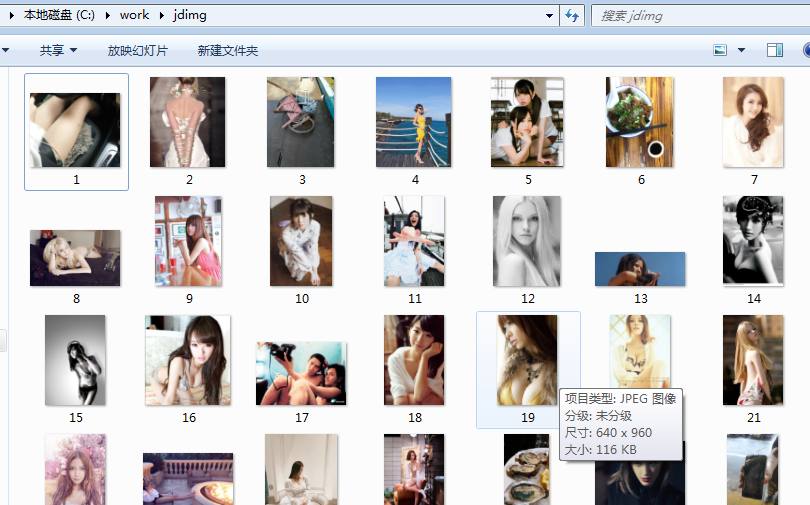
这里爬取的目标为jiandan网上的用户分享的随手拍的图片,链接为:http://jandan.net/ooxx
首先,经分析后发现该板块的图片是异步加载的,通过requests库难以获取。因此,利用selenium动态获取目标内容的源代码,再用BeautifulSoup库解析保存即可。
1、首先打开目标链接,煎蛋分析下网站,然后决定用什么方式去获取内容
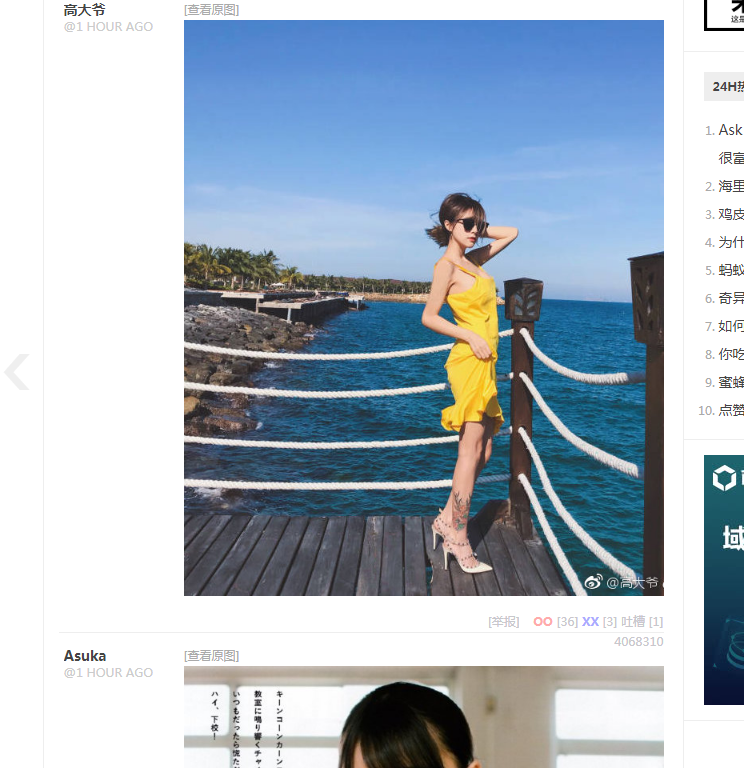
禁止加载JavaScript后,图片则无法显示,并且在XHR里面没有任何内容
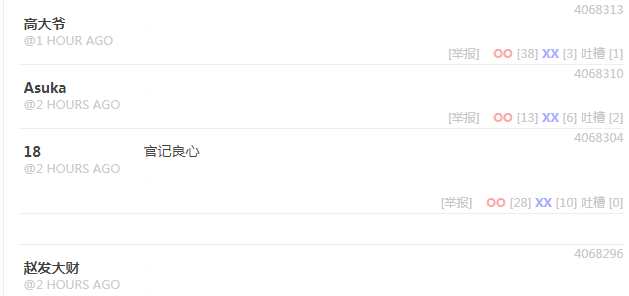
基于此,我们发现,该板块内容只有图片是异步加载 的,但图片又是我们想要爬取的,这时用requests库去获取内容的话会比较困难,因此,我们可以用selenium库来获取目标内容。
2.selenium简单入门
1)什么是selenium
Selenium 是一个用于浏览器自动化测试的框架,可以用来爬取任何网页上看到的数据。
2)selenium的下载和安装
在终端输入pip install selenium ——> 下载Chromdriver,解压后放在…GoogleChromeApplication ——> 将该目录添加至环境变量
3)使用代码测试
from selenium import webdriver #导入包
driver = webdriver.Chrome() #打开Chrome浏览器
driver.get('http://www.baidu.com') #输入url,打开百度首页
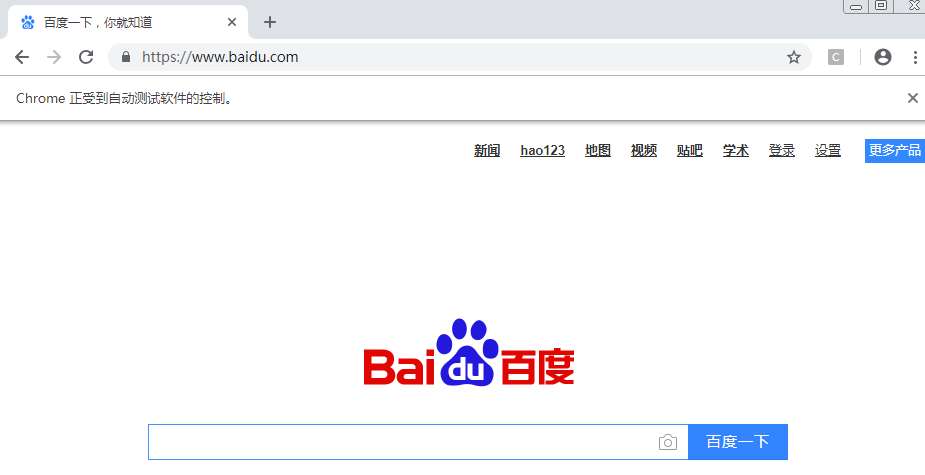
如上所示,这段代码可以自动打开百度首页,说明OK
3、开始爬取图片
1 # 导入必要的包
2 from selenium import webdriver
3 from bs4 import BeautifulSoup
4 import requests
5
6 # 打开谷歌浏览器
