本文仅用于学习与交流使用,不具有任何商业价值,如有问题,请与我联系,我会即时处理。---Python逐梦者。
首先是某果TV。
弹幕。以电影《悬崖之上》为例。弹幕数据所在的文件是动态加载的,打开开发者工具,让它加载很多数据,然后搜索某一条数据就看到在哪个包里了,然后就是参数变化不同分析。某果TV的视频播放一分钟它就会更新一个json数据包,里面包含需要的弹幕数据。动手干。
1 import csv 2 import pprint 3 import random 4 import time 5 import requests 6 import pandas as pd 7 8 f = open('悬崖之上.csv', mode='a', encoding='utf-8-sig', newline='') 9 csvWriter = csv.DictWriter(f, fieldnames=[ 10 '用户id', 11 '弹幕内容', 12 '获赞数', 13 ]) 14 csvWriter.writeheader() 15 # 请求头 16 headers = { 17 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36", 18 } 19 # 开始请求并多页爬取 20 for page in range(0, 120 + 1): 21 print(f'=====正在爬取第{page}页数据=====') 22 time.sleep(random.randint(2, 5)) 23 url = f'https://bullet-ali.xxx.com/bullet/2021/11/15/005204/12281642/{page}.json' 24 response = requests.get(url=url, headers=headers) 25 # pprint.pprint(response.json()) 26 # 直接提取需要的,这里提取一下id和内容 27 for i in response.json()['data']['items']: 28 # 首先是id 29 try: 30 id = i['id'] 31 except: 32 id = '未知!' 33 # 其次是内容 34 content = i['content'] 35 # 点赞数 36 try: 37 like = i['v2_up_count'] 38 except: 39 like = '未获得!' 40 41 # # 组织数据 42 # text = pd.DataFrame({'用户id':[id], '弹幕内容':[content], '获赞数':[like]}) 43 # # print(text) 44 # df = pd.concat([text]) 45 dit = { 46 '用户id':id, 47 '评论内容':content, 48 '获赞数':like, 49 } 50 print(dit) # 打印是否符合预期 51 csvWriter.writerow(dit) # 逐行写入内容 52 break # 调试的时候只怕一页
程序运行结果:

评论。照样《悬崖之上》为例,爬一波评论数据。本来评论请求的url地址长这样:https://comment.xxx.com/v4/comment/getCommentList?page=1&subjectType=hunantv2014&subjectId=12281642&callback=jQuery182024636113438271012_1636961381836&_support=10000000&_=1636961383307,有人说callbackhi干扰数据解析,而时间戳不会破坏数据完整性。所以把url改成了:https://comment.xxx.com/v4/comment/getCommentList?page=1&subjectType=hunantv2014&subjectId=12281642&_support=10000000。
