一:文件保存
def save_to_file(file_name, contents):
fh = open(file_name, 'w')
fh.write(contents)
fh.close()
save_to_file('mobiles.txt', 'your contents str')
结果:
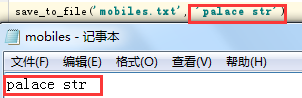
将字符串修改则覆盖原来的字符串
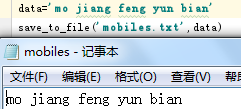
将字符串用变量替代
将 fh = open(file_name, 'w')写的权限去掉报错:
fh.write(contents)
io.UnsupportedOperation: not writable
写权限不加引号报错:
fh = open(file_name, w)
NameError: name 'w' is not defined
def save_to_file(file_name):中少一个参数报错:
save_to_file('mobiles.txt',data)
TypeError: save_to_file() takes 1 positional argument but 2 were given
def save_to_file(file_name,contents):
fh = open(file_name, 'w')
fh.write(contents)
fh.close()
print(type(fh),fh)
data='machangwei'
save_to_file('mobiles.txt',data)
打印结果:
<class '_io.TextIOWrapper'> <_io.TextIOWrapper name='mobiles.txt' mode='w' encoding='cp936'>
当data=123或列表、元组、字典等时报错,必须是字符串:
TypeError: write() argument must be str, not int
当其他类型想要输出到文件时需要变成字符串:
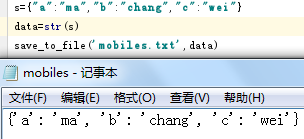
二:遍历文件
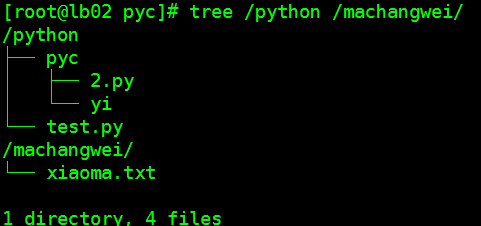
目录结构:
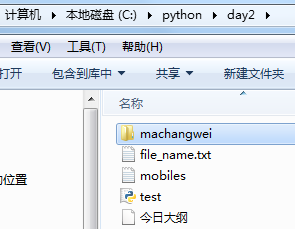
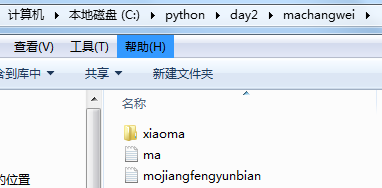
import os
import os.path
rootdir = "C:pythonday2" # 指明被遍历的文件夹
dic={}
for parent, dirnames, filenames in os.walk(rootdir): # 三个参数:分别返回1.父目录 2.所有文件夹名字(不含路径) 3.所有文件名字
print()
for dirname in dirnames: # 输出文件夹信息
print ("当前目录加下级目录parent and dirname is:" + parent+" + "+dirname)
print("遍历当前目录文件-------------------------------------------------------------")
for filename in filenames: # 输出文件信息
print("当前目录加文件parent and filename is:" + parent+" + "+filename)
print("上面那个文件全路径the full name of the file is:" + os.path.join(parent, filename)) # 输出文件路径信息
结果:
当前目录加下级目录parent and dirname is:C:pythonday2 + machangwei
遍历当前目录文件-------------------------------------------------------------
当前目录加文件parent and filename is:C:pythonday2 + file_name.txt.txt
上面那个文件全路径the full name of the file is:C:pythonday2file_name.txt.txt
当前目录加文件parent and filename is:C:pythonday2 + mobiles.txt
上面那个文件全路径the full name of the file is:C:pythonday2mobiles.txt
当前目录加文件parent and filename is:C:pythonday2 + test.py
上面那个文件全路径the full name of the file is:C:pythonday2 est.py
当前目录加文件parent and filename is:C:pythonday2 + 今日大纲
上面那个文件全路径the full name of the file is:C:pythonday2今日大纲
当前目录加下级目录parent and dirname is:C:pythonday2machangwei + xiaoma
