| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| Estimate | 估计这个任务需要多少时间 | 480 | 500 |
| Development | 开发 | 180 | 200 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 40 |
| Design Spec | 生成设计文档 | 60 | 80 |
| Design Review | 设计复审 | 60 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 60 | 30 |
| Coding | 具体编码 | 180 | 120 |
| Code Review | 代码复审 | 60 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 180 | 200 |
| Reporting | 报告 | 20 | 30 |
| Test Report | 测试报告 | 40 | 60 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 1470 | 1510 |
解题思路
- 第一眼看到题目,感觉代码难度并不是很大,就一个json文件的处理,和某班的查重比起来还是简单很多的。但是平时GitHub用的不多,因此相对比较困难的就是git使用的学习。同时之前没有定制过编码规范,因此如何制定编码规范也是本次作业的重点。
- 因为平时python用的比较多,所以第一个想到的就是要用python来写,同时刚开始写的时候打算先用单线程把基础功能写完,先让代码跑起来,之后再进行进一步优化来完善。
- 本次的代码任务主要可以分解为参数解析以及json文件的解析,关于参数解析之前写代码的时候有用到过,找到以前的笔记就能够实现了,json格式文件的解析,python的json库主要只有
json.dumps()和json.loads()两个方法,主要是将json文件和python对象相互转换。如何对json文件进行分析可以通过将json文件转换为字典对象之后利用get()方法来实现。目前来看涉及到的细节知识点都差不多了,接下来就是整体框架和编码了 - 刚开始还在疑惑如何经过一次初始化之后就能够不再输入文件的路径。看了一下实例代码发现是在初始化的时候生成另外的三个文件来用于以后的查询操作。思路也就清晰了起来
设计实现
-
主要是记录一下最初版本的思路,优化版本的思路主要放在下面的迭代优化环节
-
本次任务可以看到主要有三个操作,一个是参数解析,一个是初始化操作,另一个是查询操作。通过第一次的初始化操作来解析给出的json文件以生成另外三个用于接下来查询操作的文件
-
参数解析操作,对输入的参数进行解析,来进行相应的操作
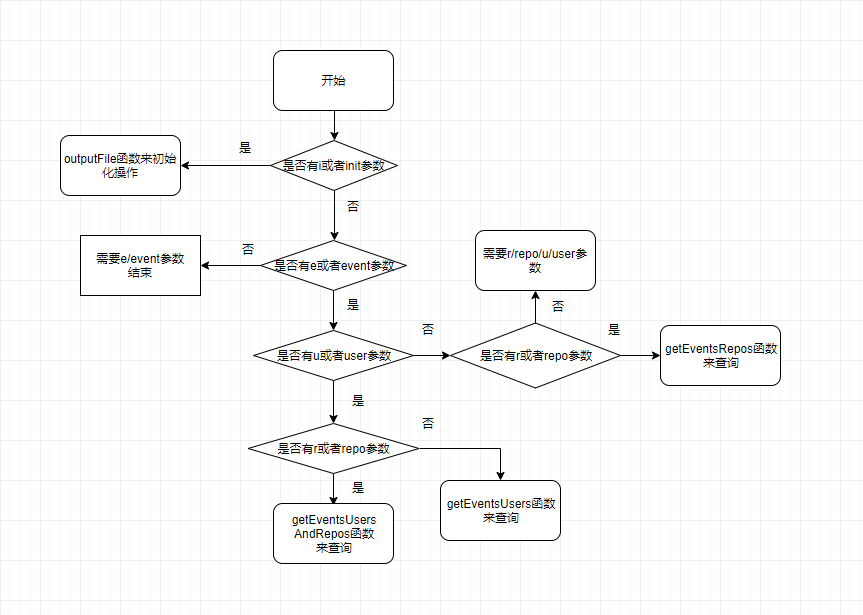
-
初始化操作就是对给出的json文件来提取出有效的内容然后输出三个用于查询文件
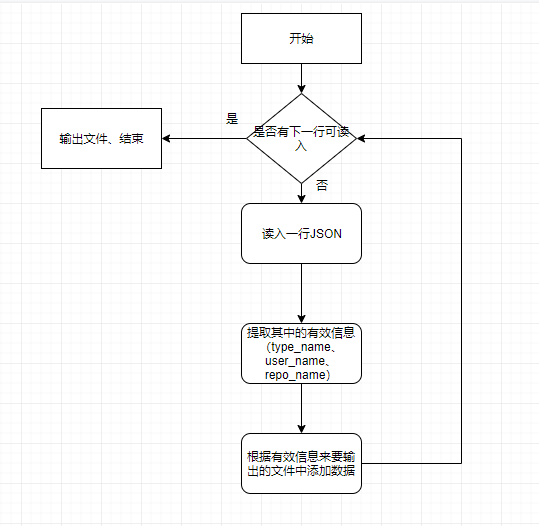
-
查询操作,通过初始化操作生成的文件,解析输出最后的结果,有
getEventsRepos()、getEventsUsers()、getEventsUsersAndRepos()三个函数
代码说明
-
outputFile函数(通过题目给出的json文件来生成另外三个用于查询的文件)
def outputFile(file_address): Users = {} Repos = {} UsersAndRepos = {} for root, dic, files in os.walk(file_address): for file in files: if(file[-5:] == '.json'): x = open(file_address + '\' + file, 'r', encoding = 'utf-8').read() for line in x.split(' '): if(len(line)>0): try: i = json.loads(line) EventType = i.get('type',0) EventUser = i.get('actor',0).get('login',0) EventRepo = i.get('repo',0).get('name',0) if(not Users.get(EventUser)): Users.update({EventUser: {}}) if(not Users[EventUser].get(EventType)): Users[EventUser].update({EventType: 0}) Users[EventUser][EventType] += 1 if(not Repos.get(EventRepo)): Repos.update({EventRepo: {}}) if(not Repos[EventRepo].get(EventType)): Repos[EventRepo].update({EventType: 0}) Repos[EventRepo][EventType] += 1 if(not UsersAndRepos.get(EventUser)): UsersAndRepos.update({EventUser: {}}) if(not UsersAndRepos[EventUser].get(EventRepo)): UsersAndRepos[EventUser].update({EventRepo: {}}) if(not UsersAndRepos[EventUser][EventRepo].get(EventType)): UsersAndRepos[EventUser][EventRepo].update({EventType: 0}) UsersAndRepos[EventUser][EventRepo][EventType] += 1 except: pass -
