以前在python环境下selenium 主要用的是chromdriver,这次发现老是报错(Timeout), 实际又是正确的, 可能是和chrome版本不正确,再加上我程序蹦来就在windows环境下。
IE浏览器驱动下载链接:http://selenium-release.storage.googleapis.com/index.html,我这里安装的是v3.0(担心最新的有问题),运行代码发现成功。
Firefox 浏览器下载链接:https://github.com/mozilla/geckodriver/releases/, 我这里安装的是
geckodriver-v0.24.0-win64.zip ,Firefox 是最新的68.0
如果是在linux(ubuntu)下, 首先下载文件,然后切换到下载目录 执行以下语句:
tar -xvzf geckodriver* chmod +x geckodriver sudo mv geckodriver /usr/local/bin/
可以参考 https://blog.csdn.net/qq_23926575/article/details/77268924
把下载文件放在python的安装目录的Scripts下比较方便(这样就可以不用指定路径了)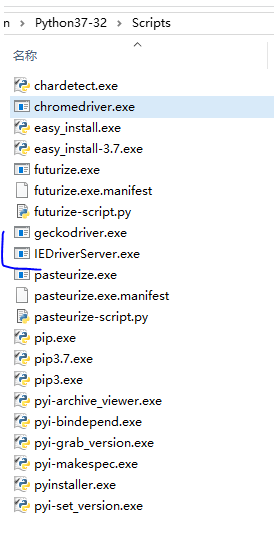
我们在爬网的时候经常需要用到requests(发送http请求)和BeautifulSoup 分析网页的返回内容
csdn:
from selenium import webdriver from selenium.webdriver.firefox.options import Options from selenium.common.exceptions import TimeoutException import requests from bs4 import BeautifulSoup import time opts = Options() #opts.headless =True opts.add_argument("--headless") #br = webdriver.Ie(r'D:/python/IEDriverServer.exe') url="https://blog.csdn.net/xxx/article/list/" for i in range(60): try: #br = webdriver.Firefox(firefox_options=opts) br = webdriver.Firefox(options=opts) #br = webdriver.Ie(r'D:/python/IEDriverServer.exe') r = requests.get(url+str(i)) soup = BeautifulSoup(r.text,"lxml") s= soup.find_all("div",class_ ="article-item-box csdn-tracking-statistics") for item in s: temp=item.h4.a.get("href") if temp.startswith("https://blog.csdn.net/xxx"): try: print(temp) br.get(temp) time.sleep(60) except TimeoutException: br.execute_script("window.stop()") except Exception as et: print("Error detail:",et) except Exception as e: print("Error:",e) finally: br.quit()
cnblogs:
from selenium import webdriver from selenium.webdriver.firefox.options import Options from selenium.common.exceptions import TimeoutException import requests from bs4 import BeautifulSoup import time opts = Options() opts.add_argument("--headless") url="https://www.cnblogs.com/xxx/default.html?page=" for i in range(9): try: #br = webdriver.Firefox(firefox_options=opts) br = webdriver.Firefox(options=opts) r = requests.get(url+str(i)) soup = BeautifulSoup(r.text,"lxml") soup = soup.find(id='content') s= soup.find_all("h2") for item in s: temp=item.a.get("href") if temp.startswith("https://www.cnblogs.com/xxx/"): try: print(temp) br.get(temp) time.sleep(60) except TimeoutException: br.execute_script("window.stop()") except Exception as et: print("Error detail:",et) except Exception as e: print("Error:",e) finally: br.quit()
然后运行 pyinstaller -F xxx.py来打包成exe文件
在windows用如下语句
opts.headless =True
br = webdriver.Firefox(options=opts)
在ubuntu需要改为
opts.add_argument("--headless")
br = webdriver.Firefox(firefox_options=opts)
如果windows下会有如下提示:
![]()

但是在处理https的时候需要注意了:
调用IE来打开对应的网页问题,但是在实际测试中,有些网站是采用https协议的,这时候IE浏览器会弹出如下窗口,一般手动选择后,才可进入登录界面,而在webdriver调用浏览器后,无法继续操作,那么该如何解决呢?
