
我得意地来到老板的办公室:“报告老板,高可用神器已祭出,您花巨资营销的高流量什么时候到?”
老板呵呵一声:“高流量下周一来报道,你可以准备下和他做工作交接了”
窗户外一阵冷风吹过,接下来是不是会发生点什么。
@
一、从阿里双11的高并发高流量开始
正如众所周知,每年的双11除了是购物狂欢节,同样也成了科技的大考和狂欢,让我们得以看到那么多高端的充满想象力的黑技术。在整个双11高并发高流量的过程中,Sentinel 承接了核心场景,完美地保障了阿里巴巴历年双十一的稳定性。
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。

通过Sentinel可以应对或支撑以下场景:
- 持续峰值:限流、慢调用降级
- 秒杀(也可称之为脉冲流量):限流、慢调用降级
- 削峰填谷:消费端可能会出现大批量的消息同时到达,若瞬时请求所有消息会导致系统负载过高。Sentinel利用匀速器模式将消息均摊到一段时间内,让系统负载保持在处理能力水位的同时尽可能地处理更多消息,从而起到“削峰填谷”的效果。
- 冷启动:当流量突然增大的时候,我们希望系统从空闲状态到繁忙状态的切换的时间长一些,即如果系统在此之前长期处于空闲的状态,我们希望处理请求的速率缓慢增加,经过预期的时间以后,到达系统处理请求速率的设定值;
- 热点商品自动探测、防护:自动统计访问频次最高的热点参数并进行流量控制;
- 集群流量不均匀:通过集群限流来解决集群各个机器的流量不均导致整体限流效果不精确的问题;
- 完备的实时监控:Sentinel 同时提供实时的监控功能。可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
作为一个功能完备的高可用流量控制框架,核心的 sentinel-core 打包后只有 286KB(最新的1.7.2版本),非常轻量级,可以放心地引入 sentinel-core 而不需担心依赖问题(打脸,没有坑是不可能的)。根据官方提供的数据,引入 Sentinel 带来的性能损耗非常小,单机 QPS 不太大的时候损耗几乎可以忽略不计(单机 4.3W QPS 的损耗约为 2.36%)
二、核心功能及原理说明
2.1 模块说明
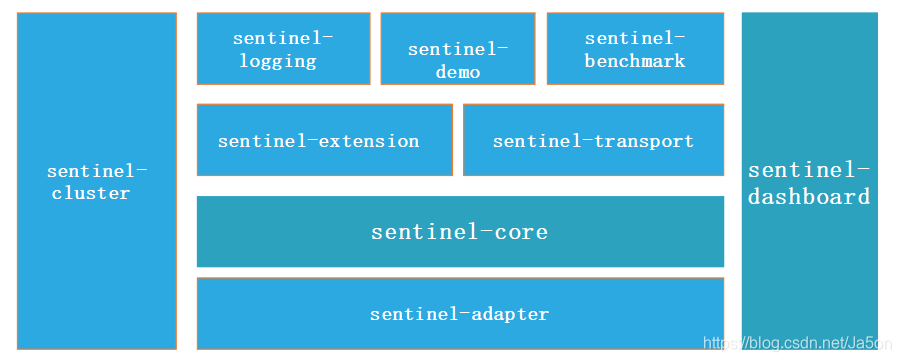
- sentinel-core 核心模块,限流、降级、系统保护等都在这里实现
- sentinel-dashboard 控制台模块,可以对连接上的sentinel客户端实现可视化的管理