getEventsUsersAndRepos函数(用于查询每一个人在每一个项目的 4 种事件的数量)
def getEventsUsersAndRepos(user, repo, event): x = open('UsersAndRepos.json', 'r', encoding='utf-8').read() file = json.loads(x) if(not file.get(user,0)): print("0") elif(not file[user].get(repo)): print("0") else: print(file[user][repo].get(event,0)) -
analyse函数(用于刚开始的参数解析)
def analyse(self): if(self.parser.parse_args().init): for root, dic, files in os.walk(self.parser.parse_args().init): for file in files: if(file[-5:] == '.json'): print(root + '\' + file) self.num += 1 t = threading.Thread(target=outputFile, args=(root + '\' + file, self.num)) t.start() return 0 else: if(self.parser.parse_args().event): if(self.parser.parse_args().user): if(self.parser.parse_args().repo): getEventsUsersAndRepos( self.parser.parse_args().user, self.parser.parse_args().repo, self.parser.parse_args().event) else: getEventsUsers( self.parser.parse_args().user, self.parser.parse_args().event) elif(self.parser.parse_args().repo): getEventsRepos( self.parser.parse_args().repo, self.parser.parse_args().event) else: print('ERROR: argument -l or -c are required') return 0 else: print('ERROR: argument -e is required') return 0
迭代优化
初版(单线程版)
-
代码
def outputFile(file_address): Users = {} Repos = {} UsersAndRepos = {} json_list = [] for root, dic, files in os.walk(file_address): for file in files: if(file[-5:] == '.json'): x = open(file_address + '\' + file, 'r', encoding = 'utf-8').read() for line in x.split(' '): if(len(line)>0): try: json_list.append(json.loads(line)) except: pass for i in json_list: EventType = i.get('type',0) EventUser = i.get('actor',0).get('login',0) EventRepo = i.get('repo',0).get('name',0) if(not Users.get(EventUser)): Users.update({EventUser: {}}) if(not Users[EventUser].get(EventType)): Users[EventUser].update({EventType: 0}) Users[EventUser][EventType] += 1 if(not Repos.get(EventRepo)): Repos.update({EventRepo: {}}) if(not Repos[EventRepo].get(EventType)): Repos[EventRepo].update({EventType: 0}) Repos[EventRepo][EventType] += 1 if(not UsersAndRepos.get(EventUser)): UsersAndRepos.update({EventUser: {}}) if(not UsersAndRepos[EventUser].get(EventRepo)): UsersAndRepos[EventUser].update({EventRepo: {}}) if(not UsersAndRepos[EventUser][EventRepo].get(EventType)): UsersAndRepos[EventUser][EventRepo].update({EventType: 0}) UsersAndRepos[EventUser][EventRepo][EventType] += 1 with open('Users.json', 'w', encoding='utf-8') as f: json.dump(Users,f) with open('Repos.json', 'w', encoding='utf-8') as f: json.dump(Repos,f) with open('UsersAndRepos.json', 'w', encoding='utf-8') as f: json.dump(UsersAndRepos,f) -