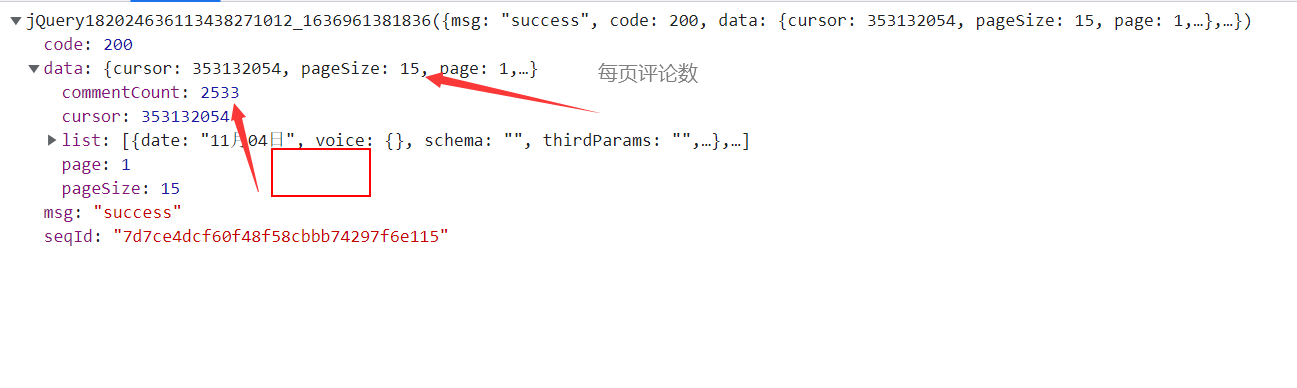
代码分页的标准的参数,就是2533/15 = 168.86,也就是最大页数为169。开干。
1 """ 2 爬取芒果TV的评论数据 3 """ 4 import csv 5 import pprint 6 import random 7 import time 8 9 import requests 10 11 f = open('悬崖之上评论数据.csv', mode='a', encoding='utf-8-sig', newline='') 12 csvWriter = csv.DictWriter(f, fieldnames=[ 13 '评论者', 14 '评论创建时间', 15 '评论内容', 16 '被点赞数', 17 ]) 18 csvWriter.writeheader() # 写入头 19 headers = { 20 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36', 21 } 22 for page in range(1, 169): 23 print(f'=====正在爬取第{page}页内容=====') 24 time.sleep(random.randint(2, 5)) # 随机休眠 25 url = f'https://comment.xxxx.com/v4/comment/getCommentList?page={page}&subjectType=hunantv2014&subjectId=12281642&_support=10000000' 26 response = requests.get(url=url, headers=headers) 27 # print(response.json()['data']['list']) # 这是个列表 28 # pprint.pprint(response.json()['data']['list']) 29 # 提取评论人姓名,评论日期,评论内容和被点赞数 30 for item in response.json()['data']['list']: 31 name = item['user']['nickName'] # 评论人姓名 32 contentCreated = item['date'] # 评论时间,也可以获取时间戳转换成本地时间 33 content = item['content'] # 评论内容 34 praiseNum = item['praiseNum'] # 被点赞数 35 dit = { 36 '评论者':name, 37 '评论创建时间':contentCreated, 38 '评论内容':content, 39 '被点赞数':praiseNum, 40 } 41 print(dit) 42 # 写入到csv 43 csvWriter.writerow(dit) # 逐行写入 44 print('爬取完成!')
程序运行截图:

其次是某讯视频
弹幕。进入开发者工具,当视频播放30秒它就会更新一个json数据包,里面包含需要的弹幕数据。
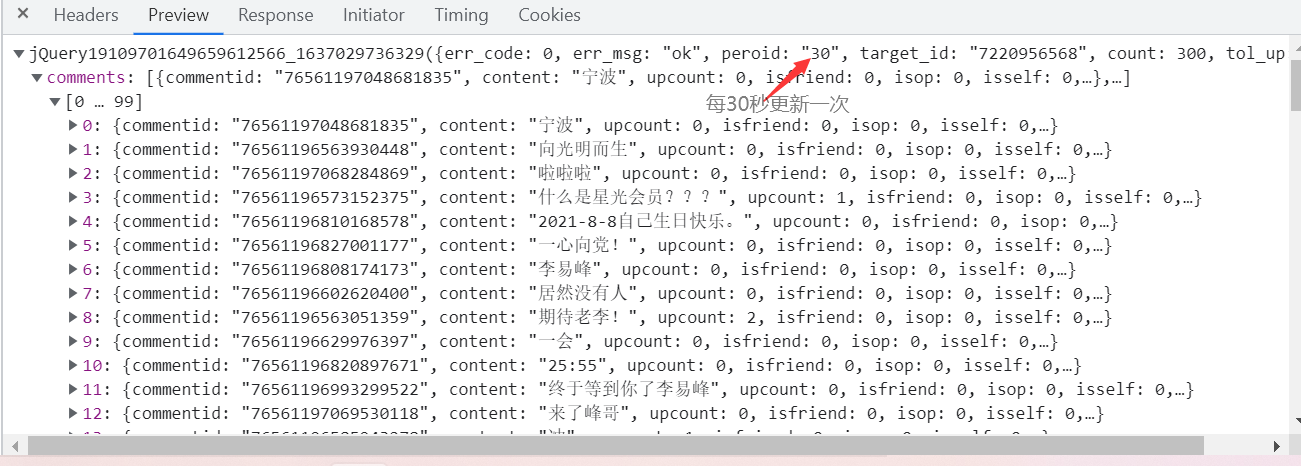
对比请求的url发现,第一次请求的是15个,后面请求的都是30。
https://mfm.video.xx.com/danmu?otype=json&callback=jQuery19109701649659612566_1637029736329&target_id=7220956568&vid=t0040z3o3la&session_key=0,38,1637029735×tamp=15&_=1637029736342
https://mfm.video.xx.com/danmu?otype=json&callback=jQuery19109701649659612566_1637029736329&target_id=7220956568&vid=t0040z3o3la&session_key=0,38,1637029735×tamp=45&_=1637029736342