- sentinel-transport 传输模块,提供了基本的监控服务端和客户端的API接口,以及一些基于不同库的实现
- sentinel-extension 扩展模块,主要对DataSource进行了部分扩展实现
- sentinel-adapter 适配器模块,主要实现了对一些常见框架的适配
- sentinel-demo 样例模块,可参考怎么使用sentinel进行限流、降级等
- sentinel-benchmark 基准测试模块,对核心代码的精确性提供基准测试
- sentinel-logging 日志模块,可将sentinel的日志通过slf4j集成到项目中
- sentinel-cluster 集群,1.4版本中提供了集群流控的功能
从使用上来看,主要分为两大部分:
核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 7 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持(见 主流框架适配)。
控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。
2.2 总体框架
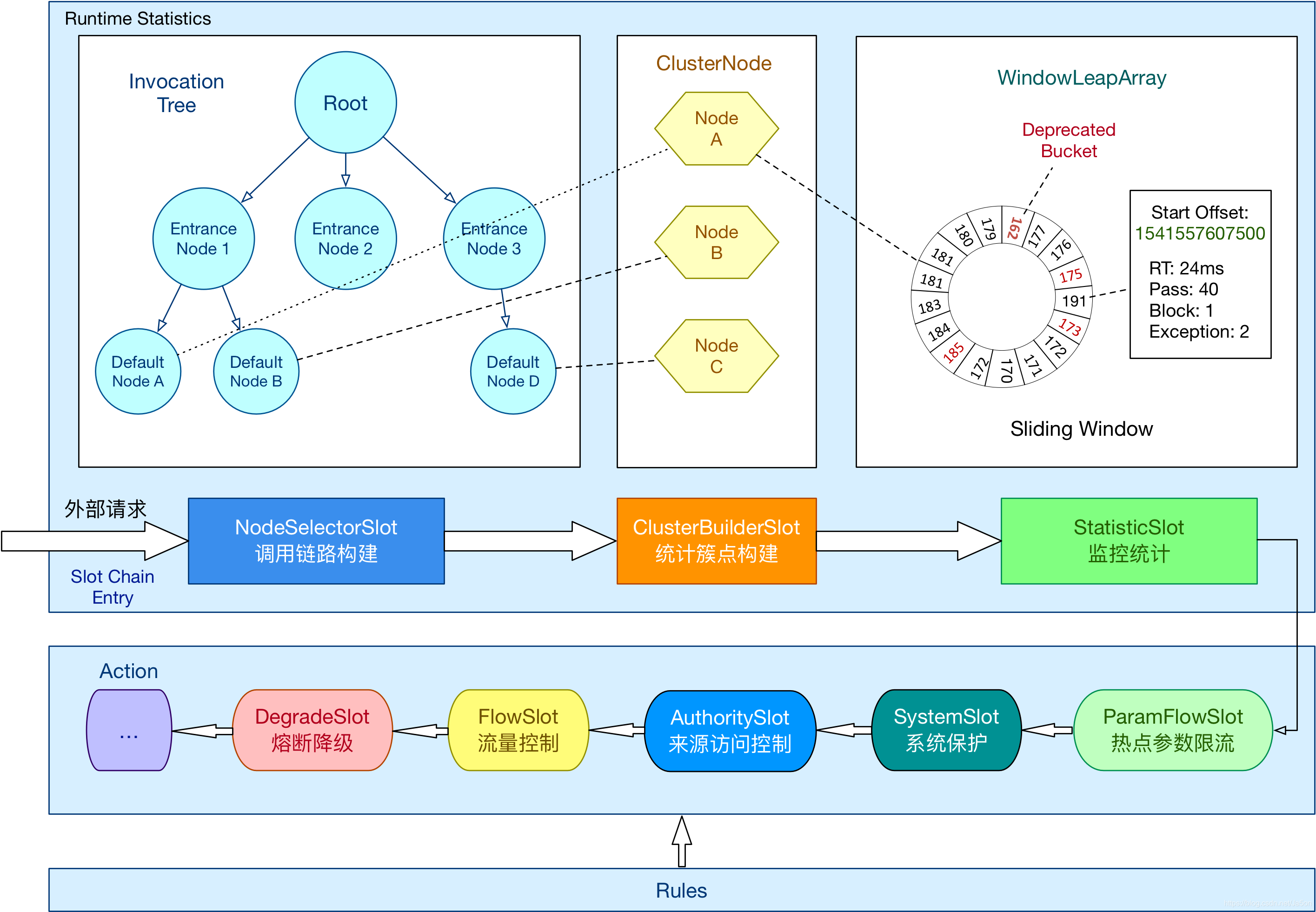
sentinel主要是基于7种不同的Slot形成了一个链表,每个Slot都各司其职,自己做完分内的事之后,会把请求传递给下一个Slot,直到在某一个Slot中命中规则后抛出BlockException而终止。前三个Slot负责做统计,后面的Slot负责根据统计的结果结合配置的规则进行具体的控制,是Block该请求还是放行。
- NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;
- ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;
- StatisticSlot 则用于记录、统计不同纬度的 runtime 指标监控信息;
- FlowSlot 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;
- AuthoritySlot 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;
- DegradeSlot 则通过统计信息以及预设的规则,来做熔断降级;
- SystemSlot 则通过系统的状态,例如 load1 等,来控制总的入口流量;
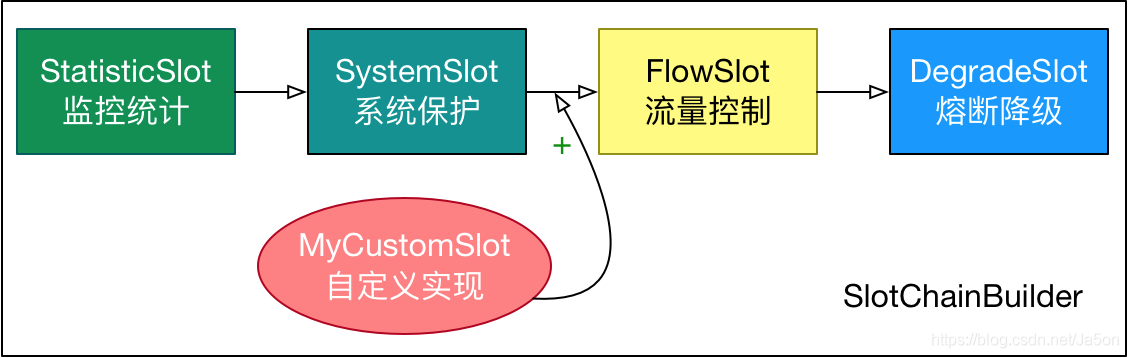