遍历当前目录文件-------------------------------------------------------------
当前目录加文件parent and filename is:C:pythonday2machangwei + ma.txt
上面那个文件全路径the full name of the file is:C:pythonday2machangweima.txt
当前目录加文件parent and filename is:C:pythonday2machangwei + mojiangfengyunbian.txt
上面那个文件全路径the full name of the file is:C:pythonday2machangweimojiangfengyunbian.txt
遍历当前目录文件-------------------------------------------------------------
部分代码输出结果
rootdir = "C:pythonday2" # 指明被遍历的文件夹 print(type(rootdir),rootdir) print(type(os.walk(rootdir)),os.walk(rootdir))
结果:
<class 'str'> C:pythonday2 <class 'generator'> <generator object walk at 0x0000000001E05408>
打印单个目录的子节点为列表形式
print(os.listdir(rootdir))
结果:
['file_name.txt.txt', 'machangwei', 'mobiles.txt', 'test.py', '今日大纲']
三、文件操作
path = "E:\test.txt" fileHandle = open ( path, 'w' ) fileHandle.write ( 'hello my name is machangwei.' ) fileHandle.close() #文件有打开,有关闭,中间是对文件的操作。文件不存在就会创建,默认对同一文件再次写入时为覆盖,加参数a才能追加内容
print(type(fileHandle),fileHandle)
结果:
<class '_io.TextIOWrapper'> <_io.TextIOWrapper name='E:\test.txt' mode='w' encoding='cp936'>
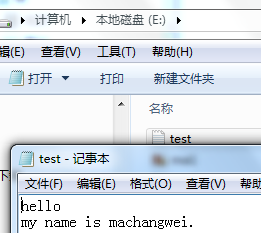
追加数据:
path = "E:\test.txt" fileHandle = open ( path, 'a' ) fileHandle.write ( ' I,m 12 years old' ) fileHandle.close()
结果:
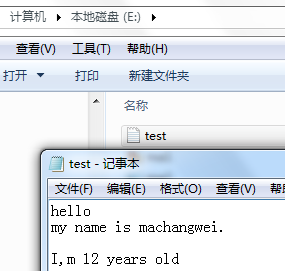
读取windos文件数据:
fileHandle = open ( 'E:\test.txt' ) print (fileHandle.read()) fileHandle.close()
结果:
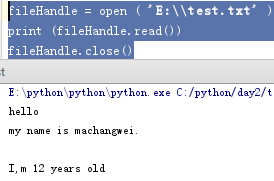
文件关闭前打印读取文件内容,否则报错:
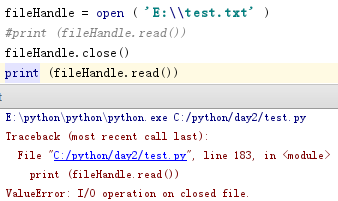
对文件第一行打印:
path = "E:\test.txt" fileHandle = open ( path ) print(fileHandle.readline()) fileHandle.close()
结果:
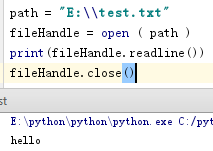
对文件每行打印:
path = "E:\test.txt"
fileHandle = open ( path )
fileList = fileHandle.readlines()
for fileLine in fileList:
print (">>",fileLine) #打印每行内容,多出一个空行
fileHandle.close()
print(fileList) #文件每行都是一个列表元素
结果:
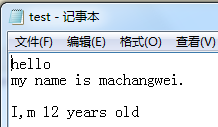
>> hello >> my name is machangwei. >> >> I,m 12 years old ['hello ', 'my name is machangwei. ', ' ', 'I,m 12 years old']
在文件中一次读取几个字节的内容:
内容:
path = "E:\test.txt"
fileHandle = open ( path )
print ('1',fileHandle.read ( 1 ))
print ('2',fileHandle.read ( 1)) #读取指针后一个字符
print ('3',fileHandle.read ( 1 ))
print ('4',fileHandle.read ( 1))
print ('5',fileHandle.read ( 1))
print ('6',fileHandle.read ( 1))
print ('7',fileHandle.read ( 1))
print ('8',fileHandle.read ( 1))
