摘要
我们提出了一个概念上简单、灵活和通用的对象实例分割框架。我们的方法高效地检测图像中的目标,同时为每个实例生成高质量的分割掩码。这种称为Mask R-CNN的方法通过添加一个用于预测目标掩码的分支来扩展Faster R-CNN,该分支与现有的用于边框识别的分支并行。Mask R-CNN训练简单,只在Faster R-CNN上增加一个小的开销,运行速度为5fps。此外,Mask R-CNN很容易泛化到其它任务,例如,允许我们在同一框架中估计人体姿势。我们在COCO挑战“套件”全部三个“轨道”中展示了最佳结果,包括实例分割,边框目标检测和人员关键点检测。无需任何技巧,Mask R-CNN在每个任务中胜过所有现有的单模型条目,包括COCO 2016挑战的获胜者。我们希望该简单有效的方法将成为一个坚实的基线,并有助于简化未来在实例级识别方面的研究。代码将可用。
1. 介绍
视觉社区在一段时间内迅速改进了目标检测和语义分割结果。在很大程度上,这些进步是由强大的基线系统驱动的,例如分别用于目标检测和语义分割的Fast/Faster R-CNN[9, 29]和全卷积网络(FCN)【24】框架。这些方法在概念上是直观的,并提供灵活性和稳健性,以及快速的训练和推理时间。我们在这项工作中的目标是为实例分割开发一个可比较的支持框架。
实例分割具有挑战性,因为它需要正确检测图像中的所有对象,同时也精确地分割每个实例。因此,它结合了来自目标检测的经典计算机视觉任务的元素,其目标是对各个目标进行分类并使用边界框对每个目标进行定位,以及语义分割,其目标是将每个像素分类为固定的一组类别而不区分的目标实例。鉴于此,人们可能期望需要一种复杂的方法来获得良好的结果。然而,我们表明,一个令人惊讶的简单,灵活,快速的系统可以超越先前的先进实例分割结果。
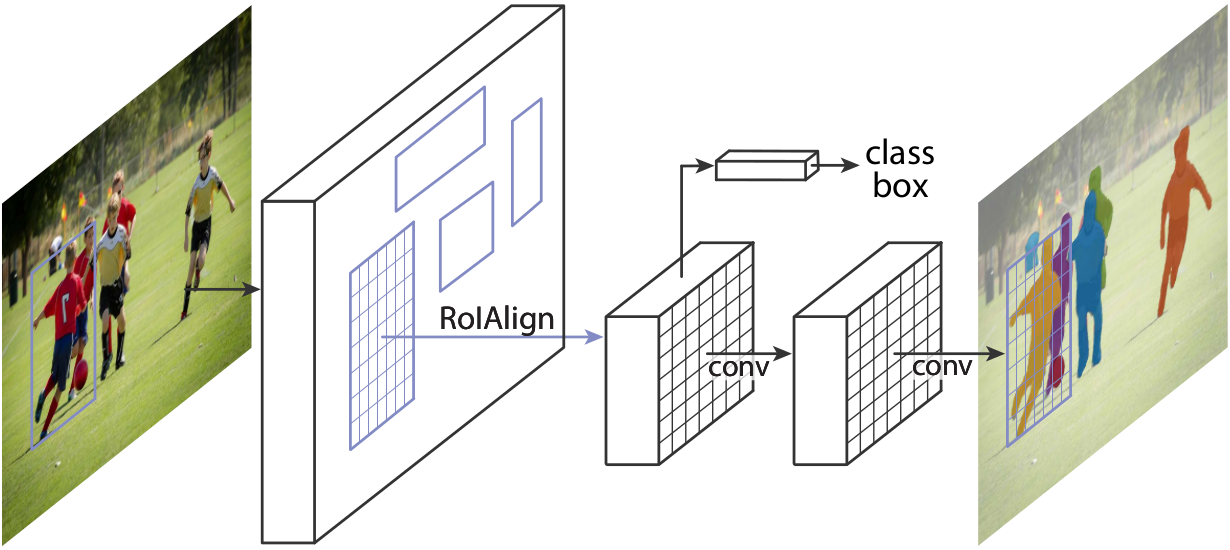
图1:用于实例分割的Mask R-CNN框架。
我们的方法称为Mask R-CNN,通过在每个感兴趣区域(ROI)上添加一个分支来预测分割掩码,并与现有分支进行分类和边界框回归并行,从而扩展Faster R-CNN(图1)。掩码分支是应用于每个RoI的小FCN,以像素到像素的方式预测分割掩码。在给定R-CNN框架的情况下,Mask R-CNN很容易实现和训练,这有助于广泛的灵活架构设计。另外,掩码分支只会增加一个小的计算开销,从而实现快速系统和快速实验。
原则上,Mask R-CNN是Faster R-CNN的直观扩展,但正确构建掩码分支对于获得良好的结果至关重要。最重要的是,Faster R-CNN并非设计用于网络输入和输出之间的像素到像素对齐。这一点在RoIPool(参与实例的事实上的核心操作)如何为特征提取执行粗略空间量化方面最为明显。为了解决这个错位,我们提出了一个简单的,无量化的层,称为RoIAlign,忠实地保留了精确的空间位置。尽管看似微小的变化,但RoIAlign的影响很大:它将掩码精度提高了10%和50%,在更严格的定位衡量下显示处更大的收益。其次,我们发现分离掩码和类预测是必不可少的:我们独立地预测每个类的二元掩码,没有类之间的竞争,并依赖于网络的RoI分类分支来预测类别。相比之下,FCN通常执行逐像素多类别分类,其结合分割和分类,并且基于我们的实例分割实验效果不佳。
在没有花里胡哨的情况下,Mask R-CNN超越了COCO实例分割任务的所有先前的最先进single-model结果,包括来自2016年比赛获胜者的精心设计的参赛作品。作为副产品,我们的方法也擅长COCO目标检测任务。在消融实验中,我们评估了多个基本实例,这使我们能够证明其稳健性和分析核心因素的影响。
我们的模型可以在GPU上以每帧大约200ms的速度运行,而COCO上的训练在每个8-GPU机器上需要一到两天。我们相信快速训练和测试速度以及框架的灵活性和准确性将有利于并简化未来对实例分割的研究。
最后,我们通过对COCO关键点数据集的人体姿态估计的任务展示了我们框架的通用性。通过将每个关键点视为one-hot二元掩码,通过最小的修改,可以应用Mask R-CNN来检测特定于实例的姿势。没有技巧,Mask R-CNN超越了2016年COCO关键点竞赛的冠军,同时以5fps的速度运行。因此,Mask R-CNN可以更广泛地被视为用于实例级识别的灵活框架,并且可以容易地扩展到更复杂的任务。
