本文仅用于学习和交流,不具有任何商业价值,如有问题,请与我联系,我将即时处理。
近日,《中国统计年鉴2021年》发布,公布了我国2020年的相关人口数据。据了解,去年我国的人口出生率为8.52‰,直接跌破了10‰的整数关口,创下了我国近43年来的新低。同期全国人口自然增长率(出生率-死亡率)仅为1.45‰,同样创下1978年以来的历史新低。为了减缓人口负增长的到来,我国已经在今年正式开放了三胎政策。一对正处在适龄生育阶段的夫妻,如果想生的话,可以再生一个。
要爬的网址:https://weibo.com/1887344341/L2jya3WQs
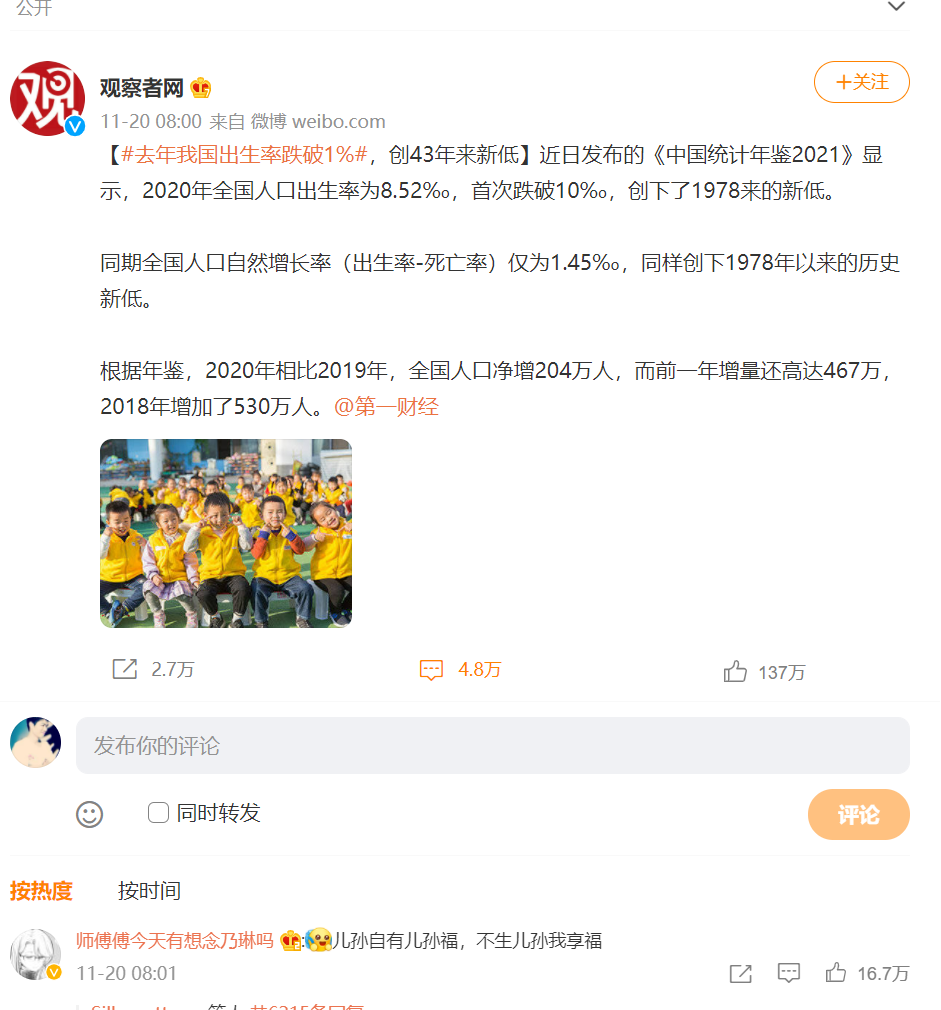
要爬取所有评论,打开开发者工具,定位到评论请求的url。
1 https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&count=10&uid=1887344341&type=feed&maxShowTotal=10 2 https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&max_id=3402343747493173&count=20&uid=1887344341&type=feed&maxShowTotal=10 3 https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&max_id=430913571822089&count=20&uid=1887344341&type=feed&maxShowTotal=10 4 https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&max_id=248394641543629&count=20&uid=1887344341&type=feed&maxShowTotal=10
对比url发现,他们之间只差了个max_id。第一页没有max_id。第一页产生的max_id是供第二页的参数使用的,第二页产生的max_id供第三页的参数,以此类推。。。
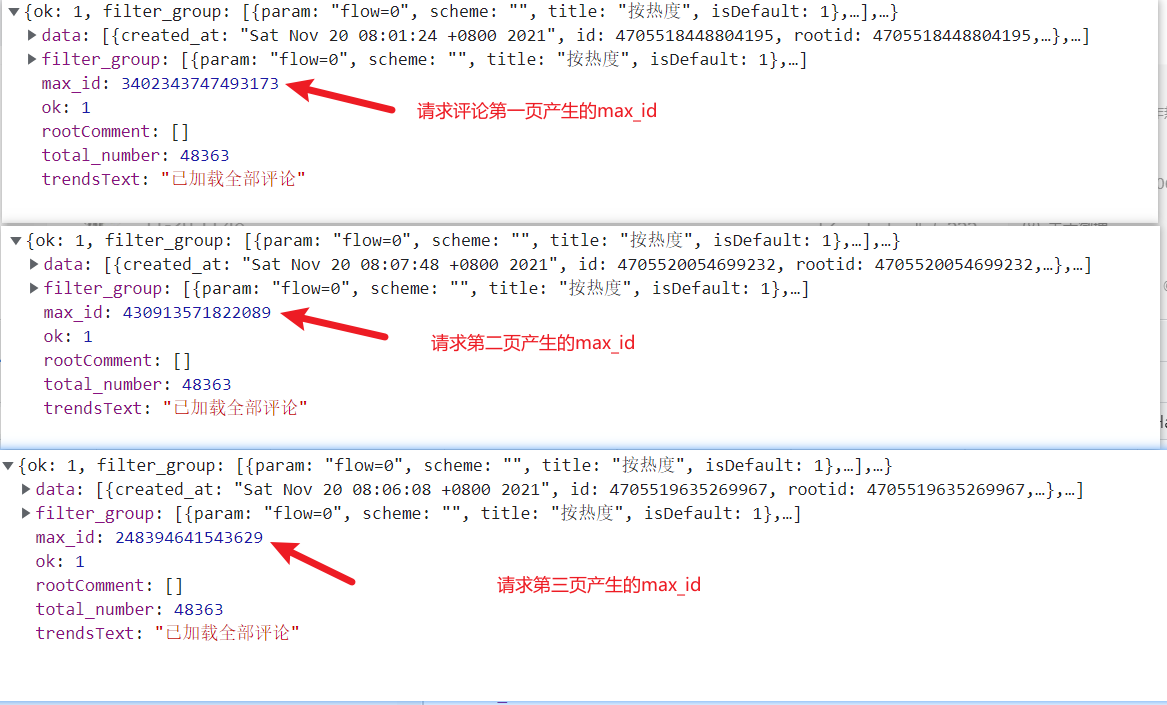
从图中看到,总评论数为48363,每页10条,也就有48364 /10,这里爬多线程爬1000页。
1 """ 2 https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&count=10&uid=1887344341&type=feed&maxShowTotal=10 3 https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&max_id=3402343747493173&count=20&uid=1887344341&type=feed&maxShowTotal=10 4 https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&max_id=430913571822089&count=20&uid=1887344341&type=feed&maxShowTotal=10 5 https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&max_id=248394641543629&count=20&uid=1887344341&type=feed&maxShowTotal=10 6 """ 7 import pprint 8 import random 9 import time 10 import openpyxl as op 11 import requests 12 13 startTime = time.time() # 程序开始时间 14 # 新建一个excel文档 15 wb = op.Workbook() 16 ws = wb.create_sheet(index=0) # 创建一个工作表 17 # 表头 18 ws.cell(row=1, column=1, value='评论者ID') # 第一行第一列,评论者id 19 ws.cell(row=1, column=2, value='评论者名字') # 第一行第二列,评论者名字 20 ws.cell(row=1, column=3, value='评论时间') # 第一行第三列,评论创建时间 21 