不同语言解析PDF内容都有各自的库,比如Java的pdfbox,.net的itextsharp。
c#解析PDF文本,关键代码可参考:
http://www.cnblogs.com/mahongbiao/p/7652788.html
此外也可使用OCR,关键代码可参考:
http://www.cnblogs.com/mahongbiao/p/3760867.html
这些类库解析PDF文本有一个弊端,就是可配置性不强,它们多数是用于PDF文件生成的,对于PDF文本内容的提取仅提供一两个函数供调用。
解析PDF文本,可使用xpdf,该工具为一命令行工具,因此可通过java或.net调用命令行执行。
c#调用示例代码:
1 Process p = new Process(); 2 p.StartInfo.FileName = @"pdftotext.exe"; 3 p.StartInfo.UseShellExecute = false; 4 p.StartInfo.RedirectStandardInput = true; 5 p.StartInfo.RedirectStandardOutput = true; 6 p.StartInfo.RedirectStandardError = true; 7 p.StartInfo.CreateNoWindow = true; 8 p.Start(); 9 p.StandardInput.WriteLine("test.pdf test.txt"); 10 p.StandardInput.AutoFlush = true; 11 p.WaitForExit(); 12 p.Close();
在使用itextsharp或者pdfbox解析某PDF文件时,文本内容以竖排的形式输出,不易解析信息。
而使用xpdf,则可以指定-layout参数,将其按照页面显示的布局方式输出。
下图为PDF样式:
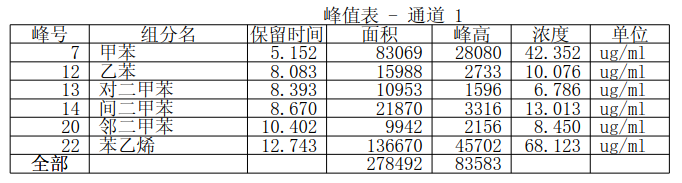
下图为pdfBox、itextsharp解析出的内容样式:

下图为xpdf设置了layout后的解析样式:

可以看出,使用xpdf解析出的内容较容易识别出有意义的数据项。
例子中的中文没有解析出来,可通过配置PDF中文字体解决,xpdf的另一个强项功能,就是它支持配置pdf字体,有些PDF内容通过itextsharp解析不出来的情况下,使用xpdf在配置了正确字体后可以解析出内容。