如果系统的QPS超过10W+,甚至是百万以上的访问,则光是Redis是不够的,但是Redis是整个大型缓存架构中,支撑高并发的架构非常重要的环节。
首先,你的缓存中间件、缓存系统,必须能够支撑起10w+的高并发; 其次,再经过良好的整理缓存架构设计(多级缓存架构、热点缓存等),支撑真正上十万、甚至上百万的高并发。
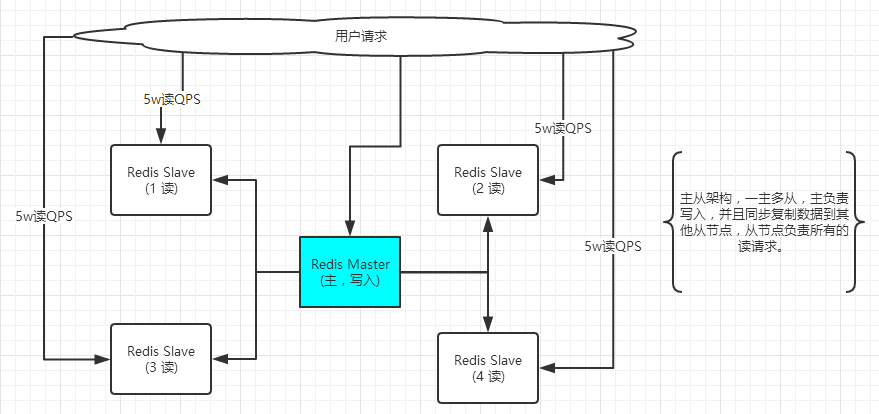
然而单机的Redis是支撑不了的,单机的Redis能够承载的QPS大概就在上万到几万的并发,除非你的服务器配置特别高,性能特别好的物理机,才有可能支持10w的请求,如果大量的访问过来,单机Redis被流量打死,则系统的瓶颈就卡到Redis上了。所以,我们要采用主从架构的Redis来支撑高并发系统。
一般高并发的应用,写的请求是比较少的,大量的请求都是读。所以我们要采用 主从架构 + 读写分离,来支撑10W+ 的读QPS的系统。
(1)主从架构
(2)读写分离
(3)可支持水平扩展的读高并发架构
redis replication的核心机制
(1)redis采用异步的方式复制数据到slave节点上,从2.8版本开始,salve node会周期性的确认自己每次复制的数据量
(2)一个master node可以配置多个slave node节点
(3)slave node也可以连接其他的slave node节点
(4)slave node做复制的时候,也不会阻止master node的正常工作
(5)slave node在做复制的时候,不会阻止对自己的查询操作,它会用旧的数据集来提供服务;但是复制完成的时候,需要删除旧的数据集,加载新数据集,这时候就会暂停对外的服务了
(6)slave node主要用来做横向扩容,做读写分离,扩容的slave node可以提供读的吞吐量.