ws.cell(row=1, column=4, value='评论获赞数') # 第一行第四列,评论获赞数 22 ws.cell(row=1, column=5, value='评论内容') # 第一行第五列,评论内容 23 ws.cell(row=1, column=6, value='评论者位置') # 第一行第六列,评论者所在省市 24 ws.cell(row=1, column=7, value='评论内容带标签') # 第一行第七列,评论内容带html标签,一般是表情的img 25 26 # def checkInfo(): 27 # """ 28 # 判定是否有数据返回,没有就继续请求 29 # :return: 30 # """ 31 # if not response.json()['data']['user']: 32 33 headers = { 34 "cookie": "SCF=AnKJy3NOK5c-P3XxWYBPzTFGd92WnUEH6LUI_MdzSig0jI3pA3K2kjkM9hZTJ0IITPvhB9z0S6v5zBhymsOiVEM.; SINAGLOBAL=2860911667356.4736.1634270617413; UOR=,,login.sina.com.cn; SUB=_2A25MbV1zDeRhGedJ61oQ8SjNyTyIHXVvrmM7rDV8PUJbkNB-LWvFkW1NVnxxfysRCdawBfR6AaMHW6qlF-dAZKcw; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFCIqm7ZokIkH-v5aWq95ji5NHD95QpS05ReK2ceKz7Ws4Dqcjdi--fiK.7iK.pi--fiKy2iK.Ni--fiKL2i-2p; XSRF-TOKEN=yBO4YQJpwcTtENwqPBhhYOkQ; _s_tentry=weibo.com; Apache=8068250098263.423.1637737323909; ULV=1637737323946:4:3:1:8068250098263.423.1637737323909:1636889723690; WBPSESS=iwgOWzX5ngPbvVwyybpLtabJYNqDLtysUdv2RWzj0AVKPySJ_aVpCAXmkWiTCsG4oWn0sdmqNKI-wNweb7XxNp3p_6P8Y9B3rzq-HcZmtkvyEH15RIS7YTRtPVWf32lVqIRiaPqzLn6upnhuMa9R1A==", 35 "referer": "https://weibo.com/1887344341/L2jya3WQs", 36 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36", 37 "x-xsrf-token": "yBO4YQJpwcTtENwqPBhhYOkQ", 38 } 39 40 url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&count=10&uid=1887344341&type=feed&maxShowTotal=10' 41 42 # # 先爬一页 43 # response = requests.get(url=url, headers=headers) 44 # # print(response.json()) # 直接用json接收 45 # # 提取数据,获取五项内容,评论者id,评论者名称,评论时间,点赞人数和评论内容 46 # commentDatas = response.json()['data'] 47 # # pprint.pprint(commentDatas) 48 # for item in commentDatas: 49 # userId = item['user']['id'] # 评论者id 50 # userName = item['user']['name'] # 评论者名称 51 # timeCreated = item['created_at'] # 评论时间 52 # likes = item['like_counts'] # 获赞数 53 # contentHtml = item['text'] # 评论内容带html标签的 54 # contentText = item['text_raw'] # 评论内容只有字符串的 55 # location = item['user']['location'] # 评论者位置 56 # print(userId, userName, timeCreated, likes, contentText, location, sep="|") 57 # 数据无误,开始多页爬取, 58 page = 1 59 # max_id的参数是从前一页来的,所以先请求第一页,后去到max_id进行循环 60 while page < 30: # 爬1000页 61 # time.sleep(random.uniform(2, 5)) # 随机休眠2-5秒中间的数 62 if page == 1: 63 url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&count=10&uid=1887344341&type=feed&maxShowTotal=10' 64 else: 65 url = f'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4705518100941188&is_show_bulletin=2&is_mix=0&max_id={max_id}&count=20&uid=1887344341&type=feed&maxShowTotal=10' 66 # 开始请求网页,从第一页开始 67 print(f'-----------------要爬取的网址为{url}-------------') 68 if page % 16 == 0: 69 time.sleep(10) 70 response = requests.get(url=url,headers=headers) 71 max_id = response.json()['max_id'] # 每次循环之前都会产生一个max_id,第一页的供第二页使用,第二页的供第三页使用,以此类推 72 print(f'---------第{page}页请求到的--max_id为{max_id},供{page+1}页使用!') 73 # 开始提取数据 74 for item in response.json()['data']: 75 userId = item['user']['id'] # 用户id 76 userName = item['user']['name'] # 用户名 77 commentTime = item['created_at'] # 评论时间 78 likes = item['like_counts'] # 评论获赞数 79 contentHtml = item['text'] # 评论内容带html标签的 80 contentText = item['text_raw'] # 评论内容 81 location = item['user']['location'] # 评论地点 82 print(userId, userName, commentTime, likes, contentText, location, contentHtml, sep = " | ") 83 # 开始写入到文本 84 ws.append([userId, userName, commentTime, likes, contentText, location, contentHtml]) # 将内容追加到文本 85 print(f'---------第{page}页的数据保存成功!---------') 86 time.sleep(1) 87 page += 1 # 循环条件,不然一直在第一页 88 wb.save('微博评论.xlsx') 89 wb.close() # 写完关闭文档 90 endTime = time.time() # 程序结束事件 91 92 print('总共用时:', round((endTime-startTime)/60, 2))
然而并没有什么卵用,因为,评论到达16页以后,就不给数据了。

于是开始想其他的法子,PC端不给,手机端给不给呢?开干。
https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id_type=0 # 第一页 https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id=1185590866447066&max_id_type=0 # 第二页 https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id=314915097989517&max_id_type=0 # 第三页 ...... https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id=4707090586928670&max_id_type=1 # 第17页