我们将发布代码以促进未来的研究。
2. 相关工作
R-CNN:基于区域的CNN(R-CNN)边框目标检测方法关注可管理数量的目标区域,并在每个RoI上独立地求卷积网络的值。R-CNN被扩展到允许在特征图的RoI上使用RoIPool,从而实现更快的速度和更高的准确性。Faster R-CNN通过使用区域建议网络(RPN)学习注意机制来推进这个发展。Faster R-CNN对于许多后续改进而言是灵活且稳健的,并且是几个基准测试中的当前领先框架。
Instance Segmentation:在R-CNN的有效性推动下,许多实例分割方法都基于分割提议。早期的方法采用自下而上的分割【33,2】。DeepMask【27】及其后续工作【28,5】学习提出分割候选,然后由Fast R-CNN分类。在这些方法中,分割先于识别,这是缓慢且不太准确的。同样,Dai等人【7】提出了一个复杂的多阶段级联,它可以从边界框提议中预测分割提议,然后进行分类。相反,我们的方法基于掩码和类标签的并行预测,这更简单,更灵活。
最近,Lei等人将【5】中的分割建议系统和【8】中的目标检测系统结合起来,用于“全卷积实例分割”(FCIS)。【5,8,21】中的常见想法是全卷积地预测一组位置敏感的输出通道。这些通道同时处理目标类,框和掩码,使系统快速。但FCIS在重叠实例上表现出系统误差并产生虚假边缘(图5),表明它受到分割实例的基本困难的挑战。

图2:在COCO测试集上的Mask R-CNN结果。结果基于ResNet-101,实现了35.7的掩码AP并且运行速度为5fps。掩码用彩色表示,边框、类别、置信度也做了相应的展示。
3. Mask R-CNN
Mask R-CNN在概念上很简单:Faster R-CNN为每个候选对象提出两个输出,一个类标签和一个边框偏移;为此,我们添加了第三个输出掩码的分支。因此,Mask R-CNN是一种自然而直观的想法。但是额外的掩码输出与类和框输出不同,需要提取对象的更精细的空间布局。接下来,我们介绍Mask R-CNN的关键元素,包括像素到像素的对齐,这是Fast/Faster R-CNN的主要缺失部分。
Faster R-CNN:我们首先简要回顾一下Faster R-CNN检测器【29】。Faster R-CNN包括两个阶段。第一阶段称为区域建议网络(RPN),提出候选对象边框。第二阶段,实质上是Fast R-CNN,从每个候选框中使用RoIPool提取特征,并执行分类和边界框回归。可以共享两个阶段使用的特征,以便更快地推理。我们向读者推荐【17】,以便在Faster R-CNN和其他框架之间进行最新,全面的比较。
Mask R-CNN:Mask R-CNN采用相同的两阶段步骤,具有相同的第一阶段(即RPN)。在第二阶段,与预测类和框偏移并行,Mask R-CNN还为每个RoI输出一个二元掩码。这与最近的系统形成对比,它们的分类取决于掩码预测(例如【27,7,21】)。我们的方法遵循Fast R-CNN【9】的精神,并行地应用了边界框分类和回归(结果很大程度上简化了原始R-CNN的多阶段流水线【10】)。
形式上,在训练期间,我们将每个采样RoI的多任务损失定义为$L=L_{cls}+L_{box}+L_{mask}$。分类损失$L_{cls}$和边界框$L_{box}$与【9】中的定义一致。掩码分支对于每个RoI具有$km^{2}$维输出,其编码分辨率为$m$x$m$的$K$个二元掩码,分别对应$K$个类。为此我们为每个像素应用sigmoid,并将$L_{mask}$定义为平均二元交叉熵损失。对于与真值类$k$相关联的RoI,$L_{mask}$仅在第$k$个掩码上定义(其它掩码输出不会导致损失)。
我们对$L_{mask}$的定义允许网络为每个类生成掩码,而不需要在类之间进行竞争;我们依靠专用的分类分支来预测用于选择输出掩码的类标签。这解耦了掩码和类预测。这与将FCN【24】应用于语义分割时的常规做法不同,后者通常使用每像素softmax和多项交叉熵损失。在这种情况下,各类的掩码竞争;在我们的例子中,有它们没有的每像素sigmoid和二元损失。我们通过实验表明,该公式是良好实例分割结果的关键。
