一、概述
IdentityHashMap也是一类特殊的Map,根据其名字,Identity,即同一性,其表现出的具体特点便是,在判断Map中的两个key是否相等时,只通过==来判断,而不通过equals,也就是说,如果两个key相同,那么这两个key必须是同一个对象。
除此之外,虽然这也是HashMap,即至少是Key的存储是基于Hash实现的,但其存储方式跟HashMap还是有很大的不一样。下面详细分几个方面进行说明。
二、实现分析
1. 初始化
可以通过三种方式来构造一个IdentityHashMap, 如下:
public IdentityHashMap() { init(DEFAULT_CAPACITY);//默认32 } public IdentityHashMap(int expectedMaxSize) { if (expectedMaxSize < 0) throw new IllegalArgumentException("expectedMaxSize is negative: " + expectedMaxSize); init(capacity(expectedMaxSize)); } public IdentityHashMap(Map<? extends K, ? extends V> m) { // Allow for a bit of growth this((int) ((1 + m.size()) * 1.1)); putAll(m); }
可以看到,以上三种方式最终都调用了init方法,而传入的参数即是容器的容量,而第二个方法中,在调用init之前会先对参数值进行处理,其目的是根据当前值构造一个最接近该数值的2的指数倍,这样,保证初始化时,容量的大小为2的指数倍。
初始化的具体过程如下:
private void init(int initCapacity) { threshold = (initCapacity * 2)/3; //阈值为初始值的2/3,所以对于默认值32来说, //其大小为32*2/3=21,这是key的个数 table = new Object[2 * initCapacity];//为什么*2,因为值也是放在这个table中的 //所以table的size不等于容量 }
代码很简单,设置阈值为容量的2/3,并申请一个2倍于容量的数组。之所以这里要扩大一倍,是因为Map值也存储于这个数组中,所以,需要与key一一对应。
2.存储
对于存储来说,我们还是来看下put的实现
public V put(K key, V value) { Object k = maskNull(key); Object[] tab = table; int len = tab.length; int i = hash(k, len); Object item; while ( (item = tab[i]) != null) { if (item == k) { V oldValue = (V) tab[i + 1]; tab[i + 1] = value; return oldValue; } i = nextKeyIndex(i, len); } modCount++; //新增加一个 tab[i] = k; tab[i + 1] = value; if (++size >= threshold) resize(len); // len == 2 * current capacity. return null; } private static int nextKeyIndex(int i, int len) { return (i + 2 < len ? i + 2 : 0); }
根据上面的业务逻辑,我们将其用流程图表示如下:
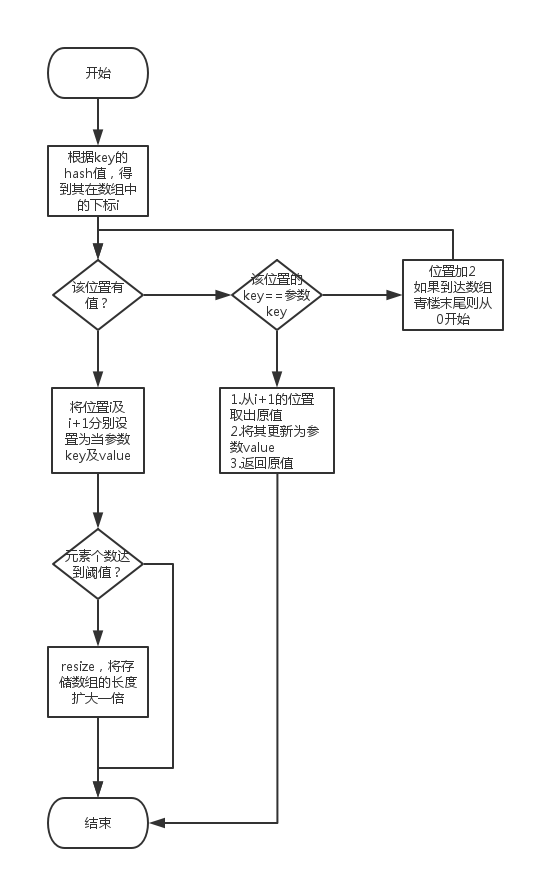
根据流程图我们不难理解这个逻辑,有几点需要注意一下:
1)key和value的值实际上都是存储在数组中的,而且val是挨着key存储的。
2)当发生冲突的时候,这里采用的方式是依次找下一个,直到有空的位置,或者找到key应有的位置。
3)因为在超过阈值后会进行resize的操作,table的长度会被扩大一倍,所以步骤2)一定能找到一个空位置,或者找到之前设置的位置。
如果没有自动扩容机制,则步骤2)很可能会出现死循环。
3. 查找
get方法的实现逻辑如下:
public V get(Object key) { Object k = maskNull(key); Object[] tab = table; int len = tab.length; int i = hash(k, len);//表的长度,2的n次方 while (true) { Object item = tab[i]; if (item == k) return (V) tab[i + 1]; if (item == null) return null; //那么这个表示不存在该key, 所以返回null i = nextKeyIndex(i, len); } }
这个过程很简单,了解了存储机制后,这个就容易理解了,需要说明的是,如果该位置为null,表示该位置未存储key, 返回null.
4. 删除
删除的业务逻辑如下:
public V remove(Object key) { Object k = maskNull(key); Object[] tab = table; int len = tab.length; int i = hash(k, len); while (true) { Object item = tab[i]; if (item == k) { modCount++; size--; V oldValue = (V) tab[i + 1]; tab[i + 1] = null; tab[i] = null; closeDeletion(i); return oldValue; } if (item == null) //未找到该key return null; i = nextKeyIndex(i, len); } }
查找的逻辑还是比较好理解,删除的话,实际上就是把相应位置的值置null,实现引用的消除,以便垃圾回收。
三、总结
上面我们大致分析了这类Map的存储机制,总的来说还是比较简单,和HashMap有类似的地方,但实现方式差别很大。主要差别整理如下 :
1)IdentityHashMap的loadFactor固定为2/3
2)IdentityHashMap的所有key和value都存储在数组中,key后的下一个位置即是对应的value
3)IdentityHashMap的冲突检测方式为线性再探测,即找下一个元素再探测,没有链式结构
4)最重要的一点,判断两个key是否相同,只根据==来判断,不使用equals
如果我们的业务需要有第4)点的需求,则可以使用IdentityHashMap.