雪花算法能满足高并发分布式系统环境下ID不重复,并且基于时间戳生成的id具有时序性和唯一性,结构如下:
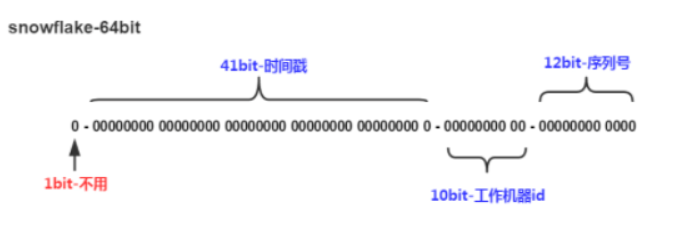
由图我们可以看出来,snowFlake ID结构是一个64bit的int型数据。
第1位bit:在二进制中最高位为1,表示的是负数,因为我们使用的id应该都是整数,所以这里最高位应该是0。
41bit时间戳:41位可以表示2^41-1个数字,如果只用来表示正整数,可以表示的数值范围是:0 - (2^41 -1),这里减去1的原因就是因为数值范围是从0开始计算的,而不是从1开始的。这里的单位是毫秒,所以41位就可以表示2^41-1个毫秒值,这样转化成单位年则是(2^41-1)/(1000 * 60 * 60 * 24 * 365) = 69
10bit-工作机器id:这里是用来记录工作机器的id。2^10=1024表示当前规则允许分布式最大节点数为1024个节点。这里包括5位的workerID和5位的dataCenterID,这里其实可以不区分,但我下面的代码进行了区分。
12bit-序列号:用来记录同毫秒内产生的不同id。12bit可以表示的最大正整数是2^12-1=4095,即可以用0,1,2,3,......4094这4095个数字,表示同一机器同一时间戳(毫秒)内产生的4095个ID序号。
原理就是上面这些,没有什么难度吧,下面我们看代码如何实现:
go的实现如下:
package main import ( "errors" "fmt" "sync" "time" ) // 因为snowFlake目的是解决分布式下生成唯一id 所以ID中是包含集群和节点编号在内的 const ( workerBits uint8 = 10 // 每台机器(节点)的ID位数 10位最大可以有2^10=1024个节点 numberBits uint8 = 12 // 表示每个集群下的每个节点,1毫秒内可生成的id序号的二进制位数 即每毫秒可生成 2^12-1=4096个唯一ID // 这里求最大值使用了位运算,-1 的二进制表示为 1 的补码,感兴趣的同学可以自己算算试试 -1 ^ (-1 << nodeBits) 这里是不是等于 1023 workerMax int64 = -1 ^ (-1 << workerBits) // 节点ID的最大值,用于防止溢出 numberMax int64 = -1 ^ (-1 << numberBits) // 同上,用来表示生成id序号的最大值 timeShift uint8 = workerBits + numberBits // 时间戳向左的偏移量 workerShift uint8 = numberBits // 节点ID向左的偏移量 // 41位字节作为时间戳数值的话 大约68年就会用完 // 假如你2010年1月1日开始开发系统 如果不减去2010年1月1日的时间戳 那么白白浪费40年的时间戳啊! // 这个一旦定义且开始生成ID后千万不要改了 不然可能会生成相同的ID epoch int64 = 1525705533000 // 这个是我在写epoch这个变量时的时间戳(毫秒) ) // 定义一个woker工作节点所需要的基本参数 type Worker struct { mu sync.Mutex // 添加互斥锁 确保并发安全 timestamp int64 // 记录时间戳 workerId int64 // 该节点的ID number int64 // 当前毫秒已经生成的id序列号(从0开始累加) 1毫秒内最多生成4096个ID } // 实例化一个工作节点 func NewWorker(workerId int64) (*Worker, error) { // 要先检测workerId是否在上面定义的范围内 if workerId < 0 || workerId > workerMax { return nil, errors.New("Worker ID excess of quantity") } // 生成一个新节点 return &Worker{ timestamp: 0, workerId: workerId, number: 0, }, nil } // 接下来我们开始生成id // 生成方法一定要挂载在某个woker下,这样逻辑会比较清晰 指定某个节点生成id func (w *Worker) GetId() int64 { // 获取id最关键的一点 加锁 加锁 加锁 w.mu.Lock() defer w.mu.Unlock() // 生成完成后记得 解锁 解锁 解锁 // 获取生成时的时间戳 now := time.Now().UnixNano() / 1e6 // 纳秒转毫秒 if w.timestamp == now { w.number++ // 这里要判断,当前工作节点是否在1毫秒内已经生成numberMax个ID if w.number > numberMax { // 如果当前工作节点在1毫秒内生成的ID已经超过上限 需要等待1毫秒再继续生成 for now <= w.timestamp { now = time.Now().UnixNano() / 1e6 } } } else { // 如果当前时间与工作节点上一次生成ID的时间不一致 则需要重置工作节点生成ID的序号 w.number = 0 w.timestamp = now // 将机器上一次生成ID的时间更新为当前时间 } // 第一段 now - epoch 为该算法目前已经奔跑了xxx毫秒 // 如果在程序跑了一段时间修改了epoch这个值 可能会导致生成相同的ID //int64((now - epoch) << timeShift |w.datacenterId << 17 | (w.workerId << 12) | w.number) ID := int64((now-epoch)<<timeShift | (w.workerId << workerShift) | (w.number)) return ID } func main() { worker, err := NewWorker(1) if err != nil { fmt.Println(err) return } for i := 0; i < 10000; i++ { id := worker.GetId() fmt.Println(id) } }