和助教的示例代码整体框架差不多
-
为了实现任务的初版,没有对其它因素(时间、内存占用等)进行过多的考虑
-
单线程,速度较慢,同时在跑的时候直接把所有文件存放到内存中,如果给出的数据较小还能够完成,但是一旦给出的数据大一些,就会导致内存放不下->“MEMORY ERROR”
二版(多线程版)
-
代码
import json import os import argparse import threading s1=threading.Semaphore(20) def outputFile(file_address, num): s1.acquire() Users = {} Repos = {} UsersAndRepos = {} json_list = [] x = open(file_address, 'r', encoding = 'utf-8').read() for line in x.split(' '): if(len(line)>0): try: json_list.append(json.loads(line)) except: pass for i in json_list: EventType = i.get('type',0) EventUser = i.get('actor',0).get('login',0) EventRepo = i.get('repo',0).get('name',0) if(not Users.get(EventUser)): Users.update({EventUser: {}}) if(not Users[EventUser].get(EventType)): Users[EventUser].update({EventType: 0}) Users[EventUser][EventType] += 1 if(not Repos.get(EventRepo)): Repos.update({EventRepo: {}}) if(not Repos[EventRepo].get(EventType)): Repos[EventRepo].update({EventType: 0}) Repos[EventRepo][EventType] += 1 if(not UsersAndRepos.get(EventUser)): UsersAndRepos.update({EventUser: {}}) if(not UsersAndRepos[EventUser].get(EventRepo)): UsersAndRepos[EventUser].update({EventRepo: {}}) if(not UsersAndRepos[EventUser][EventRepo].get(EventType)): UsersAndRepos[EventUser][EventRepo].update({EventType: 0}) UsersAndRepos[EventUser][EventRepo][EventType] += 1 with open('.\output\' + 'Users_' + str(num) + '.json', 'w', encoding='utf-8') as f: json.dump(Users,f) f.close() with open('.\output\' + 'Repos_' + str(num) + '.json', 'w', encoding='utf-8') as f: json.dump(Repos,f) f.close() with open('.\output\' + 'UsersAndRepos_' + str(num) + '.json', 'w', encoding='utf-8') as f: json.dump(UsersAndRepos,f) f.close() Users = {} Repos = {} UsersAndRepos = {} now_time2 = datetime.datetime.now() print(now_time2 - now_time1) s1.release() def getEventsUsersAndRepos(user, repo, event): file_address = '.\output' num = 0 for root, dic, files in os.walk(file_address): for file in files: if(file[0:14] == 'UsersAndRepos_'): x = open(root + '\' + file, 'r', encoding='utf-8').read() f = json.loads(x) try: num += f[user][repo].get(event,0) except: pass print(num) now_time2 = datetime.datetime.now() print(now_time2 - now_time1) if(self.parser.parse_args().init): for root, dic, files in os.walk(self.parser.parse_args().init): for file in files: if(file[-5:] == '.json'): print(root + '\' + file) self.num += 1 t = threading.Thread(target=outputFile, args=(root + '\' + file, self.num)) t.start() return 0 -