Sentinel 还提供简单易用、完善的 SPI 扩展接口。让开发人员可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
2.3 核心概念:Resource/Entry/Context/Node
-
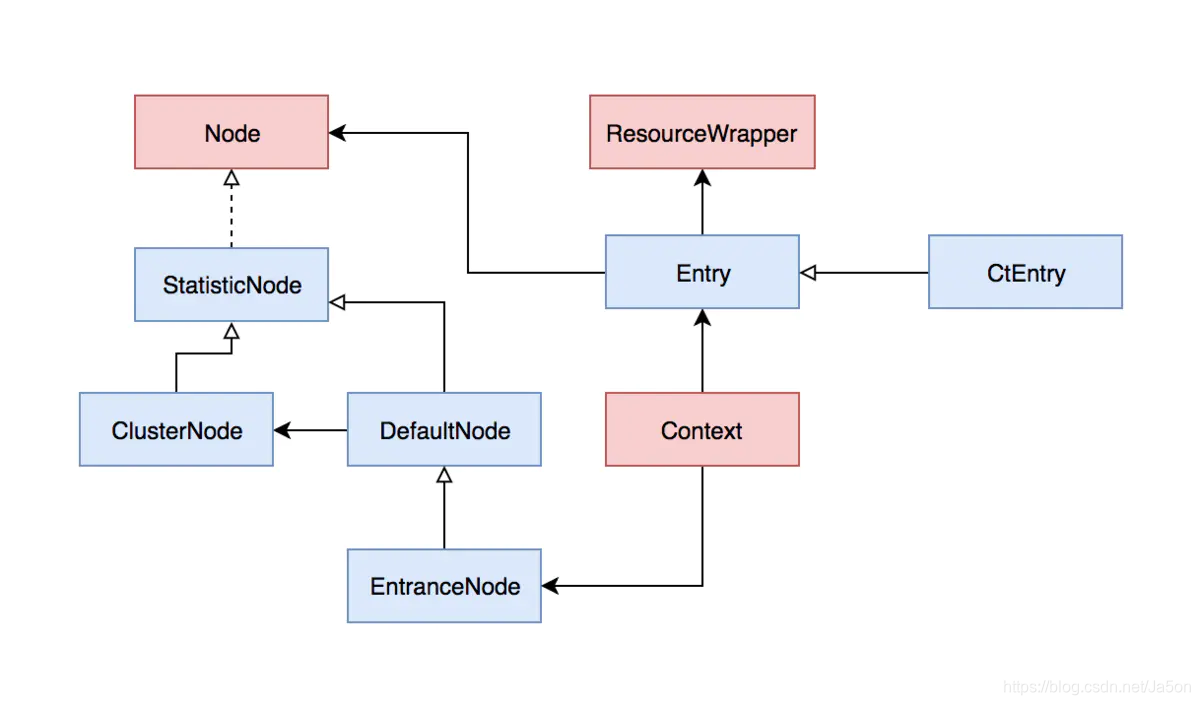
Resource
在Sentinel中把所有要保护的东西都称之为资源,它可以是服务,服务里的方法,甚至是一段代码。只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。 -
Context
Context是一个用来保存调用链当前状态的元数据的类,每次进入一个资源时,就会创建一个Context,相同的资源名可能会创建多个Context。一个Context中包含了三个核心的对象:
1)当前调用链的根节点:EntranceNode
2)当前的入口:Entry
3)当前入口所关联的节点:Node
Context中只会保存一个当前正在处理的入口Entry,另外还会保存调用链的根节点。需要注意的是,每次进入一个新的资源时,都会创建一个新的Context。 -
Entry
每次调用 SphU#entry() 都会生成一个Entry入口,该入口中会保存了以下数据:入口的创建时间,当前入口所关联的节点,当前入口所关联的调用源对应的节点。Entry是一个抽象类,他只有一个实现类,在CtSph中的一个静态类:CtEntry -
Node
节点是用来保存某个资源的各种实时统计信息的,他是一个接口,通过访问节点,就可以获取到对应资源的实时状态,以此为依据进行限流和降级操作。
2.4 简单上手及dashboard一览
官方有比较完善的演示代码:
/**
* 配置规则
*/
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
public static void main(String[] args) {
// 配置规则.
initFlowRules();
while (true) {
// 1.5.0 版本开始可以直接利用 try-with-resources 特性,自动 exit entry
try (Entry entry = SphU.entry("HelloWorld")) {
// 被保护的逻辑
System.out.println("hello world");
} catch (BlockException ex) {
// 处理被流控的逻辑