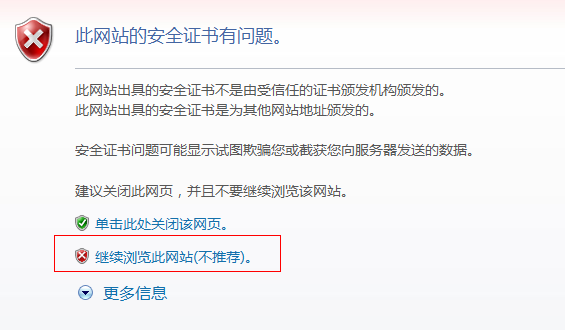
方法一:代码增加配置
首先,我们可以可以查看该网页的源码,分析下代码,可以看到下面部分信息:
<h4 id="continueToSite">
<img src="red_shield.png" ID="ImgOverride" border="0" alt="不推荐图标" class="actionIcon">
<A href='' ID="overridelink" NAME="overridelink" >继续浏览此网站(不推荐)。 </A>
</h4>
述标记部分的,则是上图标记的地方,一般我们点击该图标后即可进入登录窗口,下面代码中通过调用javascript来操作浏览器的提示框,来跳过该提示即可:
#coding=utf-8 from selenium import webdriver driver=webdriver.Ie() firsturl='https://172.172.110.8/Terminal/logon.do' driver.get(firsturl) driver.get("javascript:document.getElementById('overridelink').click();")#解决IE提示问题 driver.close()
方法二:浏览器配置
方法二则是通过配置浏览器的方法,解决证书问题,方法如下:
1、点击【继续浏览此网页】后进入登录窗口,此时地址栏后面会出现【证书错误】提示
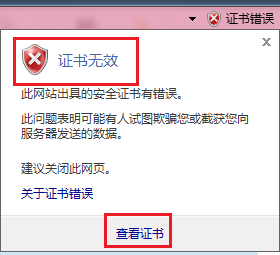
2、点击证书错误——查看证书,提示证书无效,则是因为证书不被信息,需要安装证书
3、弹出证书界面,选择安装证书
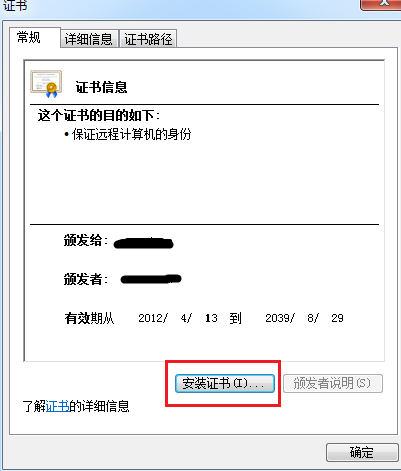
4、按向导操作,注意在下列步骤中需要选择证书位置
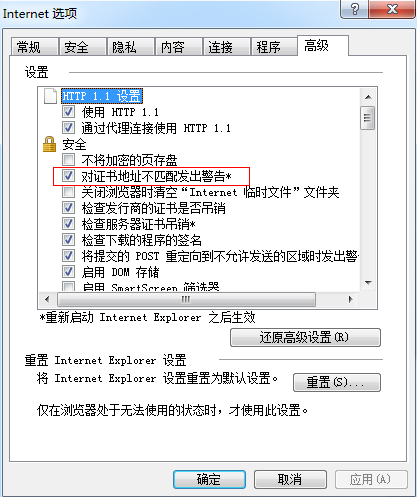
5、配置完成后,此时依然是无法登陆的,点击继续浏览后,弹出的错误提示为:不匹配的地址,如下,还需要继续配置
6、Internnet选项——高级下,去除下图中标记项的勾,然后保存
7、重新打开地址,此时仍然会弹出提示,选择继续浏览后,会发现上方的地址栏变为一个小锁,如右图,说明已经配置OK,后续在打开该地址就不会弹出错误选项了。

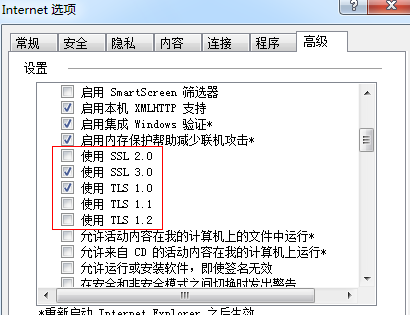
8、若还是无法登陆,可以在Internet选项—安全中:设置安全等级为低等级,并在高级选项下,将下属五项全部勾选后重启浏览器即可
关于调用IE浏览器的错误处理
运行过程中如果出现错误:WebDriverException: Message: u'Unexpected error launching Internet Explorer. Protected Mode settings are not the same for all zones. Enable Protected Mode must be set to the same value (enabled or disabled) for all zones.
解决方法
更改IE的internet选项->安全,将Internet/本地Internet/受信任的站定/受限制的站点中的启用保护模式全部去掉勾,或者全部勾上