Mask Representation:掩码对输入目标的空间布局进行编码。因此,与不可避免地通过全连接(fc)层折叠成短输出向量的类标签或框偏移不同,提取掩码的空间结构可以通过由卷积提供的像素到像素的对应自然地解决。
具体来说,我们使用FCN为每个RoI预测一个$m$x$m$的掩码。这允许掩码分支中的每个图层保持明确地的$m$x$m$的对象空间布局,而不会将其折叠为缺少空间维度的向量表示。与先前使用fc层进行掩码预测的方法不同,我们的全卷积表示需要更少的参数,并且如实验所示更准确。
这种像素到像素的行为要求我们的RoI特征(它们本身就是小特征映射)能够很好地对齐,以忠实地保持明确的每个像素的空间对应关系。这促使我们开发以下RoIAlign层,该层在掩码预测中起关键作用。
RoIAlign:RoIPool【9】是用于从每个RoI中提取小特征图(例如$7$x$7$)的标准操作。RoIPool首先将浮点数的RoI量化为特征图的离散粒度,然后将该量化的RoI细分为自身量化的空间块,最后聚合每个块覆盖的特征值(通常通过最大池化)。例如,通过计算$[x/16]$在连续坐标上执行量化,其中16是特征图步幅并且[·]是舍入;同样,当分成块(例如,$7$x$7$)时执行量化。这些量化引起RoI和提取的特征之间的不对齐。虽然这可能不会影响分类,这对小的平移很鲁棒,但它对预测像素级精确的掩码有很大的负面影响。
为了解决这个问题,我们提出一个$RoIAlign$层来消除RoIPool的苛刻量化,正确地将提取的特征与输入对齐。我们提出的改变很简单:我们避免对RoI边界或块的任何量化(例如,我们使用$x/16$而不是$[x/16]$)。我们使用双线性插值【18】来计算每个RoI块中四个常规采样位置的输入特征的准确值,并汇总结果(使用最大值或平均值)。
我们在4.2中展示了RoIAlign带来的巨大改进。我们还比较了【7】中提出的RoIWarp操作。与RoIAlign不同,RoIWarp忽略了对齐问题,并在【7】实现了像RoIPool一样的量化RoI。因此,即使RoIWarp也采用【18】推动的双线性重采样,它的性能与RoIPool依旧相当,如实验所示(表2c中的更多细节),证明了对齐的关键作用。
Network Architecture:为了证明我们方法的通用性,我们将Mask R-CNN与多种框架建立联系。为清楚起见,我们这样区分:(i)用于整个图像上的特征提取为卷积$backbone$架构,(ii)用于边界框识别(分类和回归)的网络为$head$和单独应用于每个RoI的掩码预测。
我们使用命名法$network-depth-features$来表示$backbone$架构。我们评估深度为50或101层的ResNet【15】和ResNeXt【35】。带有ResNets【15】的Faster R-CNN的原始实现从我们称为C4的第4阶段的最终卷积层中提取了特征。例如,ResNet-50的这个backbone用ResNet-50-C4表示。这是【15,7,17,31】中通用的选择 。我们还探索了Lin等【22】最近提出的另一个更有效的backbone,称为特征金字塔(FPN)。FPN使用具有横向连接的自上而下架构,从单一尺度输入构建网内特征金字塔。具有FPN backbone的Faster R-CNN根据其尺度从特征金字塔的不同级别提取RoI特征,但是方法其余类似于vanilla ResNet。使用ResNet-FPN backbone用于特征提取的Mask R-CNN在精度和速度方面获得极佳的提升。更多关于FPN的细节,请参阅【22】。
对于网络$head$我们密切关注先前工作中提出的架构,我们在其中添加一个全卷积掩码预测分支。具体地说,我们从ResNet【15】和FPN【22】论文中扩展了Faster R-CNN box heads。Figure 3展示了细节。ResNet-C4 backbone的head包括了ResNet第5阶段(即9层‘res5’【15】),这是计算密集型。对于FPN,backbone已经包含res5,因此允许使用更少滤波器的更高效的head。
我们注意到我们的掩码分支有一个简单的结构。更复杂的设计有可能改善性能,但这不是这项工作的重点。
3.1 实现细节
我们根据现有的Fast/Faster R-CNN工作【9,29,22】设置超参数。虽然这些决策在原始论文【9,29,22】中是用于目标检测,但是我们发现我们的实例分割系统对他们是鲁棒的。