照样干掉不必要的callback参数。开干:
1 import csv 2 import random 3 import time 4 import requests 5 6 f = open('某讯视频弹幕数据.csv', mode='a', encoding='utf-8-sig', newline='') 7 csvWriter = csv.DictWriter(f, fieldnames=[ 8 '弹幕发送ID', 9 '弹幕内容', 10 '获赞数', 11 ]) 12 # 写入头 13 csvWriter.writeheader() 14 # 请求头 15 headers = { 16 'user-agent':'https://mfm.video.xxx.com/danmu?otype=json&callback=jQuery19109701649659612566_1637029736329&target_id=7220956568&vid=t0040z3o3la&session_key=0,38,1637029735×tamp=165&_=1637029736342', 17 'referer':'https://v.qq.com/', 18 } 19 # 多页爬取 20 for timestamp in range(15, 7245, 30): #初始为15,7245为视频总秒长,后面以30递增 21 time.sleep(random.randint(2, 5)) # 休眠 22 url = f'https://mfm.video.xxx.com/danmu?otype=json&target_id=7220956568&vid=t0040z3o3la&session_key=0,38,1637029735×tamp={timestamp}&_=1637029736342' 23 # 请求数据 24 response = requests.get(url=url, headers=headers) 25 # print(response.json()) # 如果不干掉url里的callback参数的话得到的数据需要处理才能用json加载 26 # 提取数据 27 for item in response.json()['comments']: 28 id = item['commentid'] # 弹幕发送者id 29 danmu = item['content'] # 获取到弹幕内容 30 like = item['upcount'] # 获赞数 31 dit = { 32 '弹幕发送者ID':id, 33 '弹幕内容':danmu, 34 '获赞数':like, 35 } 36 print(dit) 37 csvWriter.writerow(dit) 38 39 print('爬取完成!')
程序运行截图:

评论获取。 某讯视频评论数据在网页底部,是动态加载的,需要抓包进行分析。
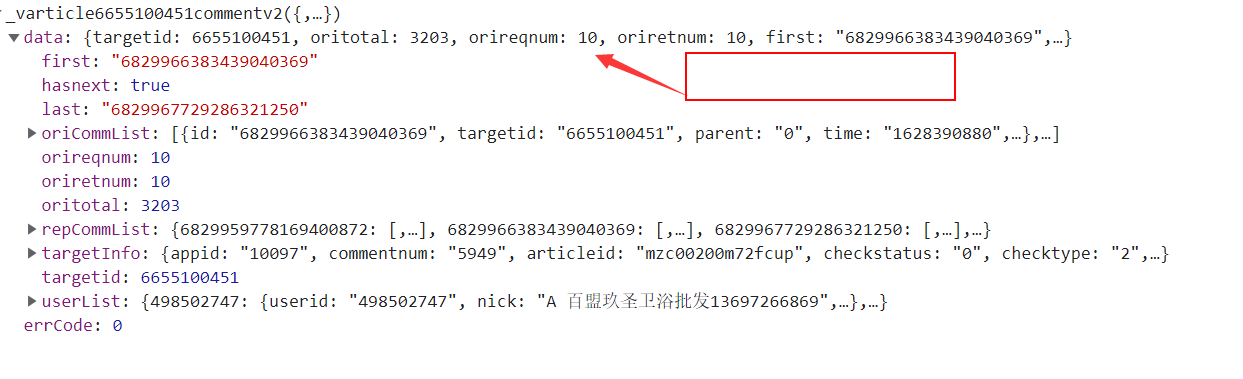
请求的url是:
https://video.coral.xxx.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1637030980407
https://video.coral.xxx.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6829967729286321250&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1637030980410
变化在cursor参数,开始的时候cursor是0,翻页后的cursor是上一个url的json数据里的data,last字段。也就是可以通过获取response.json()['data']['last']来获取curosr。开干:
