pandas 是python中很重要的组件,网上关于pandas 的文章也很多,比如Python科学计算之Pandas 和 Python数据分析入门
Pandas基于两种数据类型:series与dataframe。
一个series是一个一维的数据类型,其中每一个元素都有一个标签。如果你阅读过这个系列的关于Numpy的文章,你就可以发现series类似于Numpy中元素带标签的数组。其中,标签可以是数字或者字符串。
一个dataframe是一个二维的表结构。Pandas的dataframe可以存储许多种不同的数据类型,并且每一个坐标轴都有自己的标签。你可以把它想象成一个series的字典项。
这里我使用的数据源如下:"https://raw.githubusercontent.com/alstat/Analysis-with-Programming/master/2014/Python/Numerical-Descriptions-of-the-Data/data.csv"
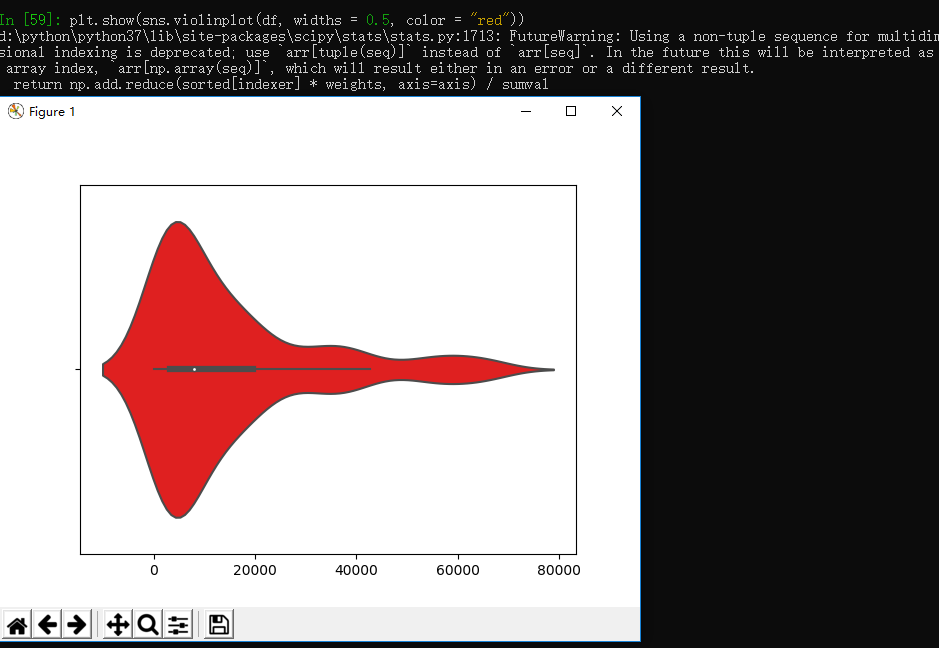
经常使用的效果如图:
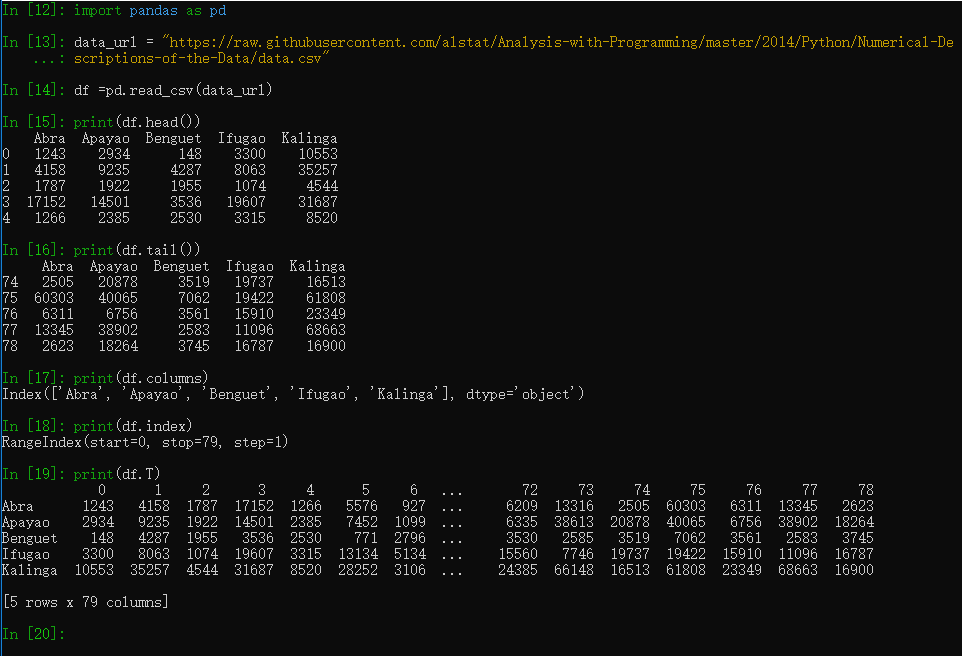
要使用pandas首先我们需要 安装并引入import pandas as pd,read_csv方法可以加载本地文件也可以读取网络文件,head()方法默认加载前面5条记录,也可以指定记录条数,比如head(10)就是前面10条记录,tail()取后面多少条记录, 也可以指定记录条数。columns显示的表格的列名,index这里可以理解为表格的下标,默认是从0开始的,可以用len(df)来获取记录数 ,df.T可以理解为表格的行列转换。

