 (/openmp)
在配置的“C/C++->语言”选项中,另外可能需要SSE指令,在“C/C++->代码生成”中启用增强指令集->流式处理 SIMD 扩展 2 (/arch:SSE2)
32位编译:用_popcnt函数实现_popcnt64函数功能
需要自己动手在INT64类型基础上写函数。
inline INT64 __popcnt64(INT64x)
{
return __popcnt((unsignedint)(x )) +__popcnt((unsignedint)(x>> 32));
}
时间统计
在 objectness.cpp 中取消对 #define PRE_LOAD_IMAGE 的注释可以预先加载所有的图片到内存.这样不会将读磁盘的时间计算在内.另外将程序编译为release模式可以加快速度.
训练数据准备
下载 VOC 2007 数据集 ( training 和 testing) ,解压并合并后放到 ./VOC2007/
程序使用的是 OpenCV 可读取的标记数据,因此需要把原始VOC的Annotations目录下的文件做格式转换. 转换好的 VOC 2007 annotation 可以从这里下载: http://mmcheng.net/mftp/Data/VOC2007_AnnotationsOpenCV_Readable.7z
程序运行时读取VOC2007ImageSetsMain目录下的trainval.txt作为训练集,test.txt作为测试集,class.txt中记录类别名称,如果没有这几个文件,那么自己创建.
训练需要用voc提供的,当然也可以自己提供图片、写yml文件,但是效率低,很慢,不太建议,但可以尝试,本人尝试过,没发现有太大改善。测试可以自己提供图片,把你的图片放到JPEGImage下,名字换了,换成那一类 ,比如把000001.jpg替换为自己的,名字不变。
getObjBndBoxesForTestsFast是调用的主函数,训练生成的文件,在results目录下,训练完了,不用每次都再训练,注释掉trainObjectness
evaluatePerImgRecall 生成的文件直接可用MATLAB打开,可以看到随着候选框的增加,recall的上升趋势.
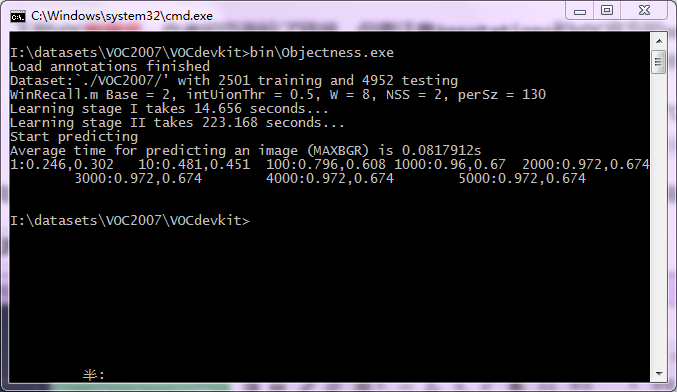
运行结果
运行结果保存在VOC2007/Results/下.
取消对程序最后一行objNess.illuTestReults(boxesTests);的注释,在VOC2007/Local/下能看到图片预测目标窗口的结果:

精度曲线
程序运行结束后,VOC2007/Results/下生成有个PerImgAllXXX.m的文件,直接在Matlab中就能跑出结果
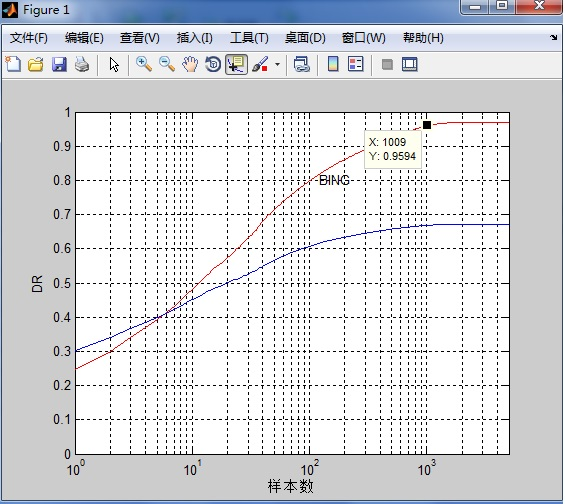
上面的精度曲线称为DR-#WIN curves,源自TPAMI 2012的一篇论文:Measuring the objectness of image windows。原文还提出了将窗口数量比如[[0,5000]归一化到[0,1]之间,用曲线下的面积作为目标检测的度量结果,并称之为the area under the curve(AUC),这样AUC的范围就在[0,1]之间了。
二值化梯度幅值(BING)
提出了一个NG特征的加速版,二值化梯度幅值,加速特征提取和测试过程.
代码中存在一个宏定义USE_BINARY,默认没有开启.
EdgeBoxes
原版是matlab代码
他人修改的有C++版:
https://github.com/AlexMa011/edgeBoxes-Cpp-version
https://github.com/zimpha/EdgeBoxes
还有python版
《Edge Boxes: Locating Object Proposals from Edges》ECCV2014,并没有涉及到“机器学习”,其采用的是纯图像的方法.研究方法:利用边缘信息(Edge),确定框框内的轮廓个数和与框框边缘重叠的轮廓个数,并基于此对框框进行评分,进一步根据得分的高低顺序确定proposal信息(由大小,长宽比,位置构成)。而后续工作就是在proposal内部运行相关检测算法。其中基于文献《Structured Forests for Fast Edge Detection》所提出的结构化边缘检测算法,得到的边缘图像,这时的边缘图像显得很紧密,需要用NMS进一步处理得到一个相对稀疏的边缘图像。
流程图,如下所示:

对比
三种对比recall:selective>edgeBox>Bing,速度相反。