1 import csv 2 import random 3 import re 4 import time 5 import requests 6 from urllib.parse import unquote 7 8 f = open('某讯视频评论.csv', mode='a', encoding='utf-8-sig', newline='') 9 csvWriter = csv.DictWriter(f, fieldnames=[ 10 'Id', 11 '评论人', 12 '评论时间', 13 '获赞数', 14 '评论内容', 15 ]) 16 # 写入头 17 csvWriter.writeheader() 18 # 请求头 19 headers = { 20 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36', 21 } 22 23 # 每页的评论数是10,总共有3203,所以最大值是321 24 page = 1 # 初始计数,一定从1开始,从0开始的话,while循环里获取不到cursor 25 while page < 321: 26 print(f'=====开始爬取{page}页的内容=====') 27 time.sleep(random.randint(2, 5)) # 随机休眠 28 # 第一页的情况,第一页很重要,因为我们要获取cursor以供else分支使用 29 if page == 1: 30 # 照样干掉url里的callback参数 31 url = 'https://video.coral.xxx.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132' 32 else: 33 url = f'https://video.coral.xxxx.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor={cursor}&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132' 34 res = requests.get(url=url, headers=headers).json() # 请求数据 第一次请求的实际上是page==1的情况 35 cursor = res['data']['last'] # 第一次请求url后就能得到一个cursor,然后通过循环传递给循环分支else 36 print(f'=====要爬取的url为{url}=====') 37 time.sleep(2) 38 # 每次请求完url后获取数据 39 for item in res['data']['oriCommList']: 40 id = item['id'] # 评论者id 41 # 使用urllib的unquote函数对url进行解码 42 nickname = unquote(item['custom']) 43 commentTime = item['time'] # 这个是时间是时间戳,存储的时候再做转换 44 # 尝试获取获赞数 45 try: 46 like = item.get('up') 47 except: 48 like = 'No' 49 content = item['content'] # 评论内容 50 dit = { 51 'Id':id, 52 '评论人':re.findall('nick=(.*?)&head', nickname)[0], # 通过正则把解码后的字符串里的名字提取出来 53 '评论时间':time.strftime("%Y-%m-%d %H:%M", time.localtime(int(commentTime))), # 将获取到的时间戳转换成本地时间 54 '获赞数':like, 55 '评论内容':content, 56 } 57 print(dit) 58 csvWriter.writerow(dit) # 逐行写入csv文档 59 page+=1 # 翻页递增 进入下一次循环 60 time.sleep(random.uniform(2, 3)) 61 print('评论爬完成!')