通过分析发现,17页的网址变了,它的max_id_type值变了。先爬第一页,看携带哪些参数能获取到值。然后再翻页爬取。从参数发现,这条微博的评论为2423条,那个4万多的应该是下面的耳机评论也计算在内。代码:
1 """ 2 https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id_type=0 # 第一页 3 https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id=1185590866447066&max_id_type=0 # 第二页 4 https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id=314915097989517&max_id_type=0 # 第三页 5 ...... 6 https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id=4707090586928670&max_id_type=1 # 第17页 7 """ 8 import pprint 9 import openpyxl as op 10 import requests 11 import random 12 import time 13 14 # 新建excel文档存储数据 15 wb = op.Workbook() # 工作簿 16 ws = wb.create_sheet(index=0) # 工作簿里的第一个工作表 17 ws.cell(row=1, column=1, value='评论者ID') # 第一行第一列评论者id 18 ws.cell(row=1, column=2, value='评论者昵称') # 第一行第二列评论者昵称 19 ws.cell(row=1, column=3, value='评论时间') # 第一样第三列评论时间 20 ws.cell(row=1, column=4, value='评论获赞数') # 第一样第四列评论获赞数 21 ws.cell(row=1, column=5, value='评论内容') # 第一样第五列评论内容 22 23 # 首先定义参数 24 headers = { 25 "cookie": "SCF=AnKJy3NOK5c-P3XxWYBPzTFGd92WnUEH6LUI_MdzSig02NBwKpa2u00x45GCB3-AOQKJvc_oIAkHIKr7MdST4JE.; SUB=_2A25MbV1zDeRhGedJ61oQ8SjNyTyIHXVvrmM7rDV6PUJbktCOLUfTkW1NVnxxfy_BvTGKBnuuEVnUOYQ8GZaV5mhP; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFCIqm7ZokIkH-v5aWq95ji5NHD95QpS05ReK2ceKz7Ws4Dqcjdi--fiK.7iK.pi--fiKy2iK.Ni--fiKL2i-2p; WEIBOCN_FROM=1110006030; _T_WM=65440405732; MLOGIN=1; XSRF-TOKEN=82f68f; M_WEIBOCN_PARAMS=oid%3D4705518100941188%26luicode%3D20000061%26lfid%3D4705518100941188%26uicode%3D20000061%26fid%3D4705518100941188", 26 "mweibo-pwa": "1", 27 "referer": "https://m.weibo.cn/status/L2jya3WQs?jumpfrom=weibocom", 28 "user-agent": "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Mobile Safari/537.36", 29 # "x-xsrf-token": "82f68f", 30 } 31 32 page = 1 33 while page < 242 + 1: 34 time.sleep(random.uniform(2, 5)) 35 print(f'-------------------------------开始爬取评论的{page}页----------------------------------------\n\n') 36 """ 37 # 在数据分析确定后的情况下,可以这样写。 