参数正则化方法 - Dropout
受人类繁衍后代时男女各一半基因进行组合产生下一代的启发,论文(Dropout: A Simple Way to Prevent Neural Networks from Overfitting)提出了Dropout。
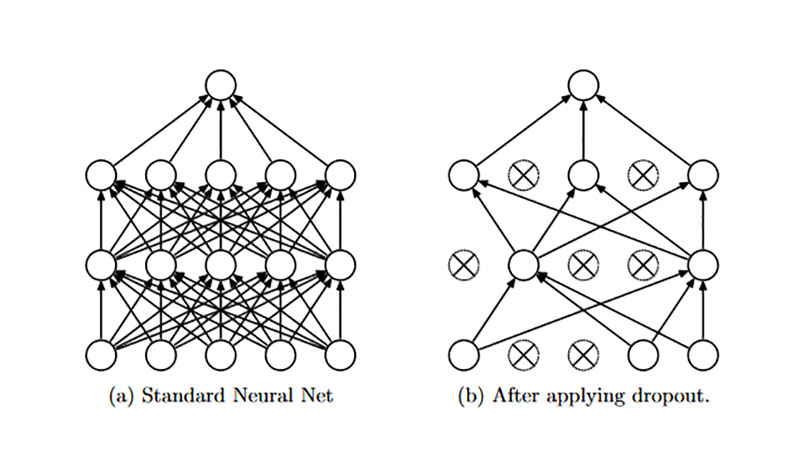
Dropout是一种在深度学习环境中应用的正规化手段。它是这样运作的:在一次循环中我们先随机选择神经层中的一些单元并将其临时隐藏,然后再进行该次循环中神经网络的训练和优化过程。在下一次循环中,我们又将隐藏另外一些神经元,如此直至训练结束。
在训练时,每个神经单元以概率p被保留(dropout丢弃率为1-p);在测试阶段,每个神经单元都是存在的,权重参数w要乘以p,成为:pw。测试时需要乘上p的原因:考虑第一隐藏层的一个神经元在dropout之前的输出是x,那么dropout之后的期望值是(E=px + (1-p)0) ,在测试时该神经元总是激活,为了保持同样的输出期望值并使下一层也得到同样的结果,需要调整(x
ightarrow px). 其中p是Bernoulli分布(0-1分布)中值为1的概率。示意图如下:
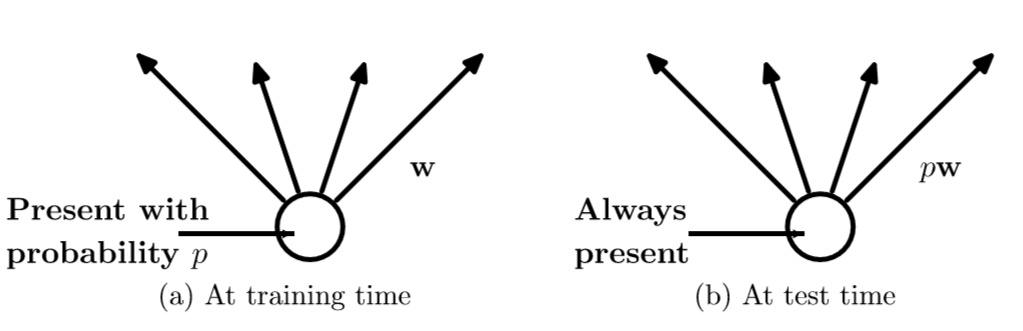
inverted dropout
在训练时由于舍弃了一些神经元,因此在测试时需要在激励的结果中乘上因子p进行缩放.但是这样需要需要对测试的代码进行更改并增加了测试时的计算量,非常影响测试性能。通常为了提高测试的性能(减少测试时的运算时间),可以将缩放的工作转移到训练阶段,而测试阶段与不使用dropout时相同,称为 **inverted dropout **:将前向传播dropout时保留下来的神经元的权重乘上1/p(看做惩罚项,使权重扩大为原来的1/p倍,这样测试时不用再缩小权重),代码参考这里。
在架构中添加inverted Dropout这一改动仅会影响训练过程,而并不影响测试过程。
drop的比例常用值是p=0.5 .
Dropout率和正规化有什么关系?我们定义Dropout率为保留一个神经元为激活状态的概率.Dropout率越高,意味着更多神经元是激活的,正规化程度越低.
Dropout可以与Max-norm regularization,较大的初始学习率和较高的动量(momentum)等结合获得比单独使用Dropout更好的效果。由于Max-norm regularization的应用,设置较大的学习率不至于发生梯度爆炸。
Dropout对于循环层效果并不理想,你可能需要稍微修改一下dropout技术来得到良好的结果。
在dropout的过程中,神经元被失活,在dropconnect的过程中,失活的是神经元之间的连接。所以dropout会使输入和输出权重都变为无效,而在dropconnect中,只有其中一种会被失活。
Dropout可以看作是Bagging的极限形式,每个模型都在当一种情况训练,同时模型的每个参数都经过与其他模型共享参数,从而高度正则化。
AlphaDropout
Alpha Dropout是一种保持输入均值和方差不变的Dropout,该层的作用是通过缩放和平移使得在dropout时也保持数据的自规范性。Alpha Dropout与SELU激活函数配合较好。更多细节参考论文Self-Normalizing Neural Networks.
代码实现
caffe dropout_layer 代码如下:
// LayerSetUp
DCHECK(threshold_ > 0.);
DCHECK(threshold_ < 1.);
scale_ = 1. / (1. - threshold_);
// forward
void DropoutLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
unsigned int* mask = rand_vec_.mutable_cpu_data();
const int count = bottom[0]->count();
if (this->phase_ == TRAIN) {
// 产生01掩码,伯努利随机数
caffe_rng_bernoulli(count, 1. - threshold_, mask);
for (int i = 0; i < count; ++i) {
// 丢弃部分置0,保留部分按inverted dropout需要放大scale_倍
top_data[i] = bottom_data[i] * mask[i] * scale_;
}
} else { // 测试阶段原样输出
caffe_copy(bottom[0]->count(), bottom_data, top_data);
}
}
//backward
void DropoutLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
if (this->phase_ == TRAIN) {
const unsigned int* mask = rand_vec_.cpu_data();
const int count = bottom[0]->count();
for (int i = 0; i < count; ++i) {
bottom_diff[i] = top_diff[i] * mask[i] * scale_;
}
} else {
caffe_copy(top[0]->count(), top_diff, bottom_diff);
}
}
}
可以进一步阅读的论文有:
- Dropout paper by Srivastava et al. 2014.
- Dropout Training as Adaptive Regularization: "we show that the dropout regularizer is first-order equivalent to an L2 regularizer applied after scaling the features by an estimate of the inverse diagonal Fisher information matrix".