程序运行部分截图:

第三是B站
以《EDG夺冠时刻》,B站的上的纪录片为例进行爬取。视频地址:https://www.bilibili.com/bangumi/play/ss39849/?from=search&seid=6112754044363142537&spm_id_from=333.337.0.0。
弹幕:
找到视频,点开右边的弹幕列表,加载弹幕的时候,得到的数据如下:
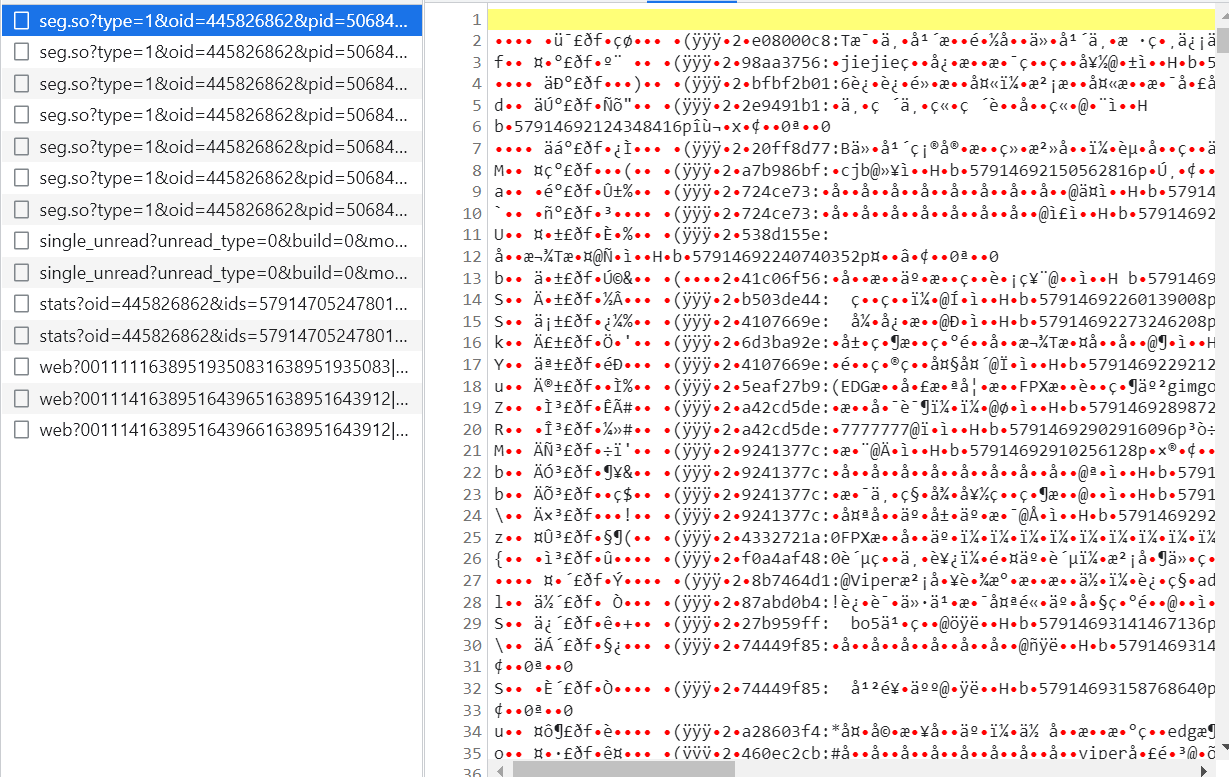
假如登录了的话,可以点击“查看历史弹幕”,如果没登录,这个按钮是灰色的。
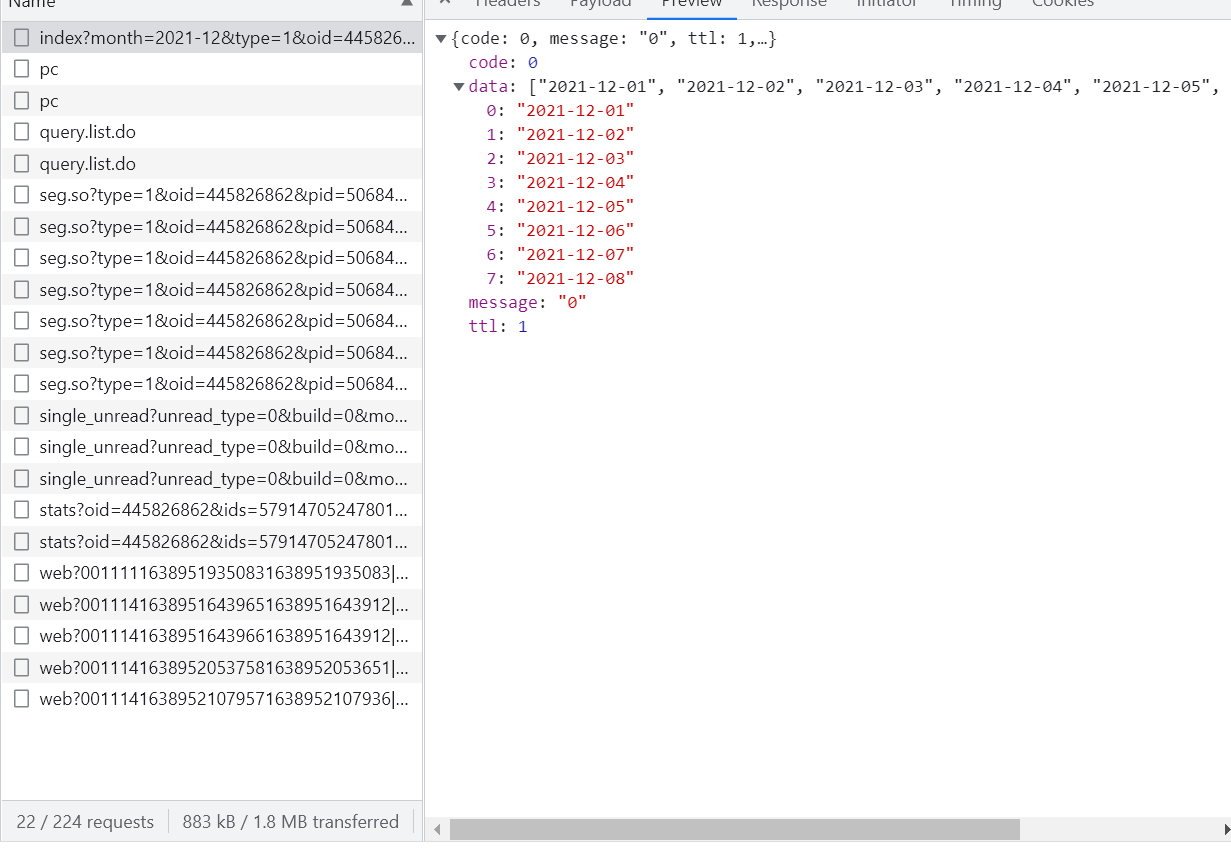
历史弹幕包括2021年12月1日到8日的弹幕。打点击“查看历史弹幕”的时候,会出现每天弹幕的数据,得到类似url:https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=445826862&date=2021-12-02。发现其中的关联,开始构造url并开干。
1 import requests 2 import pandas as pd 3 import re 4 5 def data_response(url): 6 headers = { 7 "cookie":"_uuid=BE35640F-EB4E-F87D-53F2-7A8FD5D50E3330964infoc; buvid3=D0213B95-F001-4A46-BE4F-E921AE18EB67167647infoc; CURRENT_BLACKGAP=1; CURRENT_QUALITY=0; rpdid=|(u))ku~m)kJ0J'uYJuRRRYmk; video_page_version=v_old_home_17; blackside_state=1; LIVE_BUVID=AUTO1516364619569495; b_lsid=E27592910_17D990B450B; bsource=search_baidu; buvid_fp=D0213B95-F001-4A46-BE4F-E921AE18EB67167647infoc; innersign=1; sid=ipqajpj8; CURRENT_FNVAL=80; PVID=2; fingerprint=23eb07890bf96775d60093211947fae4; buvid_fp_plain=2919B0C8-360F-47D1-8DD1-51FA81536F4E34777infoc; DedeUserID=603136708; DedeUserID__ckMd5=2e5e771f4e696459; SESSDATA=93ba949a,1654503622,fb700*c1; bili_jct=9d8bc6e01fc089192a6aeed373a0333c", 8 "referer":"https://www.bilibili.com/bangumi/play/ss39849/?from=search&seid=6112754044363142537&spm_id_from=333.337.0.0", 9 "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36", 10 } 11 response = requests.get(url=url, headers=headers) 12 13 return response # 返回 14 15 def main(oid, month): 16 df = pd.DataFrame() 17 url = f'https://api.bilibili.com/x/v2/dm/history/index?month={month}&type=1&oid={oid}' 18 # url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}' 19 list_data = data_response(url).json()['data'] # 拿到所有日期 20 print(list_data) 21 for data in list_data: 22 urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}' # 