和初版比较,采用了多线程,总体框架还是没有怎么变
-
但是就内存占用来说,不会将所有内容全都读入到内存中,就不会出现类似于单线程直接内存炸掉的情况(但是如果给出的是单单一个大文件,会导致只能开启一个线程,和单线程一样炸裂)
-
对于每一个给出的文件开启一个线程,限制最高线程数为20。
-
因为是对于每一个给出的文件开一个线程,所以如果给出的文件只有一个的时候就只能够以单线程的速度来完成
-
每一个线程都输出三个文件,导致接下来的查询操作时需要从生成的众多文件中来计算出总数,导致每一次查询操作都要耗费4-15秒左右的时间。
-
虽然比起第一版,能够跑比较大的数据了,尝试跑了7.79G的数据,跑了十五分钟左右出来了,但是仍然会造成内存的大量占用,造成不必要的浪费
-
接下来的改版优化将对于第2和第5点进行优化
三版(单线程版)
-
代码
def outputFile(file_address): Users = {} Repos = {} UsersAndRepos = {} for root, dic, files in os.walk(file_address): for file in files: if(file[-5:] == '.json'): x = open(file_address + '\' + file, 'r', encoding = 'utf-8').read() for line in x.split(' '): if(len(line)>0): try: i = json.loads(line) EventType = i.get('type',0) EventUser = i.get('actor',0).get('login',0) EventRepo = i.get('repo',0).get('name',0) if(not Users.get(EventUser)): Users.update({EventUser: {}}) if(not Users[EventUser].get(EventType)): Users[EventUser].update({EventType: 0}) Users[EventUser][EventType] += 1 if(not Repos.get(EventRepo)): Repos.update({EventRepo: {}}) if(not Repos[EventRepo].get(EventType)): Repos[EventRepo].update({EventType: 0}) Repos[EventRepo][EventType] += 1 if(not UsersAndRepos.get(EventUser)): UsersAndRepos.update({EventUser: {}}) if(not UsersAndRepos[EventUser].get(EventRepo)): UsersAndRepos[EventUser].update({EventRepo: {}}) if(not UsersAndRepos[EventUser][EventRepo].get(EventType)): UsersAndRepos[EventUser][EventRepo].update({EventType: 0}) UsersAndRepos[EventUser][EventRepo][EventType] += 1 except: pass -
重回单线程版
-
半夜睡不着突然想起之前为什么要把所有文件读到内存中,仿佛一个憨憨。早上起来改成一行一行的读,不会占用内存
-
跑7.79G的文件大概跑了三分钟多,同时内存占用维持在几百M左右。总体性能和开销都不错
-
同时也写了改进后的多线程版本,发现速度仅仅提高了几秒,想到可能主要性能瓶颈在于IO接口处,采用多线程用处不大,于是仍然采用单线程版
-
目前还没有想到有什么其它的优化方法,暂时优化到这一版
单元测试
- 正确率(100%)
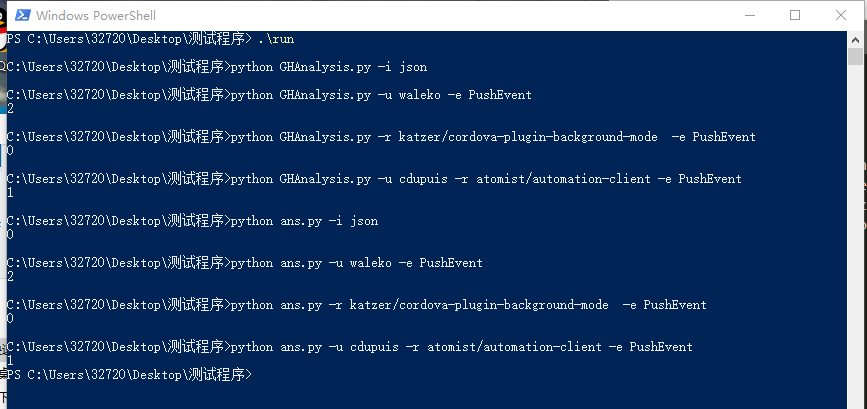
其中上半部分的GHAnalysis.py为我写的代码,下半部分ans.py为示例代码
- 代码覆盖率
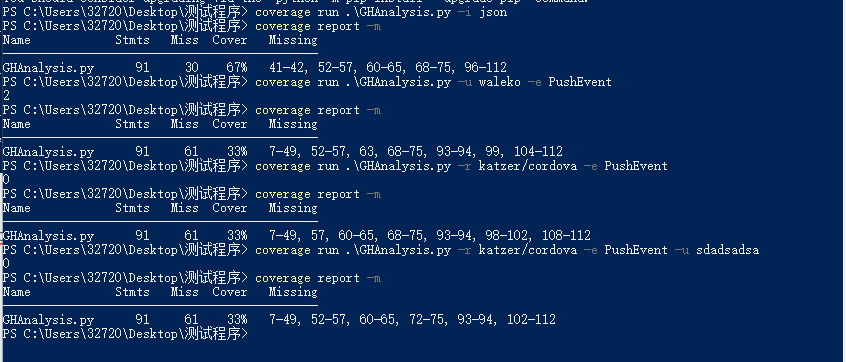
可以看到代码覆盖率比较低,接下来准备再进行一些改进
代码规范
https://github.com/m1nme/2020-personal-python/blob/2020-personal-python/README.md
总结
-
代码难度其实并不大,我大部分时间都花在了别的内容上
-
遇到的困难
1. 没有想到更好的优化方案 2. git的用法 3. 没有过代码覆盖率的概念,代码覆盖率较低,不知道如何提高 -
学到的东西
1. 学习了一些github的用法 2. 希望以后能让git成为一种习惯 3. 了解了代码覆盖率的概念