C# 实现:
public class IdWorker { //机器ID private static long workerId; private static long twepoch = 687888001020L; //唯一时间,这是一个避免重复的随机量,自行设定不要大于当前时间戳 private static long sequence = 0L; private static int workerIdBits = 4; //机器码字节数。4个字节用来保存机器码(定义为Long类型会出现,最大偏移64位,所以左移64位没有意义) public static long maxWorkerId = -1L ^ -1L << workerIdBits; //最大机器ID private static int sequenceBits = 10; //计数器字节数,10个字节用来保存计数码 private static int workerIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数 private static int timestampLeftShift = sequenceBits + workerIdBits; //时间戳左移动位数就是机器码和计数器总字节数 public static long sequenceMask = -1L ^ -1L << sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微妙在进行生成 private long lastTimestamp = -1L; /// <summary> /// 机器码 /// </summary> /// <param name="workerId"></param> public IdWorker(long workerId) { if (workerId > maxWorkerId || workerId < 0){ throw new Exception(string.Format("worker Id can't be greater than {0} or less than 0 ", workerId)); } IdWorker.workerId = workerId; } public long nextId() { lock (this) { long timestamp = timeGen(); if (this.lastTimestamp == timestamp) { //同一微妙中生成ID IdWorker.sequence = (IdWorker.sequence + 1) & IdWorker.sequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限 if (IdWorker.sequence == 0) { //一微妙内产生的ID计数已达上限,等待下一微妙 timestamp = tillNextMillis(this.lastTimestamp); } } else { //不同微秒生成ID IdWorker.sequence = 0; //计数清0 } if (timestamp < lastTimestamp) { //如果当前时间戳比上一次生成ID时时间戳还小,抛出异常,因为不能保证现在生成的ID之前没有生成过 throw new Exception(string.Format("Clock moved backwards. Refusing to generate id for {0} milliseconds", this.lastTimestamp - timestamp)); } this.lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳 long nextId = (timestamp - twepoch << timestampLeftShift) | IdWorker.workerId << IdWorker.workerIdShift | IdWorker.sequence; return nextId; } } /// <summary> /// 获取下一微秒时间戳 /// </summary> /// <param name="lastTimestamp"></param> /// <returns></returns> private long tillNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /// <summary> /// 生成当前时间戳 /// </summary> /// <returns></returns> private long timeGen() { return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds; } } class Program { static void Main(string[] args) { IdWorker idworker = new IdWorker(1); for (int i = 0; i < 1000; i++) { Console.WriteLine(idworker.nextId()); } } }