Training:如在Fast R-CNN中,如果RoI和真值框的IoU至少为0.5时被视为正,否则为负。掩码损失$L_{mask}$仅限于正的RoIs。掩码目标是RoI和其相关真值掩码之间的交集。
我们采用以图像为中心的训练方法【9】。调整图像大小以使其比例(最短的边)是800像素【22】。每个小批量中采用每个GPU上2个图像,每个图像有$N$个采样RoI,正负比为1:3【9】。C4的backbone(如【9,29】所示)的$N$是64,FPN的是512(如【22】所示)。我们在8个GPU(有效的小批量大小为16)上进行160k次迭代,学习率为0.02,在120k次迭代时减少10倍。我们使用0.0001的权重衰减和0.9的动量。
和【22】一样,RPN锚点跨越5个尺度和3个纵横比。为了方便消融,RPN单独训练并且不与Mask R-CNN共享特征,除非另有说明。对于本文中的每个entry,RPN和Mask R-CNN有同样的backbones,因此他们是可共享的。

图3:Head Architecture:扩展两个现有的Faster R-CNN头部。左/右两图分别展示了ResNet C4和FPN的头部,在哪加上一个掩码分支。数字表示空间分辨率和通道数。箭头表示卷积、反卷积或者全连接,这个可以通过上下文推断出来(卷积保持空间维度,而反卷积增加)。所有的卷积是都3×3,除了输出卷积是1×1,反卷积是步长为2的2×2操作,在隐藏层使用ReLU。左:'res5'表示ResNet的第5阶段,为了简单才这么选择的以便于在7×7的RoI上使用步长为1首次卷积。右:'×4'表示四个连续的卷积堆。
Inference:在测试时,C4 backbone建议的数量是300(和【29】一样),FPN为1000(和【22】一样)。我们在这些提议上运行框预测分支,然后是非极大值抑制【11】。然后将掩码分支应用于最高得分100个检测框。虽然这与训练中的并行计算不同,但它加速了推理并提高了准确率(由于使用了更少更准确的RoIs)。掩码分支可以为每个RoI预测$K$个掩码,但是我们仅使用第$k$个掩码,其中$k$是分类分支的预测类。然后将$mxm$浮点数掩码输出调整为RoI尺寸,并在阈值0.5出进行二值化。
请注意,由于我们仅计算前100个检测框,因此Mask R-CNN在它的Faster R-CNN对应部分添加一点小开销(例如,在典型模型上约为 20%)。
4. 实验:实例分割
我们将Mask R-CNN与最先进的算法进行彻底的对比,并进行全面的消融实验。我们使用COCO数据集【23】进行所有实验。我们报告标准COCO指标包括AP(平均IoU阈值),AP$_{50}$,AP$_{75}$,和AP$_{S}$,AP$_{M}$,AP$_{L}$(不同尺度的AP)。除非另有说明,否则AP正在用$mask$ IoU进行评估。与之前的工作【3,22】一样,我们使用80k训练集图像和验证集图像(trainval35k)的一个35k子集的联合来训练,并报告对剩余验证集图像(minival)5k子集的消融。我们还在test-dev【23】上报告了结果,该结果没有公开的标签。发布后,我们会按照建议把test-std上的全部结果上传到公共排行榜。

图4:在COCO测试集上使用ResNet-101-FPN的Mask R-CNN的更多结果,并且以5fps运行,35.7的掩码AP(表1)
4.1 主要结果
我们将Mask R-CNN与表1中实例分割的最先进的方法进行比较。我们模型的所有实例都优于先前最先进模型的基线变体。这包括MNC【7】和FCIS【21】,它们分别是COCO 2015和2016分割挑战的获胜者。没有花里胡哨,具有ResNet-101-FPN backbone的Mask R-CNN优于FCIS+++【21】,其中包括多尺度训练/测试,水平翻转测试和在线硬件示例挖掘(OHEM)[30]。虽然超出了这项工作的范围,但我们希望许多此类改进使用于我们。
Mask R-CNN的输出在图2和4中可视化。Mask R-CNN即使在极具挑战性的条件下也能取得良好结果。在图5中,我们比较了Mask R-CNN的基线和FCIS+++【21】。FCIS+++在重叠实例上展示了系统的伪像,表明它受到实例分割基本难度的挑战。Mask R-CNN没有显示这样的伪像。