网址 23 text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_response(urls).text) 24 for e in text: 25 print(e) 26 data = pd.DataFrame({'弹幕': [e]}) 27 df = pd.concat([df, data]) 28 df.to_csv('弹幕.csv', encoding='utf-8-sig', index=False, mode='a+') 29 30 31 if __name__ == "__main__": 32 oid = '445826862' # 视频弹幕链接的id值 33 month = '2021-12' # 开始日期,这里至于哦2021-12-01到2021-12-08 34 main(oid, month) # 运行程序 35
这样就把所有弹幕数据都爬下来了。还有一种爬b站弹幕的方法。有人说B站的弹幕藏在:https://comment.bilibili.com/445826862.xml,其中的数字就是视频的oid。用浏览器打开试了下,确实都在,也来用python爬下。
1 import requests 2 import pandas as pd 3 import re 4 5 def data_get(oid): 6 headers = { 7 "cookie": "_uuid=BE35640F-EB4E-F87D-53F2-7A8FD5D50E3330964infoc; buvid3=D0213B95-F001-4A46-BE4F-E921AE18EB67167647infoc; CURRENT_BLACKGAP=1; CURRENT_QUALITY=0; rpdid=|(u))ku~m)kJ0J'uYJuRRRYmk; video_page_version=v_old_home_17; blackside_state=1; LIVE_BUVID=AUTO1516364619569495; b_lsid=E27592910_17D990B450B; bsource=search_baidu; buvid_fp=D0213B95-F001-4A46-BE4F-E921AE18EB67167647infoc; innersign=1; sid=ipqajpj8; CURRENT_FNVAL=80; PVID=2; fingerprint=23eb07890bf96775d60093211947fae4; buvid_fp_plain=2919B0C8-360F-47D1-8DD1-51FA81536F4E34777infoc; DedeUserID=603136708; DedeUserID__ckMd5=2e5e771f4e696459; SESSDATA=93ba949a,1654503622,fb700*c1; bili_jct=9d8bc6e01fc089192a6aeed373a0333c", 8 "referer": "https://www.bilibili.com/bangumi/play/ss39849/?from=search&seid=6112754044363142537&spm_id_from=333.337.0.0", 9 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36", 10 } 11 url = f'https://comment.bilibili.com/{oid}.xml' 12 # 开始请求网页 13 response = requests.get(url=url, headers=headers) 14 response.encoding = response.apparent_encoding # 自动识别编码 15 response.encoding = 'utf-8' # 将编码转换成utf-8 16 print(response.text) # 17 textData = re.findall('<d p=".*?">(.*?)</d>', response.text) # 表达式的括号里才是需要的弹幕数据,是个列表 18 df = pd.DataFrame() 19 # 开始保存数据 20 for item in textData: 21 print(item) 22 data = pd.DataFrame({'弹幕': [item]}) 23 df = pd.concat([df, data]) 24 df.to_csv('弹幕1.csv', encoding='utf-8-sig', index=False, mode='a+') 25 26 if __name__ == "__main__": 27 oid = '445826862' 28 data_get(oid)
看了几行数据,完全不一样,可能存储格式不一样。不纠结了,接下来爬评论。
评论:
打开开发者工具,按F12查找评论请求的链接。得到如下url。
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172024432989634133118_1638953989760&jsonp=jsonp&next=0&type=1&oid=506840377&mode=3&plat=1&_=1638954002015 https://api.bilibili.com/x/v2/reply/main?callback=jQuery172024432989634133118_1638953989760&jsonp=jsonp&next=2&type=1&oid=506840377&mode=3&plat=1&_=1638954002015 https://api.bilibili.com/x/v2/reply/main?callback=jQuery172024432989634133118_1638953989760&jsonp=jsonp&next=3&type=1&oid=506840377&mode=3&plat=1&_=1638954002015
链接还是比较奇葩的,参数只有一个有变化就是next=数字。第一页是0,第二页是 2,第三页是3。不是常规的012这种格式。但是实际在网页中打开012这样的格式,也是会返回数据的。这里以它的格式为准,照样把不必要的参数干掉。就是callback参数和最后的时间戳,callback参数会影响json数据解析,时间戳不会。
1 import csv 2 import random 3 import threading 4 import time 5 import requests 6 import pandas as pd 7 from threading import Thread 8 9 # 请求头 10 headers = { 11 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36', 12 } 13 14 def pdToCsv(): 15 df = pd.DataFrame() # pandas数据格式,用于保存 16 try: 17 a = 1 # 约定 18 while True: 19 if a == 1: # 如果a=1,就让url里的next=0 20 url = 'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=0&type=1&oid=506840377&mode=3&plat=1' 21 else: 22 url = f'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next={a}&type=1&oid=506840377&mode=3&plat=1' 23 # 开始请求url 24 response = requests.get(url=url, headers=headers) 25 time.sleep(random.uniform(2, 5)) 26 for i in response.json()['data']['replies']: 27 uname = i['member']['uname'] # 用户名称 28 sex = i['member']['sex'] # 用户性别 29 mid = i['mid'] # 用户id 30 current_level = i['member']['level_info']['current_level'] # vip等级 31 message = i['content']['message'].replace('\n', '') # 用户评论 32 like = i['like'] # 评论点赞次数 33 ctime = i['ctime'] # 评论时间 34 data = pd.DataFrame({'用户名': [uname], '性别': [sex], 'id': [mid], 35 'vip等级': [current_level], '评论': [message], '获赞数': [like], 36 '评论时间': [ctime]}) 37 df = pd.concat([df, data]) 38 a += 1 # 自增1以便下一次循环 39 except Exception as e: 40 print(e) 41 df.to_csv('我们是冠军pd.csv', encoding='utf-8-sig') # 保存数据 42 print(df.shape) 43 44 45 """也可以向下面这样写""" 46 def stringToCsv(): 47 f = open('我们是冠军评论csv.csv', mode='a', encoding='utf-8-sig', newline='') # 打开文件 48 csvWriter = csv.DictWriter(f, fieldnames=[ 49 '用户名', 50 '性别', 51 'id', 52 'vip等级', 53 '评论内容', 54 '获赞数', 55 '评论时间', 56 ]) 57 csvWriter.writeheader() # 写入头 58 n = 1 59 while n < 5426 / 10 + 1: # 因为总共有5426条,所以要爬550页 60 time.sleep(random.uniform(2,5)) 61 if n == 1: # 循环的第一个请求url 62 url = 'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=0&type=1&oid=506840377&mode=3&plat=1' 63 else: 64 url = f'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next={n}&type=1&oid=506840377&mode=3&plat=1' 65 66 # 开始请求数据 67 response = requests.get(url=url, headers=headers) 68 for i in response.json()['data']['replies']: 69 uname = i['member']['uname'] # 用户名称 70 sex = i['member']['sex'] # 用户性别 71 mid = i['mid'] # 用户id 72 current_level = i['member']['level_info']['current_level'] # vip等级 73 message = i['content']['message'].replace('\n', '') # 用户评论 74 like = i['like'] # 评论点赞次数 75 ctime = i['ctime'] # 评论时间 76 print(uname, sex, mid, current_level, message, like, ctime, sep='|') 77 dit = { 78 '用户名': uname, 79 '性别': sex, 80 'id': mid, 81 'vip等级': current_level, 82 '评论内容': message, 83 '获赞数': like, 84 '评论时间': ctime, 85 } 86 # 逐行写入 87 csvWriter.writerow(dit) 88 n += 1 # 循环条件,不然会死循环 89 f.close() # 关闭文件 90 91 if __name__ == "__main__": 92 thread1 = threading.Thread(target=pdToCsv) 93 thread2 = threading.Thread(target=stringToCsv) 94 thread1.start() 95 thread2.start() 96 thread1.join() 97 thread2.join()