print ('9',fileHandle.read ( 1))
结果:
1 h 2 e 3 l 4 l 5 o 6 7 m 8 y 9
path = "E:\test.txt"
fileHandle = open ( path )
fileHandle.seek ( 4) #hello . seek指针定位到第几个字符
print (fileHandle.read ( 1 ))
fileHandle.seek ( 1)
print (fileHandle.read ( 4 )) #读取指针后几个字符
结果:
o
ello
再次从头读取文件:
path = "E:\test.txt"
fileHandle = open ( path )
garbage = fileHandle.readline()
print('第1行',garbage)
garbage = fileHandle.readline()
print("第二行:",garbage)
garbage = fileHandle.readline()
print("第三行",garbage)
garbage = fileHandle.readline()
print("第四行",garbage)
garbage = fileHandle.readline()
print("第五行",garbage)
garbage = fileHandle.readline()
print("第六行",garbage)
print('-------------')
fileHandle.seek ( 0 )
print (fileHandle.readline())
fileHandle.close()
结果:
第1行 hello 第二行: my name is machangwei. 第三行 #空行 第四行 I,m 12 years old 第五行 #没有第5,6行但是指针仍在末尾,能继续读不报错,但是没有内容输出 第六行 ------------- hello #指针重新定位,此处为定位到文件开头,可以重新从头读取文件
输出指针位置:
path = "E:\test.txt" fileHandle = open ( path ) print (fileHandle.readline()) print (fileHandle.tell() ) #输出指针位置 print (fileHandle.readline())
结果:
hello 7 #此处有 n 换行符,所以多了两个字节 my name is machangwei.
python没有二进制类型,但可以存储二进制类型的数据,就是struct模块。此处略。
四、os模块
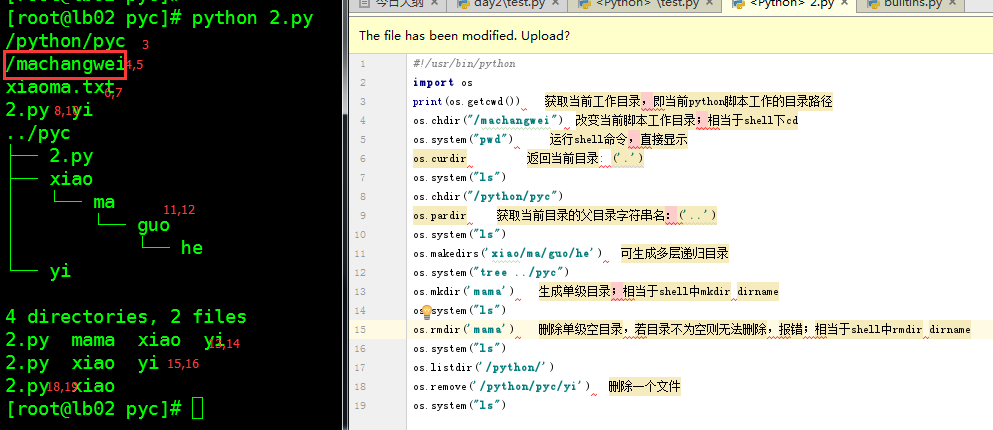
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
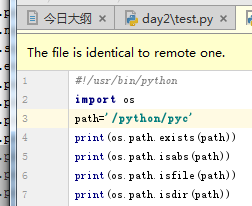
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
工作环境:
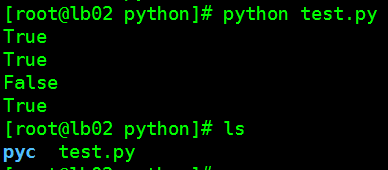
import os print(os.environ)
结果:
[root@lb02 pyc]# python 2.py {'LESSOPEN': '||/usr/bin/lesspipe.sh %s', 'SSH_CLIENT': '10.0.0.253 52839 22', 'LOGNAME': 'root', 'USER': 'root', 'PATH': '/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin', 'HOME': '/root', 'LANG': 'en_US.UTF-8', 'TERM': 'linux', 'SHELL': '/bin/bash', 'SHLVL': '1', 'HISTSIZE': '1000', 'XDG_RUNTIME_DIR': '/run/user/0', 'XDG_SESSION_ID': '40', '_': '/usr/bin/python', 'SSH_CONNECTION': '10.0.0.253 52839 10.0.0.6 22', 'SSH_TTY': '/dev/pts/0', 'OLDPWD': '/python', 'HOSTNAME': 'lb02', 'HISTCONTROL': 'ignoredups', 'PWD': '/python/pyc', 'MAIL': '/var/spool/mail/root', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=01;05;37;41:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.axv=01;35:*.anx=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=01;36:*.au=01;36:*.flac=01;36:*.mid=01;36:*.midi=01;36:*.mka=01;36:*.mp3=01;36:*.mpc=01;36:*.ogg=01;36:*.ra=01;36:*.wav=01;36:*.axa=01;36:*.oga=01;36:*.spx=01;36:*.xspf=01;36:'}