System.out.println("blocked!");
}
}
}
如果是SpringCloud项目,可参考https://github.com/sentinel-group/sentinel-guides/tree/master/sentinel-guide-spring-cloud
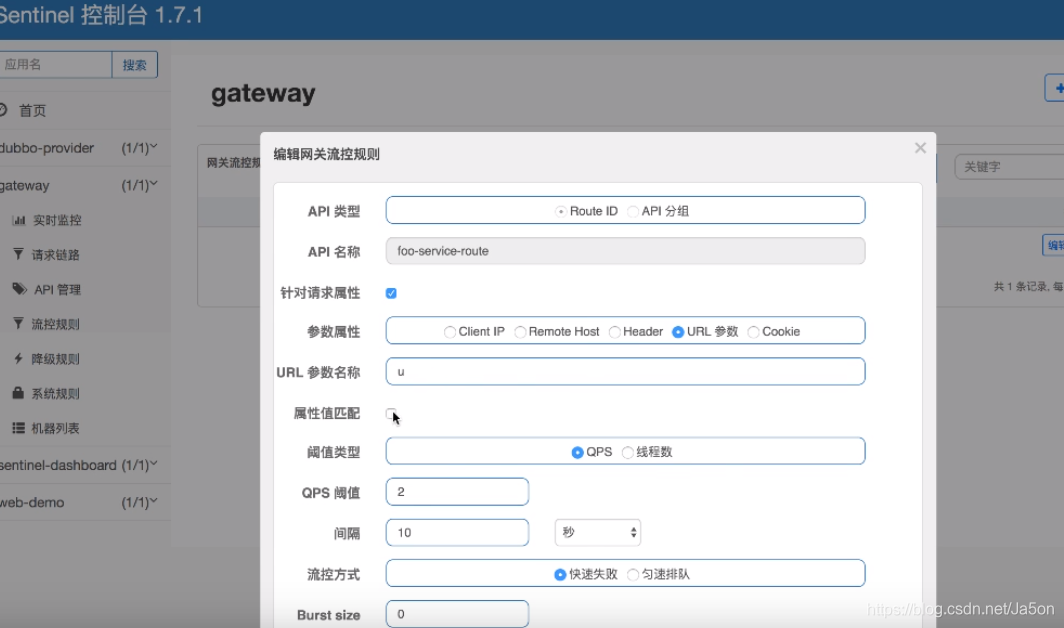
整个dashboard的功能体验下来,就是不停的 “我,这功能也有。我,还能这么玩啊”,网上案例比较多,这里就不多描述了。
三、生产环境下使用的一些思考
3.1 流量控制规则管理及推送
在前面已经提到了,Sentinel支持实时动态地配置规则,而不是预先在代码里定义好就无法改变了。实际情况下流量是动态的,比如某一个促销活动可能导致流量大增,甚至可能有一些不在预期内的流量。为了达到最好的防护效果,动态的规则可以将即将挂掉的应用从挂掉的边缘拉回来。但默认情况下,在dashboard设定规则后是通过API 将规则推送至客户端并直接更新到内存中,扩展写数据源(WritableDataSource),这样的方法简单,无任何依赖 ,但缺点也同样很明显:不保证一致性;规则保存在内存中,重启即消失。所以产线建议采用Push模式
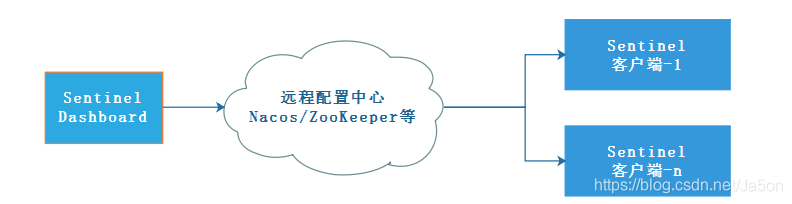
如上图所示,整个流程:配置中心控制台/Sentinel 控制台 → 配置中心 → Sentinel 数据源 → Sentinel。Sentinel目前已经支持了ZooKeeper、携程的 Apollo, 阿里自身的Nacos 等的动态数据源。接下来以Nacos为例:
1、在Spring Cloud应用中引入Sentinel模块和Nacos存储扩展:
implementation ('com.alibaba.cloud:spring-cloud-starter-alibaba-sentinel:2.1.2.RELEASE'){
exclude group:'com.alibaba',module: 'fastjson'}
implementation 'com.alibaba.csp:sentinel-datasource-nacos:1.7.2.RELEASE'
2、在应用中添加配置信息
spring:
cloud:
sentinel:
transport:
# sentinel dashboard的地址
dashboard: localhost:8080
datasource:
ds:
nacos:
# nacos的地址
server-addr: localhost:8848
# nacos中存储规则的groupId
dataId: madashu-test-sentinel
# nacos中存储规则的dataId
groupId: DEFAULT_GROUP
# 存储的规则类型
rule-type: flow
3、在Nacos中设置相应的规则
JSON:
[
{
"resource": "/madashu/hello",
"limitApp": "default",
"grade": 1,
"count": 5,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
- resource:资源名
- limitApp:流控针对的调用来源,default不区分来源
- grade:限流阈值类型(0-根据并发数量来限流 1-根据QPS来进行流量控制)
- count:限流阈值
- strategy:调用关系限流策略
- controlBehavior:流量控制效果(直接拒绝、WarmUP、匀速排队)
- clusterMode:是否集群模式
这里官方社区提供了限流规则保存和订阅的Demo,如果需要设置熔断降级、系统保护、网关限流等,参考配置即可。基本方式:Dashboard将xxRuleEntityVO模型序列化到保存到nacos,应用从nacos订阅后发序列成xxRule领域模型。
3.2 单机限流的阈值如何配置
这个千万不能照搬网上的配置或者拍脑袋,否则将会导致产线大规模的误杀或者瘫痪,一定要根据容量规划和水位设定来配置。具体可以参考单机容量规划的思路,在软负载中调整某个节点的流量权重和比例直到逼近极限为止。记录下极限状态的QPS,按照单机房70%的水位设定标准,这样就可以推算出该资源的单机限流阈值了。
四、从 Hystrix 迁移到 Sentinel
之前的微服务项目中基本上都是用Hystrix,从Hystrix迁移到Sentinel并不是一行配置一行代码的事,不要受网上一些教程的误导,需要具体评估自己的项目中使用到了Hystrix的场景。
4.1 为什么Sentinel不支持线程池隔离
比如相对于Hystrix,Sentinel 没有提供线程池隔离这样比较重的隔离方式,而是提供了信号量隔离这种比较轻量级的隔离方式。线程池隔离的好处是隔离度比较高,可以针对某个资源的线程池去进行处理而不影响其它资源,但是代价就是线程数目比较多,线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。另外,托管的线程切换可能会导致基于 ThreadLocal 的上下文传递丢失的问题(如 Spring 事务管理)。
4.2. 迁移方案
| Hystrix 功能 | 迁移方案 |
|---|---|
| 线程池隔离/信号量隔离 | Sentinel 不支持线程池隔离;信号量隔离对应 Sentinel 中的线程数限流 |
| 熔断器 | Sentinel 支持按平均响应时间、异常比率、异常数来进行熔断降级。 |
| Command 创建 | 直接使用 Sentinel SphU API 定义资源即可,资源定义与规则配置分离,详见此处 |
| 规则配置 | 在 Sentinel 中可通过 API 硬编码配置规则,也支持多种动态规则源 |
| 注解支持 | Sentinel 也提供注解支持,可以很方便地迁移 |
| 开源框架支持 | Sentinel 提供 Dubbo、Spring Cloud、gRPC 的适配模块,开箱即用;若之前使用 Spring Cloud Netflix,可迁移至 Spring Cloud Alibaba |
阿里开源的项目文档都还是比较完善的,迁移过程中如果遇到了问题,可参考:https://github.com/alibaba/Sentinel/wiki/Guideline:-从-Hystrix-迁移到-Sentinel
五、实战踩坑:Jar包兼容的那些坑
5.1 fastjson序列化异常
之前有一个Spring Cloud项目,在某个AOP中使用fastjson打印出入参,功能运行的很完美。后来引入了sentinel,添加了jar包spring-cloud-starter-alibaba-sentinel:2.1.2.RELEASE,然后很悲剧地发现fastjson序列化竟然异常了!
java.lang.NoSuchMethodError:
com.alibaba.fastjson.serializer.JavaBeanSerializer.processValue
(Lcom/alibaba/fastjson/serializer/JSONSerializer;
Lcom/alibaba/fastjson/serializer/BeanContext;Ljava/lang/Object;
Ljava/lang/String;Ljava/lang/Object;)
Ljava/lang/Object;Ljava/lang/Integer;
at com.alibaba.fastjson.serializer.ASMSerializer_12_XXX.writeNormal(Unknown Source) ~[?:?]