图5:FCIS+++[21](上)vs. Mask R-CNN(下,ResNet-101-FPN)。FCIS展示了在重叠目标上的系统样本。
4.2 消融实验
我们提出了许多指控来分析Mask R-CNN。结果显示在表2中并且接下来详细讨论。
Architecture:表2a显示了具有各种backbones的Mask R-CNN。它受益于更深层次的网络(50vs101)和先进的设计,包括FPN和ResNeXt。我们注意到并非所有的框架都自动受益于更深或者先进的网络(参见【17】中的基准测试)。
Multinomial vs. Independent Masks:Mask R-CNN解耦掩码和类别预测:当现有的框分支预测类别标签的时候,我们为每一个类生成掩码而没有类别间的竞争(通过每个像素的sigmoid和binary损失)。在表2b中,我们将其与使用每像素softmax和多项式损失(如FCN【24】中常用)进行比较。该替代方法耦合了掩码和类别预测任务,并导致掩码AP的严重损失(5.5点)。这表明,一旦实例被分类为整体(通过框分支),就可以预测二元掩码而不关心类别,这使得模型更容易训练。
Class-Specific vs. Class-Agostic Masks:我们默认的实例化预测特定类的掩码,即每个类一个$m$x$m$的掩码。有趣的是,具有类别禁止掩码的Mask R-CNN(即,无论类别预测单个$m$x$m$输出)几乎同时有效:它具有29.7掩码AP和ResNet-50-C4上类特定对应物的30.3。这进一步突出了我们方法中的分工,这在很大程度上解耦了分类和分割。
RoIAlign:我们提出的RoIAlign层的评估显示在表2c中。对于本实验我们使用ResNet-50-C4 backbone,它的步长为16。RoIAlign比RoIPool提高了约3点AP,其中大部分增高来自高IoU($AP_{75}$)。RoIAlign对最大/平均池化敏感;我们在论文的其余部分使用平均池化。
此外,我们与MNC【7】中提出的RoIWarp相比较,该方法采用双线性采样。如第3节讨论的,RoIWarp仍然量化RoI,失去与输入对齐。从表2c可以看出,RoIWarp的表型和RoIPool相当并且比RoIAlign差。这突出了对齐是关键。
我们还评估了有ResNet-50-C5 backbone的RoIAlign,它有一个甚至更大的32像素的步长。我们使用了与图3相同的head,因为res5的head不适用。表2d展示了RoIAlign通过大量7.3点改善了掩码$AP$,和通过10.5点改善掩码$AP_{75}$(50%的相关改善)。此外,我们注意到使用RoIAlign,使用$stride-32 C5$特征(30.9$AP$)比使用$stride-16 C4$特征(30.3$AP$,表2c)更准确。RoIAlign在很大程度上使用大步特征进行检测和分割进行长期挑战。
最后,当我们使用FPN的时候,RoIAlign展示了增益为1.5掩码$AP$和0.5框$AP$,其中FPN有更精细的多级步长。对于需要更精细对齐的关键点检测,即使使用FPN,RoIAlign也显示出大的增益(表6)。
Mask Branch:分割是一个像素到像素的任务,并且我们使用FCN来利用掩码的空间布局。在表2e中,我们使用ResNet-50-FPN backbone来比较多层感知器(MLP)和FCNs。使用MLP可提供超过MLP的2.1掩码AP增益。我们注意到,我们选择这个主干以至于FCN head的卷积层没有被预训练,以便和MLP的公平比较。
4.3 边界框检测结果
我们将Mask R-CNN和表3中最先进的COCO $bounding-box$ 目标检测对比。对于此结果,即使训练完整的Mask R-CNN模型,也只在推理中使用分类和框输出(忽略掩码输出)。使用ResNet-101-FPN的Mask R-CNN优于所有先前最先进模型的基本变体,包括GRMI【17】的单模型变体,即COCO 2016检测挑战的获胜者。使用ResNeXt-101-FPN,Mask R-CNN进一步改善了结果,在【31】(使用Inception-ResNet-v2-TDM)的最佳先前单模型条目上有3.0点框$AP$的余量。