python中os.path.join和join的区别
python 中的split()函数和os.path.split()函数
结果:
五、文件操作
#似乎有问题 os.mknod("test.txt") 创建空文件
fp = open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件
关于open 模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() #把缓冲区的内容写入硬盘
fp.fileno() #返回一个长整型的”文件标签“
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
fp.read([size])
path = "E:\test.txt" fp = open ( path ) print(fp) fr=fp.read(4) #读取四个字节 print(fr)
结果:
<_io.TextIOWrapper name='E:\test.txt' mode='r' encoding='cp936'> hell
fp.readline([size])
path = "E:\test.txt" fp = open ( path ) print(fp.readline(4)) print(fp.readline(4)) print(fp.readline(4)) print(fp.readline(4))
结果:
hell
o
my n
ame
readlines
path = "E:\test.txt" fp = open ( path ) print(fp.readlines())
结果:
['hello ', 'my name is machangwei. ', ' ', 'I,m 12 years old']
fp.write
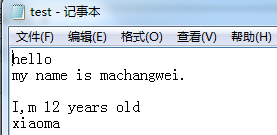
path = "E:\test.txt"
fp = open ( path ,'a+')
fp.write('
xiaoma') #如果文件的最后字符不是换行符,要想另起一行输入内容,需要加换行符
fp.close()
print('-----------------')
fp = open ( path )
for fp in fp.readline():
print(fp)
print('-----------------')
fp = open ( path )
for fp in fp.readlines():
print(fp)
结果:
----------------- h e l l o ----------------- hello my name is machangwei. I,m 12 years old xiaoma
目录操作:
os.mkdir("file") 创建目录
复制文件:
shutil.copyfile("oldfile","newfile") oldfile和newfile都只能是文件
shutil.copy("oldfile","newfile") oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹:
shutil.copytree("olddir","newdir") olddir和newdir都只能是目录,且newdir必须不存在
重命名文件(目录)
os.rename("oldname","newname") 文件或目录都是使用这条命令
移动文件(目录)
shutil.move("oldpos","newpos")
删除文件
os.remove("file")
删除目录
os.rmdir("dir")只能删除空目录
shutil.rmtree("dir") 空目录、有内容的目录都可以删
转换目录
os.chdir("path") 换路径
七、序列号
对象序列化(--->str)
import json
xiaoma=['wo',"shi",{'xing':'mo','ming':('jiang',None, 1.0, 2)}]
print (json.dumps(xiaoma))
print(type(xiaoma),type(json.dumps(xiaoma)))
结果:
["wo", "shi", {"xing": "mo", "ming": ["jiang", null, 1.0, 2]}] <class 'list'> <class 'str'>
序列号并排序
import json
print (json.dumps({"c": 3, "b": 2, "a": 1}, sort_keys=True))
结果:
{"a": 1, "b": 2, "c": 3}
类型都是字符串:
import json
print (json.dumps([1,2,3,{'4': 5, '6': 7}], sort_keys=True, separators=(',',':')))
print (json.dumps([1,2,3,{'4': 5, '6': 7}], sort_keys=True, separators=('/','-')))