7 driver = webdriver.Chrome()
8 # 输入url,打开煎蛋网首页
9 driver.get('http://jandan.net')
10 # 初始化一个引用计数,用于后面的图片简单命名
11 index = 1
12
13 # 定义爬虫方法
14 def getImage(link_texts):
15 # 将index置为全局变量
16 global index
17 # 通过点击的动作执行翻页
18 for i in link_texts:
19 # 模拟点击
20 driver.find_element_by_link_text(i).click()
21 # 解析网页
22 html = BeautifulSoup(driver.page_source, 'html.parser')
23 # 获取原图的url链接
24 links = html.find_all('a', {'class': 'view_img_link'})
25 # 遍历当页获得的所有原图链接
26 for link in links:
27 # 将原图存至当前目录下的jdimg 文件夹,以index命名,后缀名为图片原名的后三位,即jpg或者gif
28 with open('jdimg/{}.{}'.format(index, link.get('href')[len(link.get('href'))-3: len(link.get('href'))]), 'wb') as jpg:
29 jpg.write(requests.get("http:" + link.get('href')).content)
30 print("正在爬取第%s张图片" % index)
31 index += 1
32 # 定义主函数
33 def main():
34 # 将准备执行的浏览或翻页动作的关键字存入数组
35 link_texts = [u'随手拍', u'下一页', u'下一页', u'下一页', u'下一页']
36 #开始爬取
37 getImage(link_texts)
38
39 main()
执行后:

打开文件夹jdimg后,可以看到,图片爬取成功: