连央视都祝贺EDG夺冠,作为码农的我们,怎么能闲着,就来爬爬B站的弹幕,看看人都说了什么。刚开始有这个想法的时候呢,B站的视频cid地址还保存在json中,今天来写的时候,发现已经没有了,截图如下:
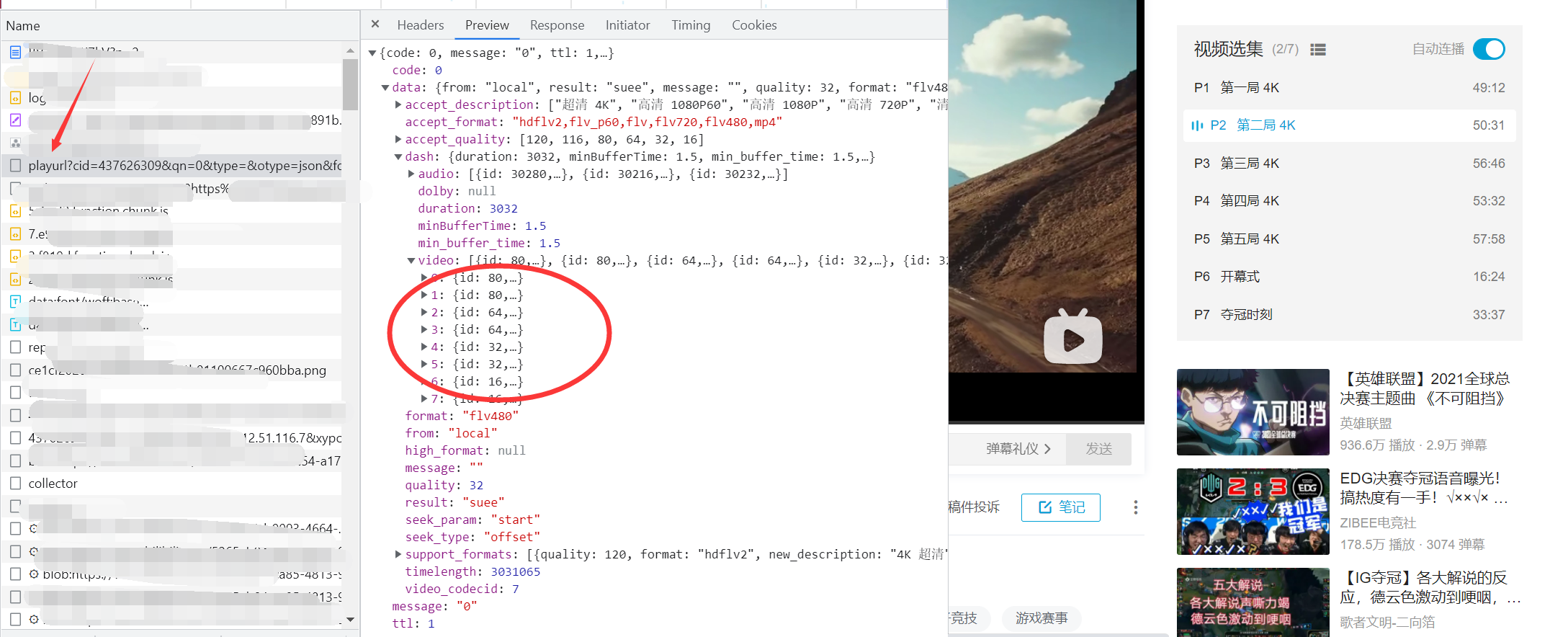
本来请求视频播放页面后,会有一个playlist的包,包里的json数据呢,就是图中圈圈的位置,id本来是cid。没有就没有了吧,重新找,发现源码里有。果断开干。
获取cid:
1 import requests 2 import re 3 # 请求头 4 headers = { 5 'user-agent':'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Mobile Safari/537.36', 6 } 7 # 视频播放的url 8 url = 'https://www.bilibili.com/video/BV1EP4y1j7kV' 9 # 开始请求 10 response = requests.get(url=url, headers=headeres) 11 # 查找cid 12 results = re.findall('"pages":[(.*?)],"subtitle"', response.text) # 列表 13 # 取出列表的第一项数据就成str了 14 strdata = results[0] 15 # 在strdata中查找cid 16 cids = re.findall('"cid":(d+),"page"', strdata) 17 videoPart = re.findall('"part":"(.*?)","du', strdata) 18 print(cids, videoPart) # ['437586584', '437626309', '437659159', '437727348', '437729555', '437550300', '437717574'] ['第一局 4K', '第二局 4K', '第三局 4K', '第四局 4K', '第五局 4K', '开幕式', '夺冠时刻']