38 if page == 1: # 评论首页的url 39 url = 'https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id_type=0' 40 elif 1 < page < 17: # 2-16页的url 41 url = f'https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id={max_id}&max_id_type=0' 42 else: # 第17页后的url 43 url = f'https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id={max_id}&max_id_type=1' 44 """ 45 # 在数据分析不确定的时候,也就是可能还有max_id_type变化的情况下,换种写法 46 if page == 1: 47 url = 'https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id_type=0' 48 else: 49 url = f'https://m.weibo.cn/comments/hotflow?id=4705518100941188&mid=4705518100941188&max_id={max_id}&max_id_type={max_id_type}' 50 # 进入循环,请求网页 51 response = requests.get(url=url, headers=headers) 52 # pprint.pprint(response.json()) 53 # 每一页的前一页都会返回max_id和max_id_type,初始为第一页,所以进入循环,先获取第一页的 54 max_id = response.json()['data']['max_id'] # 取到max_id 55 max_id_type = response.json()['data']['max_id_type'] # 看参数变化 56 print(f'---第{page}页取得的max_id为:{max_id} ;max_id_type为:{max_id_type} --开始获取数据!---') 57 # 获取评论数据,需要的数据为,评论者id,评论的昵称,评论时间,评论获赞数,评论内容(text和html),评论者相对位置,粉丝数,粉人数,主页 58 commentData = response.json()['data']['data'] 59 # pprint.pprint(commentData) 60 for item in commentData: 61 userId = item['user']['id'] # 评论者id 62 userName = item['user']['screen_name'] # 评论者昵称 63 commentTime = item['created_at'] # 评论时间 64 likesCount = item['like_count'] # 获赞数量 65 commentText = item['text'] # 评论内容text格式 66 print(userId, userName, commentTime, likesCount, commentText, sep = " | ") 67 print(f'==============第{page}页数据提取完毕==============\n\n') 68 time.sleep(2) 69 page += 1 # 循环条件 70 71 72 wb.save('生育率评论.xlsx') #保存文档 73 wb.close() # 关闭文档
代码运行部分截图:
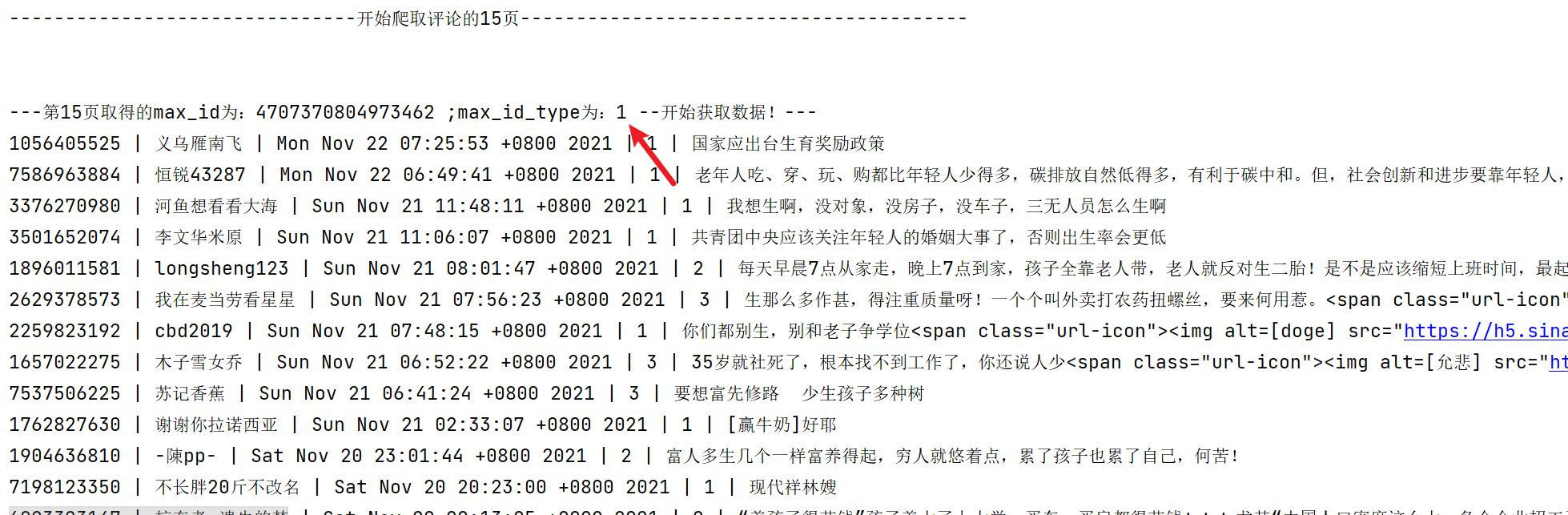
从代码运行结果来看,max_id_type在第15页的时候已经变了。但是这样子爬取的话,为了不给服务器造成太大压力,每次循环都要进行休眠,会浪费很多时间,发现多线程然并卵,就不贴代码了。