print (json.dumps({'4': 5, '6': 7}, sort_keys=True,indent=2, separators=(',', ': ')))
print (json.dumps({'a':1,(1,2):123},skipkeys=True))
结果:
[1,2,3,{"4":5,"6":7}] #排序 [1/2/3/{"4"-5/"6"-7}] #修改分隔符 { #键值对的缩进的排列 "4": 5, "6": 7 } {"a": 1} #值不为str,则忽略这一项
保存非字符型数据内容:
方法一: #非字符串无法保存到文件
import json obj = ['sheng', {'shi': ('xian', None, 1.0, 2)}] with open(r"E:\test.txt","w+") as f: json.dump(obj,f) 方法二: # path = "E:\test.txt" # fileHandle = open ( path, 'w' ) # obj = ['sheng', {'shi': ('xian', None, 1.0, 2)}] # fileHandle.write ( str(obj) ) # fileHandle.close()
结果:
反序列化:
import json
obj = ['sheng', {'shi': ('xian', None, 1.0, 2)}]
a= json.dumps(obj)
b=str(obj)
print (json.loads(a))
print(type(json.loads(a)),type(a),type(b)) #a,b为字符串,json能将json.dumps生成的字符反序列化,不能将str生成的字符反序列化
结果:
['sheng', {'shi': ['xian', None, 1.0, 2]}] <class 'list'> <class 'str'> <class 'str'>
将文本中的字符反序列化
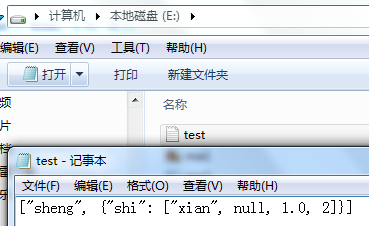
import json
with open(r"E:\test.txt","r") as f:
ma=json.load(f)
print (type(ma),ma)
结果:
<class 'list'> ['sheng', {'shi': ['xian', None, 1.0, 2]}]
pickle模块 略
------------------------------------------------
sys
1.
import sys
print(sys.version)

2、
import sys
print (sys.argv[0])
print (sys.argv[1])

3
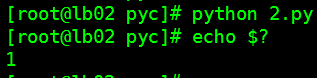
import sys
sys.exit(1)
正常退出码设置
4
print(sys.path)
[root@lb02 pyc]# python 2.py
['/python/pyc', '/usr/lib64/python27.zip', '/usr/lib64/python2.7', '/usr/lib64/python2.7/plat-linux2', '/usr/lib64/python2.7/lib-tk', '/usr/lib64/python2.7/lib-old', '/usr/lib64/python2.7/lib-dynload', '/usr/lib64/python2.7/site-packages', '/usr/lib64/python2.7/site-packages/gtk-2.0', '/usr/lib/python2.7/site-packages']
===================================================
hashlib
import hashlib
hash = hashlib.sha1()
hash.update(bytes('admin', encoding='utf-8'))
print(hash.hexdigest())
结果:
d033e22ae348aeb5660fc2140aec35850c4da997
pycharm上执行结果
xshell上执行用下面:
import hashlib
hash = hashlib.sha1()
hash.update(str('admin'))
print(hash.hexdigest())
结果:
[root@lb02 pyc]# python 2.py d033e22ae348aeb5660fc2140aec35850c4da997
更多请参考:http://www.cnblogs.com/wupeiqi/articles/5501365.html
--------=============================================================
random
import random print(random.random()) print(random.randint(1, 2)) #1-2的整数随机 print(random.randrange(1, 10)) #1-10的随机
[root@lb02 pyc]# python 2.py 0.111348076397 2 8