请求到了cid后,接下来就是通过这个cid去拼接B站的弹幕url,B站的弹幕地址存储在https://www.ibilibili.com/video/BV1EP4y1j7kV,也就是视频播放页面,在bilibili加个i就出来了。
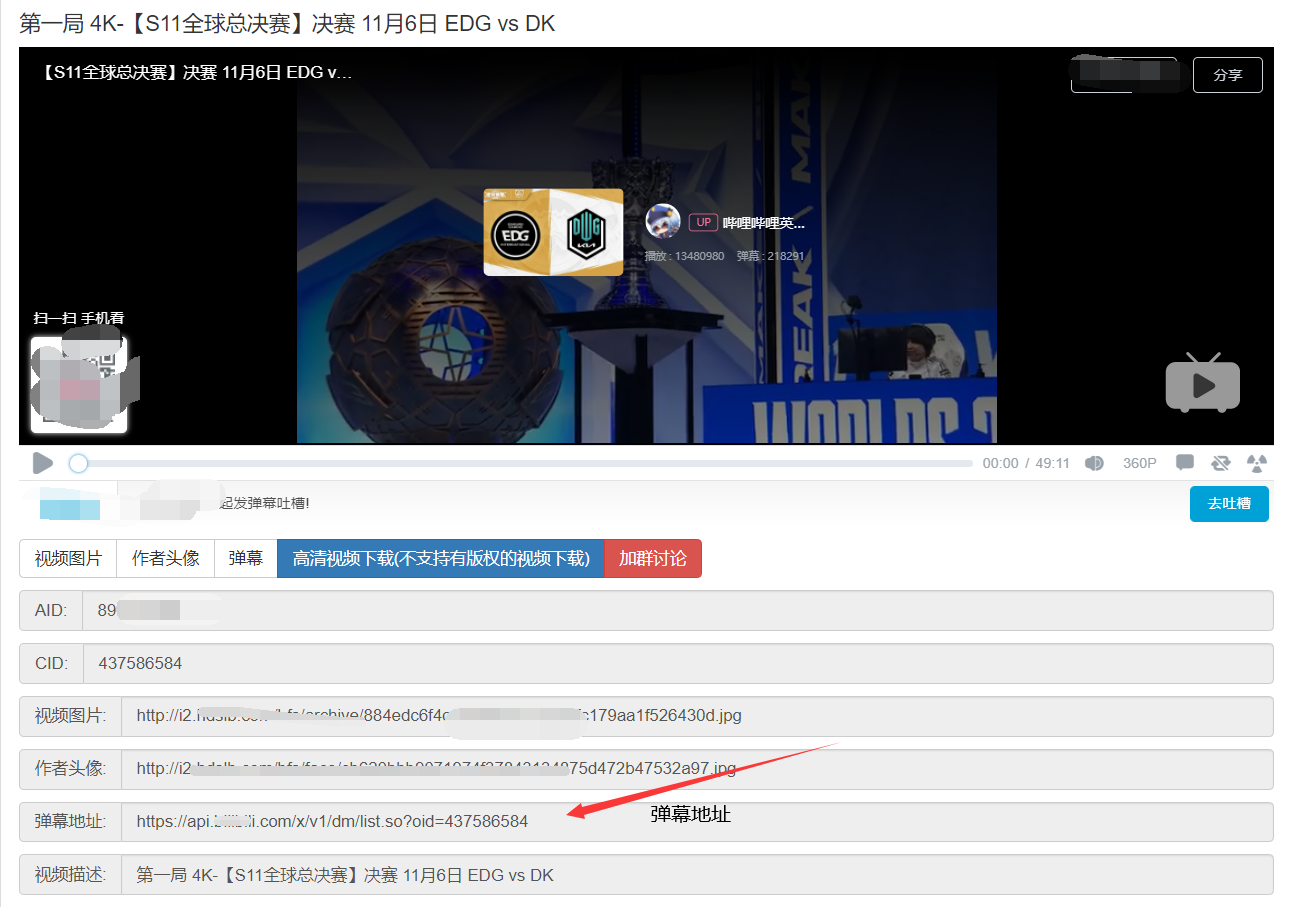
箭头出就是弹幕地址,弹幕地址后的oid就是刚刚找出来的cid。下面进行拼接并保存弹幕数据:
1 alldata = zip(cids, videoPart) 2 3 # 至此就找到了cid,接下来开始请求cid 4 for cid, videoName in zip(cids, videoPart): 5 danmuUrl = f'https://api.bilibili.com/x/v1/dm/list.so?oid={cid}' # 弹幕url 6 print(danmuUrl) 7 fileName = videoName # 按每场进行分别存储存储 8 print(fileName) 9 # 请求数据 10 res = requests.get(url=danmuUrl, headers=headers) 11 res.raise_for_status() 12 res.encoding = res.apparent_encoding # 转码 13 res.encoding = 'utf-8' # 转成utf-8 14 # print(res.text) 15 # 查找我们需要的数据 16 danmuData = re.findall('<d.*?>(.*?)</d>', res.text) # 要取弹幕内容,也就是()包含的,前面的.*?就是一个样式而已 17 # print(danmuData) 18 with open(f'{fileName}弹幕数据.txt', mode='a', encoding='utf-8-sig') as f: 19 for data in danmuData: # 循环读取每条弹幕 20 f.write(data) # 将每条弹幕顺序写入txt文档 21 f.write(' ') # 写完写一个换行符 22 break
爬完后的部分截图:

将第二段代码的最后的break删除,爬取7个视频的弹幕。截图如下:
接下来做词云展示。