经过排查发现,sentinel这个jar包依赖了fastjson1.2.62,而这个版本中是有bug的,具体参见,https://github.com/alibaba/fastjson/issues/2790。
解决方案:
排除掉依赖的jar包即可,fastjson1.2.60中是不存在该问题的。最新的1.2.68中是否修复了该问题没有验证,有兴趣的小伙伴可以验一下。
implementation ('com.alibaba.cloud:spring-cloud-starter-alibaba-sentinel:2.1.2.RELEASE'){
exclude group:'com.alibaba',module: 'fastjson'}
5.2. Sleuth和Sentinel,我们决斗吧
在微服务中,一个请求往往经过多个业务模块,比如用户发起支付,可能经过了会员服务、交易服务、支付服务、账户服务等,此时一旦某个服务发生了问题,定位时将会非常的困难。在Spring Cloud项目上,一般会引入链路调用跟踪框架Spring Cloud Sleuth+zipkin,此时务必要注意:如果在项目中使用了Feign,熔断可能已经失效了。因为Sleuth为了传递链路调用跟踪的信息对Feign进行了扩展,而Sentinel为了实现熔断限流也对Feign进行了扩展,也就导致了两个本互不相干的框架竟然产生了冲突。
解决方案:
方案1:二选一,做个决断吧,哈哈。Sleuth是支持Hystrix的,而Hystrix已停止了维护,Sentinel正火,说不定很快Sleuth也会支持Sentinel。
方案2:换成其他的链路调用跟踪框架,这个网上有很多开源的产品,笔者之前的公司时也曾研发并开源了这样一套系统。
方案3:最近刚发现网上有一位大佬提供了修改源码的方案,实现还是很简单的,将Sentinel融入到Sleuth中
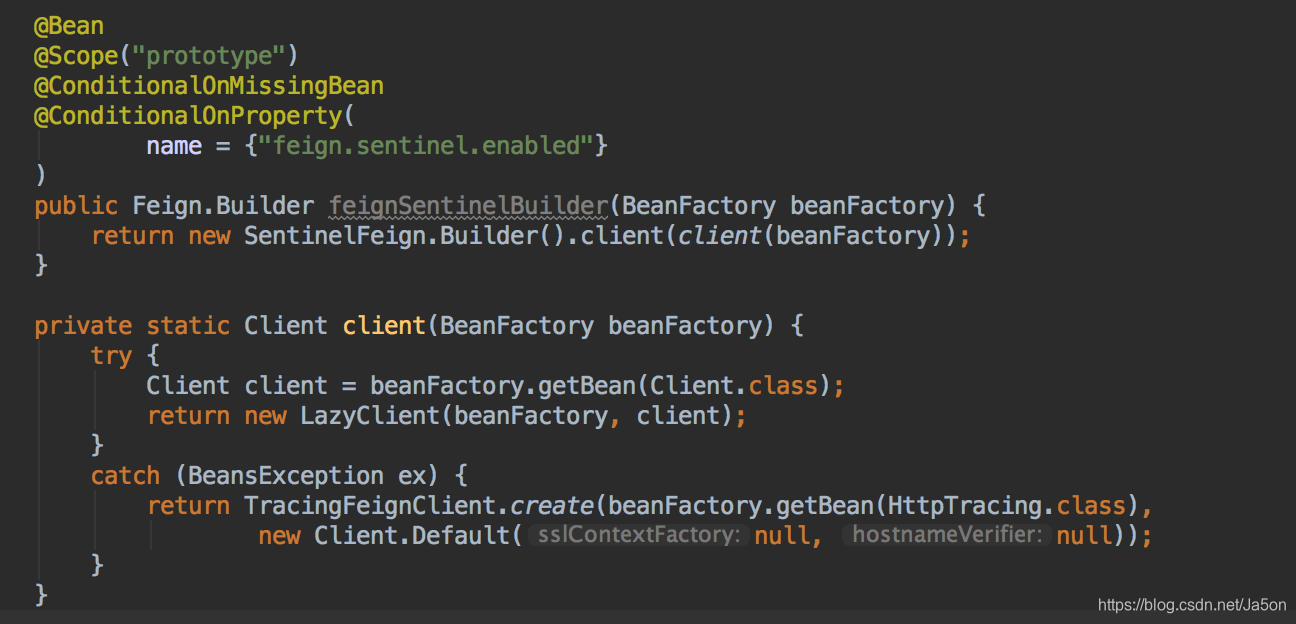
详细可参见:https://www.cnblogs.com/yinjihuan/p/12730654.html
以上只是对Sentinel一些粗浅的体验,在Sentinel中有很多优秀的设计思想、先进的算法、值得拜读的代码等,后续再慢慢品味。
参考,致谢:
https://blog.csdn.net/g6U8W7p06dCO99fQ3/article/details/104454238/
https://www.cnblogs.com/yinjihuan/p/12730654.html
https://github.com/alibaba/Sentinel/wiki/Guideline:-从-Hystrix-迁移到-Sentinel
https://www.jianshu.com/p/5a468b6a07fe
感谢关注公众号【码大叔】,公众号回复【进群】两个字,带你加入一个高品质圈子,由互联网公司HR、架构师、行业资深大佬组成的微信群,空位不多噢。
码大叔,28岁+大龄资深程序员、架构师技术社区
关注微服务、大数据、架构设计、技术管理