作为进一步比较,我们训练一种在表3中用“Faster R-CNN,RoIAlign”表示的没有掩码分支的Mask R-CNN的版本。由于RoIAlign,该模型优于【22】提出的模型。另一方面,它比Mask R-CNN低0.9点框$AP$。因此,Mask R-CNN在框检测上的这种差距仅仅取决于多任务训练的好处。
最后,我们注意到Mask R-CNN在它的掩码和框$AP$之间获得小的差距:例如,37.1(掩码,表1)和39.8(框,表3)之间的2.7点。这表明我们的方法在很大程度上减少了目标检测和更具挑战的实例分割任务之间的差距。
4.4 定时
Inference:我们训练了ResNet-101-FPN模型,该模型在Faster R-CNN的4步训练后共享RPN和Mask R-CNN阶段之间的特征【29】。该模型在NVIDIA Tesla M40 GPU上以每个图像195ms的速度运行(加上15ms的CPU时间,将输出调整为原始分辨率),并统计上获得与非共享掩码$AP$相同的掩码$AP$。我们还报告说ResNet-101-C4变体需要约400ms,因为它有一个更重的框head(图3,),因此我们不建议在实践中使用C4变体。
虽然Mask R-CNN很快,但是我们注意到我们的设计没有针对速度优化,并且可以实现更好地速度/准确率的平衡【17】,例如,通过改变各种图像尺寸和提议数量,那个超出了本文的范围。
Training:Mask R-CNN训练得也快。在COCO trainval35k上使用ResNet-50-FPN进行8-GPU同步训练需要32小时(每16张图像小批量0.72秒),使用ResNet-101-FPN需要44小时。事实上,当在训练集上训练时,快速原型制作可以在不到一天的时间内完成。我们希望这样快速的训练将消除这个领域内的主要障碍,并且鼓励更多的人对这个具有挑战行的话题上进行研究。
5. 用于人体姿态估计的Mask R-CNN
我们的框架可以容易地扩展到人体姿态估计。我们将关键点的位置建模为one-hot掩码,并且采用Mask R-CNN来预测$K$个掩码,每个$K$关键点类型都有一个(例如,左肩,右肘)。这个任务帮助证明了Mask R-CNN的灵活性。
我们注意到我们系统利用了人体姿态估计的最小领域知识,因为实验主要证明了Mask R-CNN框架的泛化性。我们期望领域知识将与我们的简单方法互补,但它超出了本文的范围。
Implementation Details:当我们对关键点调整时,对分割系统记性微小的修改。每个实例的$K$个关键点的每一个,训练目标是一个one-hot的$m$x$m$的二元掩码,其中仅仅将一个单像素标记为前景。在训练期间,对于每一个可见真值关键点,我们最小化$s^{2}-way$ softmax输出(它鼓励单点检测)上的cross-entropy损失。我们注意到,在实例分割中,$K$个关键点仍要独立对待。
我们采用ResNet-FPN,并且关键点head架构是与图3(right)中相似。关键点head由一堆八个3x3 512-d卷积层组成,其后是deconv层和2x双线性方法,产生了56x56的输出分辨率。我们发现关键点级定位精度需要相对较高的分辨率输出。
模型在所有包含注释关键点的COCO trainval35k的图像上训练。为了减少过拟合,因为训练集是更小的,我们用从[640, 800]像素上随机采样的图像比例训练模型;推理是在800像素的单尺度上。我们训练90k次迭代,从0.02学习率开始并且在60k和80k次迭代时减少10。我们使用边界框非极大值抑制,阈值为0.5。其它实现和3.1节一样。
Experiments on Human Pose Estimation:我们使用ResNet-50-FPN评估人员关键点$AP(AP^{kp})$。我们已经对ResNet-101进行了实验,并且发现它实现了相似的结果,可能是因为更深的模型受益于更多的训练数据,但是这个数据集相对较小。
表4显示我们的结果(62.7$AP^{kp}$)比用多阶段处理管道的COCO 2016关键点检测的获胜者【4】高出0.9分(参见表4的标题)。我们的方法更简单,更快捷。