head和tail是表格前面或者后面多少条记录, 也可以用loc方法指定第几条记录,比如我这里就强制指定第一和第三条及记录,当然也可以限制值显示指定的列,drop方法是丢弃的意思,axis 参数告诉函数到底舍弃列还是行。如果axis等于0,那么就舍弃行,这里丢弃的是第2、3列的数据,describe属性对数据的统计特性进行描述,
Python有一个很好的统计推断包。那就是scipy里面的stats。ttest_1samp实现了单样本t检验。因此,如果我们想检验数据Abra列的稻谷产量均值,通过零假设,这里我们假定总体稻谷产量均值为15000
第一个数组是t统计量,第二个数组则是相应的p值。返回下述值组成的元祖:
t : 浮点或数组类型 ,t 统计量
prob : 浮点或数组类型, two-tailed p-value 双侧概率值
通过上面的输出,看到p值是0.267远大于α等于0.05,因此没有充分的证据说平均稻谷产量不是150000。将这个检验应用到所有的变量,同样假设均值为15000
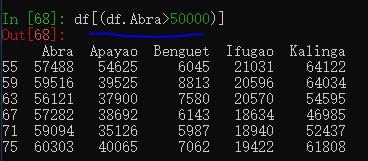
表格的列还可以当做属性来获取, 比如df["Abra"]和df.Abra都是有效的,并且列也支持过滤和排序,如下的df[df.Abra>5000]

注意到列名虽然只有一个元素,却实际上需要包含于一个列表中。如果你想要多个索引,你可以简单地在列表中增加另一个列名.我们可以在Pandas中通过调用sort_index来对dataframe实现排序
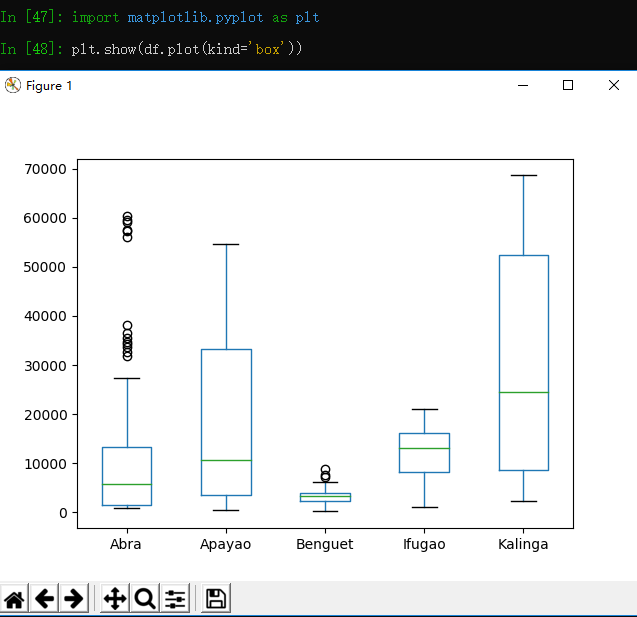
Python中有许多可视化模块,最流行的当属matpalotlib库。稍加提及,我们也可选择bokeh和seaborn模块.