更重要的是,我们有一个统一的模型,可以同时预测框,分割和关键点,同时运行速度为5fps。添加分割分支(针对人员类别)可以将test-dev上的$AP^{kp}$改善为63.1(表4)。表5列出了在minival上多任务学习的更多摘要。添加掩码分支到box-only(例如,Faster R-CNN)或keypoint-only版本上可以一贯地改善这些任务。但是,添加关键点分支会略微减少框/掩码$AP$,这表明虽然关键点检测可以从多任务训练中受益,但是它不会反过来帮助其它任务。然而,共同学习三个任务能使一个统一的系统可以同时有效地预测所有输出(图6)。
我们还研究了关键点检测上RoIAlign的影响(表6)。虽然这个ResNet-50-FPN backbone有更精细的步长(例如,最精细的4个像素),RoIAlign仍然比RoIPool有显著改进,并且增加了4.4点$AP^{kp}$。这是因为关键点检测比定位精度更敏感。这再次表明对齐对于像素级定位是至关重要的,包括掩码和关键点。
鉴于Mask R-CNN用于提取目标边界框,掩码和关键点的有效性,我们期望它是其它实例级任务的有效框架。
References
【1】M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2D human pose estimation: New benchmark and state of the art analysis. In CVPR, 2014.
【2】P. Arbelaez, J. Pont-Tuset, J. T. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping. In CVPR, 2014.
【3】S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016.
【4】Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In CVPR, 2017.
【5】J. Dai, K. He, Y. Li, S. Ren, and J. Sun. Instance-sensitive fully convolutional networks. In ECCV, 2016.
【6】J. Dai, K. He, and J. Sun. Convolutional feature masking for joint object and stuff segmentation. In CVPR, 2015.
【7】J. Dai, K. He, and J. Sun. Instance-aware semantic segmentation via multi-task network cascades. In CVPR, 2016.
【8】J. Dai, Y.Li, K. He, and J. Sun. R-FCN: Object detection via region-based fully convolutional networks. In NIPS, 2016.
【9】R. Girshick. Fast R-CNN. In ICCV, 2015.
【10】R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
【11】R. Girshick, F. Iandola, T. Darrell, and J. Malik. Deformable part models are convolutioanl neural networks. In CVPR, 2015.
【12】B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. Simultaneous detection and segmentation. In ECCV. 2014.
【13】B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. Hyper-columns for object segmentation and fine-grained localization. In CVPR, 2015.
【14】K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
【15】K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
【16】J. Hosang, R. Benenson, R. Dollar, and B. Schiele. What makes for effective detection proposals? PAMI, 2015.
【17】J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017.
【18】M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015.
【19】A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
【20】Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackerl. Backpropagation applied to handwrittern zip code recognition. Neural computation, 1989.
【21】Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei. Fully convolutional instance-aware semantic segmentation. In CVPR, 2017.
【22】T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
【23】T.-Y Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014.
【24】J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation, In CVPR, 2015.
【25】V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010.
【26】G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tompson, C. Bregler, and K. Murphy. Towards accurate multi-person pose estimation in the wild. In CVPR, 2017.
【27】P. O. Pinheiro, R. Collobert, and P. Dollar. Learning to segment object candidates. In NIPS, 2015.
【28】P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dollar. Learning to refine object segments. In ECCV, 2016.
【29】S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
【30】A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online har d example mining. In CVPR, 2016.
【31】A. Shrivastava, R. Sukthankar, J. Malik, and Gupta. Beyond skip connections: Top-down modulation for object detection. arXiv:1612.06851, 2016.
【32】C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. In ICLR Workshow, 2016.
【33】J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013.
【34】S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh. Convolutional pose machines. In CVPR, 2016.
【35】S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017.